GraphLab Create API(中文文档)-deeplearning
1. graphlab.deeplearning.create(dataset, target, features= None, network_type='auto')
NeuralNet对象由deeplearning.create()得到,返回的网络可以被graphlab.neuralnet_classifier.create()用来训练NeuralNetClassifier。
一般工作流程分为三步:
- 使用graphlab.deeplearning.create()创建神经网络;
- 调整神经网络参数,让其适用于目标任务;
- 用给定的网络架构和超参数,通过graphlab.neuralnet_classifier.create()产生的网络训练NeuralNetClassifier。
当数据包含图像列额,返回一个ConvolutionNet,否则返回一个MultiLayerPerceptrons
参数:
dataset: SFrame 要为其创建神经网络的数据库
target: str 预测目标列名称
features: list[str] (可选) 使用features的列名训练模型。每列必须包含floats向量或者有一列是Image类型。默认为None(使用除了target列的全部列)
network_type: str, {‘auto’, ‘perceptrons’, ‘convolution’} (可选)确定创建的网络类型。默认自动为给图片输入创建ConvolutionNet,给常规的数值输入创建MultiLayerPerceptrons
返回:NeuralNet
注意:返回的神经网络可能是此优的,用作训练的初始开始点
例子:

https://turi.com/products/create/docs/generated/graphlab.deeplearning.create.html#graphlab.deeplearning.create
2. graphlab.neuralnet_classifier.create(dataset, target, features=None, max_iterations=10, network=None, validation_set='auto', verbose=True, class_weights=None, **kwargs)
创建一个NeuralNetClassifier,用数字特征或者图像数据特征预测数据的类。
可选参数network接受一个NeuralNet对象,这个NeuralNet对象定义神经网络构架和学习参数。在模型学习过程中,这是最重要的参数。推荐开始时使用deeplearning.create()返回的默认构架,然后调整构架,使其最适于你的目标任务。
多GPU支持
神经网络分类器的创建利用多GPU设备的优势。默认的,它使用能够发现的所有GPU。你可以通过设置运行时间配置“GRAPHLAB_NEURALNET_DEFAULT_GPU_DEVICE_ID”改变默认行为。比如:下面的代码将默认改为只使用0和2两台设备
graphlab.set_runtime_config("GRAPHLAB_NEURALNET_DEFAULT_GPU_DEVICE_ID", "0,2")注意:
如果GPU之间存在不平衡,也就是其中有一个GPU比其他的慢,那么更快一点的GPU最终会等待较慢的GPU
参数:
- dataset: SFrame
一个训练数据集,包含特征列和目标列。如果特征列类型为graphlab.Image,那么所有的图片必须是相同的尺寸。 - target: str
dataset中列名为预测目标。这列中的值代表类别,必须是整数或者字符串。 - features:list[str](可选)
特征列名常用来训练模型。每列必须包含floats向量或者有一列为Image类型。默认为None,表示所有的列都被使用(除了target列)。 - max_iterations:int(可选)
最大迭代次数 - network:NeuralNet(可选)
NeuralNet对象包含模型学习参数和对网络构架的定义。默认为None,但是推荐使用deeplearning.create()给输入数据找到一个默认结构,但是这个默认的结构不是最优的,所以强烈建议调整NeuralNet。 - validation_set:SFrame(可选)
用于监视模型泛化性能的数据集。对于进度表的每一行,为所提供的训练数据集和validation_set计算所选择的度量。这个SFrame的格式必须与训练数据集相同。这个参数默认设置为‘auto’,自动地对验证集采样并用于进程打印。如果validation_set被设置为None,那么不会计算其他度量。每次完全迭代只计算一次,默认值为‘auto’。 - class_weights:{dict,‘auto’}(可选)
根据给定的类权重给训练数据样例加权重。如果设置为None,所有类会平均权重。‘auto’模式设置类权重为与训练数据中给定类别的数字样例成反比例。如果提供自定义类权重,那么所有的类都必须出现在字典中。 - kwargs:dict(可选)
训练神经网络的另一个参数。下列所有的参数都可以存储在一个神经网络对象的params属性中。如果在两个地方设置了相同的参数,那么在创建函数中的参数将重写在神经网络对象中的参数。
- batch_size:int 默认为100
SGD迷你批量尺寸。更大的batch_size会提升每次迭代的速度,但是会耗费更多GPU或CPU内存。 - model_checkpoint_path:str 默认“”
如果被指定,则每n次迭代保存模型到给定的路径,n由model_checkpoint_interval指定。 - model_checkpoint_interval:int 默认为5
如果model_checkpoint_path被指定,每n次迭代保存模型到给定的路径。 - mean_image:graphlab.image.Image 默认为None
