C和C++中的volatile、内存屏障和CPU缓存一致性协议MESI
目录
1. 前言 2
2. 结论 2
3. volatile应用场景 3
4. 内存屏障(Memory Barrier) 4
5. setjmp和longjmp 4
1) 结果1(非优化编译:g++ -g -o x x.cpp -O0) 5
2) 结果2(优化编译:g++ -g -o x x.cpp -O2) 6
6. 不同CPU架构的一致性模型 6
7. x86-TSO 7
8. C++标准库对内存顺的支持 7
1) 头文件
2) 头文件
附1:CPU、缓存和主存 8
第三级缓存(L3 Cache)多核共享: 8
附2:SMP对称多处理器结构 9
附3:在线C++编译器 9
附4:资源链接 10
1) C++标准委员会(The C++ Standards Committee) 10
2) 标准C++基金会 10
3) C++之父 10
4) Linux内核关于volatile的说明 10
5) Intel内存模型(Intel Memory Model) 10
6) Intel TSO内存模型 10
7) Sequential Consistency &TSO 10
8) Write buffer 10
9) x86-64和IA-32开发手册 10
10) 编译器屏障(Compiler Barriers) 10
11) C ++ 11中memory_order_consume的作用 10
12) MESI(多核CPU缓存一致性协议) 10
13) MESIF(多核CPU缓存一致性协议) 10
- 前言
本文内容主要针对Linux,而且主要是x86环境。先看一常见用法:
| class Thread { public: X() : _stop(false) { }
void stop() { _stop = true; }
void run() { while (!_stop) { work(); } }
private: volatile bool _stop; }; |
然后看看标准C++基金会(https://isocpp.org)怎么说的(官方链接):
 结论
结论
- 与平台无关的多线程程序,volatile几乎无用(Java和C#中的volatile除外);
- volatile不保证原子性(一般需使用CPU提供的LOCK指令);
- volatile不保证执行顺序;
- volatile不提供内存屏障(Memory Barrier)和内存栅栏(Memory Fence);
- 多核环境中内存的可见性和CPU执行顺序不能通过volatile来保障,而是依赖于CPU内存屏障。
注:volatile诞生于单CPU核心时代,为保持兼容,一直只是针对编译器的,对CPU无影响。
volatile在C/C++中的作用:
- 告诉编译器不要将定义的变量优化掉;
- 告诉编译器总是从缓存取被修饰的变量的值,而不是寄存器取值。
就前言中的代码,可移植的实现方式为:
| #include <atomic>
class Thread { public: X() : _stop(false) { }
void stop() { _stop = true; }
void run() { while (!_stop) { work(); } }
private: std::atomic<bool> _stop; }; |
不过这要求至少C++11,否则可使用兼容C++98的实现CAtomic
https://github.com/eyjian/libmooon/blob/master/include/mooon/sys/atomic.h,实际上Linux内核源代码都带有这些基础设施。
- volatile应用场景
- 信号处理程序;
- 与硬件打交道(嵌入式开发用得多);
- 和setjmp、longjmp配合(请参见:http://www.cplusplus.com/reference/csetjmp/setjmp/),原因同信号处理。
- 内存屏障(Memory Barrier)
内存屏障,也叫内存栅栏(Memory Fence)。分编译器屏障(Compiler Barrier,也叫优化屏障)和CPU内存屏障,其中编译器屏障只对编译器有效,它们的定义如下表所示(限x86,其它架构并不相同):
| #define barrier() \ __asm__ __volatile__("":::"memory") |
编译器屏障,如果是GCC,则可用__sync_synchronize()替代 |
| #define mb() \ __asm__ __volatile__("mfence":::"memory") |
CPU内存屏障,还分读写内存屏障 |
| #define rmb() \ __asm__ __volatile__("lfence":::"memory") |
CPU读(Load)内存屏障 |
| #define wmb() \ __asm__ __volatile__("sfence":::"memory") |
CPU写(Store)内存屏障 |
x86架构的CPU内存屏障代码可在内核源代码的arch/x86/include/asm/barrier.h中找到。对于原子操作,需要使用CPU提供的“lock”指令,对于CPU乱序需使用CPU内存屏障。
| 代码顺序 |
编译器顺序 |
CPU顺序 |
| a=1; b=x; c=z; d=2; |
a=1; d=2; b=x; c=z; |
b=x; c=z; a=1; d=2; |
推荐资料:
https://mariadb.org/wp-content/uploads/2017/11/2017-11-Memory-barriers.pdf
内存屏障进一步还分读内存屏障和写内存屏障等,对非内核开发者来说,内存屏障的主要应用场景为无锁编程(Lock-free),因为像pthread_mutx_t等实际已经包含了“Lock”和“Memory Barrier”,所以无需再操心。
- setjmp和longjmp
在C/C++中,goto关键词只能函数内的局部跳转,函数间的跳转需要使用setjmp和longjmp,这也是有些协程库基于setjmp和longjmp实现的原因。
- setjmp
保存上下文,包括信号掩码,类似于setcontext。该函数的返回值比较特别,第一次返回0,第二次返回的longjmp第二个参数值(如果longjmp第二个参数值为0,则返回值为1,这样方便区分于第一次返回)。
