在Azure HDInsight中创建R服务器,并利用Spark集群进行分布式R分析
关于R语言
R作为一种编程语言和软件运行环境,近年来被数据科学家广泛使用。它是一种解释性语言,在R library中自带很多统计学方法(statistical methods)和图形算法,例如线性回归分析,决策树,经典统计学测验等等。另外,通过Functions和Extensions,也可以很容易的对R进行扩展,增加数据模型和分析算法。R Studio是一个R语言的集成开发环境(IDE):

我们也可以通过R Console 编辑和运行R脚本。例如:
> x <- c(1,2,3,4,5,6) # Create ordered collection (vector)
> y <- x^2 # Square the elements of x
> print(y) # print (vector) y
[1] 1 4 9 16 25 36关于Azure HDInsight中的R服务器(R Server)
在HDInsight集群中创建R Server,并通过设置不同的Compute Context观察性能差异

第一步:创建R Server Cluster
1. 登录到global azure (http://portal.azure.com)
2. 选择NEW, Intelligence+ Analytics,然后选HDInsight

3. 为集群指定一个名称
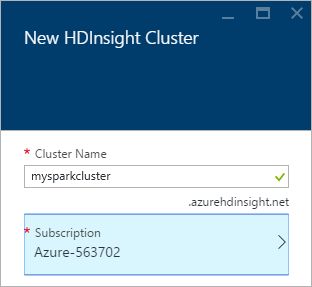
4. 选择Cluster Configuration,在ClusterConfiguration这一项,cluster type选择R-Server,版本选择最新,其余的保持默认设置即可,然后点击select。Microsoft R-Server release notes: https://msdn.microsoft.com/en-us/microsoft-r/notes/r-server-notes.
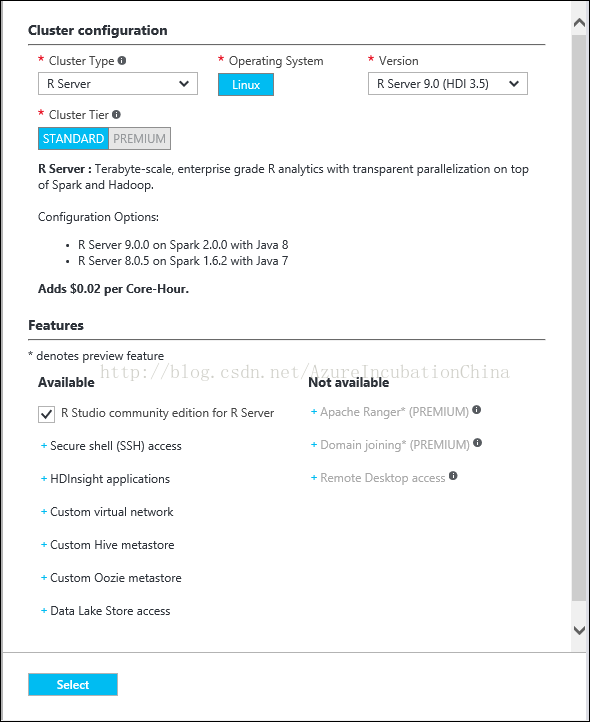
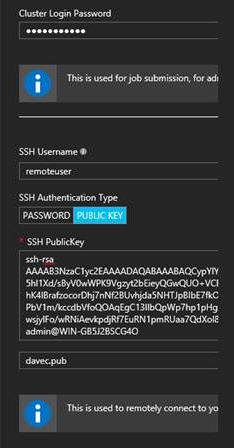
5. 选择Credentials,设置集群登录用户名和认证信息。为集群登录用户admin设置一个登录密码,设置一个名为remoteuser的ssh用户,认证方式选择sshkey,导入用cygwin生成的id_rsa.pub文件。如何生成请参照文档最后生成ssh key章节。
6. 选择DataSource,这里我们用Azure Storage作为cluster的Data Source

7. 选择NodePricing Tiers,设置节点数量和配置,这里用的是默认设置.

8. 设置ResourceGroup,选择一个已有的或者新建一个,这里我们新建了一个Resource Group

9. 点击create,等待cluster创建完成。
第二步:在R Server边缘节点上(Edge Node)运行一个运算逻辑(R Analytics Job)。