如果设置该参数并且subtract_mean为True,则用给定的图像来节省计算时间。 - metric: {‘accuracy’, ‘error’, ‘recall@5’, …} 默认为auto
metric用来评估训练数据和验证数据。为了在多种标准上进行评估,提供一列评估字符串,例如{‘accuracy’,‘recall@5’},或者用一个逗号分隔开,例如‘accuracy,recall@5’。 - subtract_mean:bool 默认为True
如果为True,则每张图像减掉平均值。计算训练数据计算平均值图像或者用给定的mean_image计算。减掉平均值集中输入数据有助于加速神经网络训练。 - random_crop:bool 默认False
如果为True,对输入图像随机剪裁。被剪裁的图片尺寸由input_shap参数定义。随机剪裁通过扩张数据库防止模型过拟合。 - input_shape:str 默认为None
以通道,宽度,高度为格式的字符串,例如:“1,28,28”或者“3,256,256”,表明随机剪裁后的图像形状。input_shape不能超出原始图片尺寸大小。 - random_mirror:bool 默认为False
如果为True,将随机镜像应用到输入图像上。随机镜像通过扩张数据库防止模型过拟合。 - learning_rate:float 默认为0.001
偏置和权重的学习率。 - momentum: float (0~1之间)默认为0.9
偏置和权重的动量。 - l2_regularization:float 默认为0.0005
权重的L2正则化。 - bias_learning_rate:float 默认为不使用
指定偏置的学习率,重写learning_rate。 - bias_momentum:float 默认为不使用
指定偏置的动量,重写momentum。 - bias_l2_regularization:float 默认为0.0
偏置的L2正则化。 - learning_rate_schedule: {‘constant’, ‘exponential_decay’, ‘polynomial_decay’}
学习率调度算法。
constant:对于所有的迭代使用相同的学习率。
exponential_decay:每次迭代指数降低学习率。详情参阅注释部分。 - learning_rate_start_epoch:int 默认为0
开始学习率调度。 - min_learning_rate:float 默认为0.00001
学习率最小值。 - learning_rate_step:int 默认为1
每learning_rate_step数量个特定时间上传学习率。 - learning_rate_gamma:float 默认为0.1
exponential_decay中使用的学习衰变参数。 - learning_rate_alpha:float 默认为0.5
polynomial_decay中使用的学习衰变参数。 - init_random:{‘gaussian’|‘xavier’} 默认为‘gaussian’
权重的初始类型。使用随机高斯初始化或者泽维尔初始化。更多信息见FullConnectionLayer参数。 - init_sigma:float 默认为0.01
高斯分布权重初始化的标准偏差来源。 - init_bias:float 默认为0.0
偏置的初始值。 - divideby:float 默认为1.0
在输入数据插入网络之前缩放的值。
**输出:**NeuralNetClassifier
- batch_size:int 默认为100
注释:
对于exponential_decay,学习率按下式指数降低:
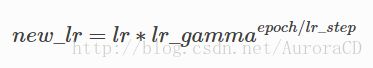
对于polynomial_decay,学习率按下式多项式降低:
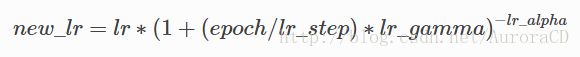
参考:
LeCun,Yann等. Gradient-based learning applied to document recognition
The MNIST database
例子:
我们用MNIST数据训练一个数字识别的卷积神经网络。数据已经从MNIST数据库中下载,并且在Turi’s public S3 bucket中保存为SFrame。
>>> data = graphlab.SFrame('https://static.turi.com/datasets/mnist/sframe/train')
>>> test_data = graphlab.SFrame('https://static.turi.com/datasets/mnist/sframe/test')
>>> training_data, validation_data = data.random_split(0.8)将所有的图片剪裁成相同尺寸,因为神经网络有固定的输入尺寸。
>>> training_data['image'] = graphlab.image_analysis.resize(training_data['image'], 28, 28, 1, decode=True)
>>> validation_data['image'] = graphlab.image_analysis.resize(validation_data['image'], 28, 28, 1, decode=True)
>>> test_data['image'] = graphlab.image_analysis.resize(test_data['image'], 28, 28, 1, decode=True)使用MNIST内置的神经网络构架(一个一层的卷积神经网络):
>>> net = graphlab.deeplearning.get_builtin_neuralnet('mnist')神经网络的层:
>>> net.layers
layer[0]: ConvolutionLayer
padding = 1
stride = 2
random_type = xavier
num_channels = 32
kernel_size = 3
layer[1]: MaxPoolingLayer
stride = 2
kernel_size = 3
layer[2]: FlattenLayer
layer[3]: DropoutLayer
threshold = 0.5
layer[4]: FullConnectionLayer
init_sigma = 0.01
num_hidden_units = 100
layer[5]: SigmoidLayer
layer[6]: FullConnectionLayer
init_sigma = 0.01
num_hidden_units = 10
layer[7]: SoftmaxLayer神经网络的参数:
>>> net.params
{'batch_size': 100,
'data_shape': '1,28,28',
'divideby': 255,
'init_random': 'gaussian',
'l2_regularization': 0.0,
'learning_rate': 0.1,
'momentum': 0.9}使用特定的网络训练一个NeuralNetClassifier(神经网络分类器)
>>> m = graphlab.neuralnet_classifier.create(training_data,
target='label',
network = net,
validation_set=validation_data,
metric=['accuracy', 'recall@2'],
max_iterations=3)分类测试数据,输出最可能的类标签。‘probablity’对应输入属于此类的可能性:
>>> pred = m.classify(test_data)
>>> pred
+--------+-------+----------------+
| row_id | class | probability |
+--------+-------+----------------+
| 0 | 0 | 0.998417854309 |
| 1 | 0 | 0.999230742455 |
| 2 | 0 | 0.999326109886 |
| 3 | 0 | 0.997855246067 |
| 4 | 0 | 0.997171103954 |
| 5 | 0 | 0.996235311031 |
| 6 | 0 | 0.999143242836 |
| 7 | 0 | 0.999519705772 |
| 8 | 0 | 0.999182283878 |
| 9 | 0 | 0.999905228615 |
| ... | ... | ... |
+--------+-------+----------------+
[10000 rows x 3 columns]输出两个最可能的数字:
>>> pred_top2 = m.predict_topk(test_data, k=2)
>>> pred_top2
+--------+-------+-------------------+
| row_id | class | probability |
+--------+-------+-------------------+
| 0 | 0 | 0.998417854309 |
| 0 | 6 | 0.000686840794515 |
| 1 | 0 | 0.999230742455 |
| 1 | 2 | 0.000284609268419 |
| 2 | 0 | 0.999326109886 |
| 2 | 8 | 0.000261707202299 |
| 3 | 0 | 0.997855246067 |
| 3 | 8 | 0.00118813838344 |
| 4 | 0 | 0.997171103954 |
| 4 | 6 | 0.00115600414574 |
| ... | ... | ... |
+--------+-------+-------------------+
[20000 rows x 3 columns]在测试数据上评估分类器,默认指标是accuracy(精确度)和confusion_matrix(混淆矩阵)。
>>> eval_ = m.evaluate(test_data)
>>> eval_
{'accuracy': 0.979200005531311, 'confusion_matrix':
+--------------+-----------------+-------+
| target_label | predicted_label | count |
+--------------+-----------------+-------+
| 0 | 0 | 969 |
| 2 | 0 | 2 |
| 5 | 0 | 2 |
| 6 | 0 | 9 |
| 7 | 0 | 1 |
| 9 | 0 | 2 |
| 1 | 1 | 1126 |
| 2 | 1 | 2 |
| 6 | 1 | 2 |
| 7 | 1 | 3 |
| ... | ... | ... |
+--------------+-----------------+-------+
[64 rows x 3 columns]}
Next Previous
英文原文见链接(新手上路,可能存在不少错误,还请各位大神不吝赐教)
https://turi.com/products/create/docs/generated/graphlab.neuralnet_classifier.create.html#graphlab.neuralnet_classifier.create