- longjmp
该函数从不返回,而是跳回到setjmp保存点,类似于swapcontext。如果没有先调用setjmp,则longjmp的行为是未定义的。C++代码可能还会执行栈展开(Unwinding),如果调用了任何非平凡析构函数(non-trivial destructors,需显示处理的析构函数,如内存释放),也会导致未定义的行为。
- 代码示例(摘自http://www.cplusplus.com/reference/csetjmp/setjmp/)
| /* x.cpp */ /* setjmp example: error handling */ #include #include #include
struct X { X() { fprintf(stderr, "X::ctor\n"); } ~X() { fprintf(stderr, "X::dtor\n"); } };
int main() { jmp_buf env; int val = -1; int m = -1; volatile int n = -1; X x;
val = setjmp(env); fprintf(stderr, "setjmp return: %d\n", val); if (val) { fprintf(stderr, "m: %d\n", m); fprintf(stderr, "n: %d\n", n); exit(val); } else { m = 2018; n = 2018;
/* code here */ longjmp(env, 19); /* signaling an error */ return 0; } } |
上例代码运行有两种输出结果:
- 结果1(非优化编译:g++ -g -o x x.cpp -O0)
| X::ctor setjmp return: 0 setjmp return: 19 m: 2018 n: 2018 |
非优先编译时,总是从内存取值。
- 结果2(优化编译:g++ -g -o x x.cpp -O2)
| X::ctor setjmp return: 0 setjmp return: 19 m: -1 n: 2018 |
因m未加volatile修饰,直接读取寄存器值,因此结果是-1。从这里也可以看出,即使是单线程程序,volatile也是必要的,也说明volatile并不是完全没用,只是它不能帮助解决多线程的原子性、内存屏障和CPU乱序执行。
另外可发现,上列代码的类X的析构未执行,但若将exit改成return,则会执行类X的析构,遇到“}”和“return”时,编译器会安插析构函数调用。
- 不同CPU架构的一致性模型
注:LOAD为读操作,STORE为写操作。
|
|
Loads reordered after loads |
Loads reordered after stores |
Stores reordered after stores |
Stores reordered after loads |
Atomic reordered with loads |
Atomic reordered with stores |
Dependent loads reordered |
Incoherent instruction cache pipeline |
| Alpha |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
| ARMv7 |
Y |
Y |
Y |
Y |
Y |
Y |
|
Y |
| PA-RISC |
Y |
Y |
Y |
Y |
|
|
|
|
| POWER |
Y |
Y |
Y |
Y |
Y |
Y |
|
Y |
| SPARC RMO |
Y |
Y |
Y |
Y |
Y |
Y |
|
Y |
| SPARC PSO |
|
|
Y |
Y |
|
Y |
|
Y |
| SPARC TSO |
|
|
Y |
|
|
|
|
Y |
| x86 |
|
|
Y |
|
|
|
|
Y |
| x86 oostore |
Y |
Y |
Y |
Y |
|
|
|
Y |
| AMD64 |
|
|
|
Y |
|
|
|
|
| IA-64 |
Y |
Y |
Y |
Y |
Y |
Y |
|
Y |
| z/Architecture |
|
|
|
Y |
|
|
|
|
四种SMP架构的CPU内存一致性模型:
- 顺序一致性模型(SC,Sequential Consistency,所有读取和所有写入都是有序的);
- 宽松一致性模型(RC,Relaxed Consistency,允许某些可以重排序),ARM和POWER属于这类;
- 弱一致性模型(WC,Weak Consistency,读取和写入任意重新排序,仅受显式内存屏障限制);
- 完全存储排序(TSO,Total Store Ordering),SPARC和x86属于这种类型,只有“store load”一种情况会发生重排序,其它情况和SC模型一样。
- x86-TSO
x86-TSO是Intel推出的一种CPU内存一致性模型,特点是只有“Store Load”一种情况会重排序,也就是“Load”可以排(乱序)在“Store”的前面,因此不需要“Load Load”、“Store Store”和“Load Store”这三种屏障。
- “Store Load”屏障的作用是:确保“前者刷入内存”的数据对“后者加载数据”是可见的;
- “Load Load”屏障的作用是:确保“前者装载数据”先于“后者装载指令”;
- “Store Store”屏障的作用是:确保“前者数据”先于“后者数据”刷入内存,且“前者刷入内存的数据”对“后者是可见的”;
- “Load Store”屏障的作用是:确保“前者装载数据”先于“后者刷新数据到内存”。

- C++标准库对内存顺的支持
- 头文件
| enum memory_order { memory_order_relaxed, // 宽松一致性模型,不对执行顺序做任何保证 memory_order_consume, // (读操作)本线程所有后续有关本操作的必须在本操作完成后执行 memory_order_acquire, // (读操作)本线程所有后续的读操作必须在本条操作完成才能执行 memory_order_release, // (写操作)本线程所有之前的写操作完成后才执行本操作 memory_order_acq_rel, // (读-修改-写)同时包含Acquire和Release memory_order_seq_cst // (读-修改-写,默认类型)顺序一致性模型,全部顺序执行 }; |