3. 连接成功后,输入R回车打开R console

4. 用下面命令创建一个RxSparkcompute context,注意替换private key的路径和edge node的地址
myNameNode <- "default"
myPort <- 0
mySshHostname <- 'rkrrehdi1-ed-ssh.azurehdinsight.net' # HDI secure shell hostname
mySshUsername <- 'remoteuser'# HDI SSH username
mySshSwitches <- '-i /cygdrive/c/Data/R/davec' # HDI SSH private key
myhdfsShareDir <- paste("/user/RevoShare", mySshUsername, sep="/")
myShareDir <- paste("/var/RevoShare" , mySshUsername, sep="/")
mySparkCluster <- RxSpark(
hdfsShareDir = myhdfsShareDir,
shareDir = myShareDir,
sshUsername = mySshUsername,
sshHostname = mySshHostname,
sshSwitches = mySshSwitches,
sshProfileScript = '/etc/profile',
nameNode = myNameNode,
port = myPort,
consoleOutput= TRUE
)
#Set the HDFS (WASB) location of example data
bigDataDirRoot <-"/example/data"
# create a local folder forstoraging data temporarily
source <-"/tmp/AirOnTimeCSV2012"
dir.create(source)
# Download data to the tmp folder
remoteDir <-"http://packages.revolutionanalytics.com/datasets/AirOnTimeCSV2012"
download.file(file.path(remoteDir,"airOT201201.csv"), file.path(source, "airOT201201.csv"))
download.file(file.path(remoteDir,"airOT201202.csv"), file.path(source, "airOT201202.csv"))
download.file(file.path(remoteDir,"airOT201203.csv"), file.path(source, "airOT201203.csv"))
download.file(file.path(remoteDir,"airOT201204.csv"), file.path(source, "airOT201204.csv"))
download.file(file.path(remoteDir,"airOT201205.csv"), file.path(source, "airOT201205.csv"))
download.file(file.path(remoteDir,"airOT201206.csv"), file.path(source, "airOT201206.csv"))
download.file(file.path(remoteDir,"airOT201207.csv"), file.path(source, "airOT201207.csv"))
download.file(file.path(remoteDir,"airOT201208.csv"), file.path(source, "airOT201208.csv"))
download.file(file.path(remoteDir,"airOT201209.csv"), file.path(source, "airOT201209.csv"))
download.file(file.path(remoteDir,"airOT201210.csv"), file.path(source, "airOT201210.csv"))
download.file(file.path(remoteDir,"airOT201211.csv"), file.path(source, "airOT201211.csv"))
download.file(file.path(remoteDir,"airOT201212.csv"), file.path(source, "airOT201212.csv"))
# Set directory in bigDataDirRootto load the data into
inputDir <-file.path(bigDataDirRoot,"AirOnTimeCSV2012")
# Make the directory
rxHadoopMakeDir(inputDir)
# Copy the data from source toinput
rxHadoopCopyFromLocal(source, bigDataDirRoot)
# Define the HDFS (WASB) file system
hdfsFS <- RxHdfsFileSystem()
# Create info list for the airline data
airlineColInfo <- list(
DAY_OF_WEEK = list(type = "factor"),
ORIGIN = list(type = "factor"),
DEST = list(type = "factor"),
DEP_TIME = list(type = "integer"),
ARR_DEL15 = list(type = "logical"))
# get all the column names
varNames <- names(airlineColInfo)
# Define the text data source in hdfs
airOnTimeData <- RxTextData(inputDir, colInfo = airlineColInfo, varsToKeep = varNames, fileSystem = hdfsFS)
# Define the text data source in local system
airOnTimeDataLocal <- RxTextData(source, colInfo = airlineColInfo, varsToKeep = varNames)
# formula to use
formula = "ARR_DEL15 ~ ORIGIN + DAY_OF_WEEK + DEP_TIME + DEST"
# Set a local compute context
rxSetComputeContext("local")
# Run a logistic regression
system.time(
modelLocal <- rxLogit(formula, data = airOnTimeDataLocal)
)
# Display a summary
summary(modelLocal)
# Define the Spark compute context
mySparkCluster <- RxSpark()
# Set the compute context
rxSetComputeContext(mySparkCluster)
# Run a logistic regression
system.time(
modelSpark <- rxLogit(formula, data = airOnTimeData)
)
# Display a summary
summary(modelSpark)在7和8运行结束后,我们会得到类似下面的运行结果:

第三步:两种Compute Context运行环境的比较

SSH Key的一种生成方法


3. 创建R-Server时,导入id_rsa.pub,如前文所述。
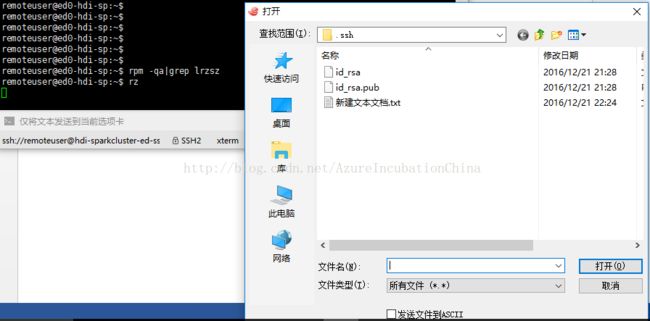
4. 登录到 R-Server 的 edge node ,我们要把生成的private key上传到R-Server的node上去,这要用到 lrzsz ,登录到 edge node ,先运行rpm -qa|grep lrzsz