hadoop-HA高可用集群部署
HA 高可用集群部署
节点设置,4个虚拟机,且完成SSH免密钥登陆,jdk安装
| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | |
|---|---|---|---|---|---|---|
| bd001 | * | * | * | |||
| bd002 | * | * | * | * | * | |
| bd003 | * | * | * | |||
| bd004 | * | * |
Active NameNode : 一个集群只有一个Active,接受客户端的读写请求,记录edits日志(元数据)。
StandbyNameNode : 一个集群中可能有多个Standby。合并edits和fsimage文件,从而更新fsimage。等待 ActiveNameNode的死亡。
JournalNode: 共享edits日志文件。当ANN写入一条日志的同时,往JournalNode集群中也写入一条。当它接受一条日志,同时通知StandbyNamenode获取。
DataNode: 保存和管理block。并且往两种NameNode同时汇报block的位置信息。
Zookeeper: 它是负责选举算法。选举一个Namenode的状态为Active。同时记录每个Namenode的运行信息。
ZKFC: 监控各自的NameNode(每一个NameNode一定有一个与之对应的ZKFC)。负责NameNode的状态切换。借助ssh服务来切换NameNode的状态(一定要配置SSH服务的免密钥)。
zookeeper集群
配置环境变量
export HADOOP_HOME=/opt/hadoop-2.6.5
export ZOOKEEPER_HOME=/opt/zkServ
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
修改配置文件
1.配置zoo.cfg
cd /opt/zkServ/conf
复制文件
cp zoo_sample.cfg ./zoo.cfg
配置文件
vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/zk_data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=192.168.200.22:2888:3888
server.2=192.168.200.23:2888:3888
server.3=192.168.200.24:2888:3888
2.配置myid
mkdir /opt/zk_data
创建myid文件
写入server.1 对应的数字
例如
1
3.分发
scp -r zkServ/ bd004:/opt/
find / -name zkServ
分别配置环境变量
4.zk启动测试
zkServer.sh start
配置hadoop
hdfs-site.xml
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>node01:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>node02:8020value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>node01:50070value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>node02:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node01:8485;node02:8485;node03:8485/myclustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/var/sxt/hadoop/ha/jnvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
value>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_dsavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node02:2181,node03:2181,node04:2181value>
property>
修改slaves
bd002
bd003
bd004
配置节点1、2的免密钥
#对自己免密钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat id_dsa.pub >> authorized_keys
#分发
scp id_dsa.pub bd002:`pwd`/bd001.pub
#追加
cat bd001.pub >> authorized_keys
分发hadoop
1-->2,3,4
scp -r hadoop-HA/ bd002:/opt/
1.启动JNN(节点1,2,3)
hadoop-daemon.sh start journalnode
2.格式化(节点1)
hdfs namenode -format
启动(节点1),
hadoop-daemon.sh start namenode
3.bd002格式化
hdfs namenode -bootstrapStandby
4.格式化zk(节点1)
hdfs zkfc -formatZK
5.节点1启动
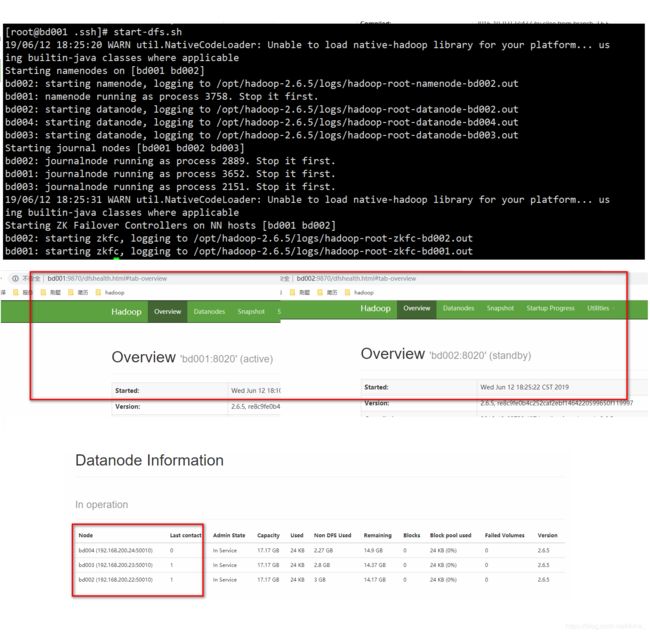
start-dfs.sh
启动成功
[root@bd001 .ssh]# start-dfs.sh
19/06/12 18:25:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [bd001 bd002]
bd002: starting namenode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-namenode-bd002.out
bd001: namenode running as process 3758. Stop it first.
bd002: starting datanode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-datanode-bd002.out
bd004: starting datanode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-datanode-bd004.out
bd003: starting datanode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-datanode-bd003.out
Starting journal nodes [bd001 bd002 bd003]
bd002: journalnode running as process 2889. Stop it first.
bd001: journalnode running as process 3652. Stop it first.
bd003: journalnode running as process 2151. Stop it first.
19/06/12 18:25:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting ZK Failover Controllers on NN hosts [bd001 bd002]
bd002: starting zkfc, logging to /opt/hadoop-2.6.5/logs/hadoop-root-zkfc-bd002.out
bd001: starting zkfc, logging to /opt/hadoop-2.6.5/logs/hadoop-root-zkfc-bd001.out