- 头文件
| // 默认内存顺类型为“memory_order_seq_cst” std::atomic std::atomic std::atomic 。。。。。。 |
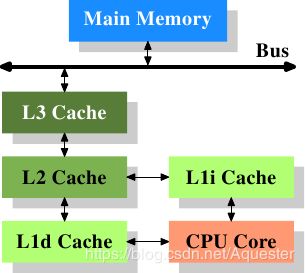
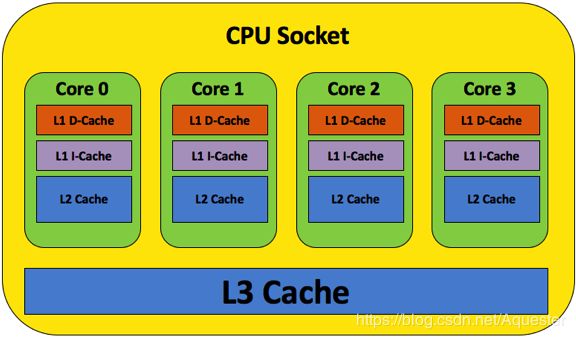
附1:CPU、缓存和主存
第三级缓存(L3 Cache)多核共享:
附2:SMP对称多处理器结构
多个CPU对称工作没有区别,无主次或从属关系,平等地访问内存、外设和一个操作系统,共享全部资源,如总线、内存和I/O系统等,因此也被称为一致存储器访问结构(UMA : Uniform Memory Access)。
其它的架构有:
- NUMA(Non-Uniform Memory Access,非统一内存访问),基本特征是将CPU分成多个模型,每个模型多个CPU组成,具有独立的本地内存和I/O槽口等;
- MPP(Massive Parallel Processing,海量并行处理结构),基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构。

附3:在线C++编译器
- https://www.tutorialspoint.com/compile_cpp_online.php
- https://www.jdoodlecom/online-compiler-c++
- http://coliru.stacked-crooked.com/
- https://www.onlinegdb.com/online_c++_compiler
- https://ideone.com/
- http://cpp.sh/
- https://www.cppbuzz.com/compiler/online-c++-compiler
- https://www.codechef.com/ide/
- https://repl.it/repls/ZestyNaturalMatch
- https://www.codiva.io
- http://codepad.org/
- https://cppinsights.io/
- https://tio.run/#cpp-gcc
- http://www.compileonline.com/
聚合了各种语言在线编译。
- https://rextester.com/l/cpp_online_compiler_gcc
还支持其它众多语言在线编译。
附4:资源链接
- C++标准委员会(The C++ Standards Committee)
http://www.open-std.org/jtc1/sc22/wg21/
- 标准C++基金会
https://isocpp.org
- C++之父
http://www.stroustrup.com/
- Linux内核关于volatile的说明
https://www.kernel.org/doc/html/latest/process/volatile-considered-harmful.html
- Intel内存模型(Intel Memory Model)
https://en.wikipedia.org/wiki/Intel_Memory_Model
- Intel TSO内存模型
https://www.cl.cam.ac.uk/~pes20/weakmemory/x86tso-paper.tphols.pdf(A Better x86 Memory Model: x86-TSO)
http://homepages.inf.ed.ac.uk/vnagaraj/papers/hpca14.pdf(TSO-CC: Consistency directed cache coherence for TSO)
- Sequential Consistency &TSO
https://www.cis.upenn.edu/~devietti/classes/cis601-spring2016/sc_tso.pdf
- Write buffer
https://en.wikipedia.org/wiki/Write_buffer
- x86-64和IA-32开发手册
https://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.html(IA-32:Intel Architecture 32-bit,即32位x86)
- 编译器屏障(Compiler Barriers)
https://www.oracle.com/technetwork/server-storage/solarisstudio/documentation/oss-compiler-barriers-176055.pdf
- C ++ 11中memory_order_consume的作用
https://preshing.com/20140709/the-purpose-of-memory_order_consume-in-cpp11/
- MESI(多核CPU缓存一致性协议)
https://en.wikipedia.org/wiki/MESI_protocol
- MESIF(多核CPU缓存一致性协议)
https://en.wikipedia.org/wiki/MESIF_protocol
| M 修改(Modified) |
该Cache line(缓存行)有效,数据被修改(dirty)了,和主存中的数据不一致,数据只存在于本Cache中 |
| E 独占互斥(Exclusive) |
该Cache line只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致 |
| S 共享(Shared) |
该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中 |
| I 无效(Invalid) |
该Cache line无效,可能有其它CPU修改了该Cache line |
| F 转发(Forward) |
Intel提出来的,意思是一个CPU修改数据后,直接针修改的结果转发给其它CPU |