Logstash/Filebeat->Logstash->Kafka->Spring-kafka->MongoDb->Spark日志收集和处理
Logstash/Filebeat->Logstash->Kafka->Spring-kafka->MongoDb日志收集和处理
- Logstash/Filebeat->Logstash->Kafka->Spring-kafka->MongoDb日志收集和处理
- 1. 背景
- 1.1 ELK
- 1.2 为什么不用ELK
- 2. Agent(Filebeat/Logstash)
- 2.1 Filebeat
- 2.1.1 条件
- 2.1.2 安装、配置和启动
- 2.2 Logstash
- 2.2.1 条件
- 2.2.2 特殊要求
- 2.2.3 将lumberjack插件打包到logstash安装包里
- 2.2.5 安装、配置和启动
- 2.1 Filebeat
- 3. ProxyAgent(Logstash)
- 3.1 安装、配置和启动
- 3.2 Logstash多实例与负载均衡
- 3.2.1 水平集群
- 3.2.2 垂直集群
- 4. Kafka
- 4.1 安装、配置和启动
- 5. Spring-kafka
- 5.1 dependency
- 5.2 Java Consumer
- 5.2.1 kafka配置和consumer创建
- 5.2.2 kafka预防重复消费的配置
- 6. Spring-mongo
- 6.1 dependency
- 6.2 mongo自增ID的实现方法
- 6.3 删除重复数据
- 7. Spark
- 1. 背景
1. 背景
1.1 ELK
ELK(ElasticSearch + Logstash + Kibana)是一套非常成熟广泛应用的日志分析系统,对于大部分系统,直接使用ELK基本就能满足业务需求,但是针对一些特殊的需求和无法避免的限制条件,完全可以用Elastic1的各种产品结合外部输入输出,比如Kafka Redis File等,达到想要的效果。
1.2 为什么不用ELK
- 系统设计为输入端收集日志信息推送到代理端,代理同一处理日志推送到
Kafka集群,使用Java(spring-kafka)消费Kafka中的数据,最终把数据结果存入MongoDB; - 首先
logstash是java写的,运行logstash需要java环境,这就导致输入端需要额外的环境的资源,因此可以使用Filebeat代替Logstash。不过部分系统不能运行Filebeat,因为Filebeat是用go写的,然而一些系统,比如IBM AIX,并没有支持的go语言的编译器,所以不得不同时采用Filebeat和Logstash,根据实际情况选择; - 首先输入端(
Agent)和输出端Kafka+MongoDB网络不通,中间有个代理(ProxyAgent),无法直接使用Logstash或Filebeat输出到Kafka,因此在ProxyAgent上安装Logstash接受所有Agent推送的日志,统一处理后推送到Kafka; - 使用
Kafka除了缓存和生产与消费速度不匹配外,系统还会出现多个Group消费同一Topic的情况; - 使用
Java消费Kafka而不直接输出到MongoDB,因为一部分数据需要做复杂的清洗。 - 展示的数据要根据收集的数据做计算,用
spark定时计算并存储到MongoDB做为可视化的数据源。
这些都是ELK无法直接实现的,当然也可以说ELK更加纯粹,不过Elastic系列产品有各种各样的插件,匹配不同的输入和输出数据源,完全没有问题。
2. Agent(Filebeat/Logstash)
2.1 Filebeat
2.1.1 条件
Filebeat2是一个轻量级的Log Shipper,但是注意需要支持go语言编译,否则无法使用。- 系统环境:
Linux(Red Hat)。
2.1.2 安装、配置和启动
#下载安装包
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.1.2-linux-x86_64.tar.gz
#解压
tar -zvxf filebeat-6.1.2-linux-x86_64.tar.gz
#备份配置文件模板,全新的filebeat.yml相当于是一个配置文件reference
cd filebeat-6.1.2-linux-x86_64
cp filebeat.yml filebeat.yml.back
#配置filebeat.yml
rm -rf filebeat.yml
vim filebeat.yml
##>>>>>>>>>>>>>>>>>>>>>>>>>file start>>>>>>>>>>>>>
# prospector
filebeat.prospectors:
- type: log
enabled: true
paths:
- /path/to/log/file/**/*.log
fields:
appName: dbaas-indicator
document_type: dbaas-indicator
scan_frequency: 10s
output.logstash:
hosts: ["192.168.0.150:5044"]
##>>>>>>>>>>>>>>>>>>>>>>>>>file end>>>>>>>>>>>>>
ESC
:wq
# 验证配置文件
./filebeat test config
#>>>>>>>>>>>>output>>>>>>>>>>>>>
Config OK
#>>>>>>>>>>>>output>>>>>>>>>>>>>
#启动filebeat
./filebeat -e -c filebeat.yml -d "publish" &配置含义和更多配置请参考官方参考手册。
2.2 Logstash
2.2.1 条件
Logstash3需要java环境,安装前必须安装jdk 1.8+。- 系统环境:
Linux(Red Hat)。
2.2.2 特殊要求
- 如果
Agent安装Logstash,从Logstash推送数据到另一个Logestash需要使用Logstash的logstash-in[out]put-lumberjack插件,这两个插件在较高的Logstash版本中是不包含的,需要手动安装。 Agent可能无法连接到公网,因此不能在线安装,需要离线安装,所以要把插件包放到原始的安装包内并重新打包软件包。logstash-in[out]put-lumberjack基于ssl认证,所以要准备好一对ssl证书和密钥,可以使用openssl4生成,假设已经生成好了,并且把证书和密钥都放在ProxyAgent(/root/server.crt)、把证书放在Agent(/root/server.key)。
2.2.3 将lumberjack插件打包到logstash安装包里
#重新打包的服务器必须能连公网
#下载安装包
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.1.2.tar.gz
#解压
tar -zvxf logstash-6.1.2.tar.gz
#在线安装插件
##安装logstash-input-lumberjack
cd logstash-6.1.2
bin/logstash-plugin install logstash-input-lumberjack
#>>>>output>>>>>
Validating logstash-input-lumberjack
Installing logstash-input-lumberjack
Installation successful
#>>>>output>>>>>
##安装logstash-output-lumberjack
bin/logstash-plugin install logstash-output-lumberjack
#>>>>output>>>>>
Validating logstash-output-lumberjack
Installing logstash-output-lumberjack
Installation successful
#>>>>output>>>>>
##验证安装
bin/logstash-plugin list | grep lumberjack
#>>>>output>>>>>
logstash-input-lumberjack
logstash-output-lumberjack
#>>>>output>>>>>
##构建logstash-in[out]put-lumberjack离线包
bin/logstash-plugin prepare-offline-pack logstash-input-lumberjack logstash-output-lumberjack
#文件会生成在logstash根目录下
#>>>>output>>>>>
Offline package created at: /root/temp-for-logstash/logstash-6.1.2/logstash-offline-plugins-6.1.2.zip
You can install it with this command `bin/logstash-plugin install file:///root/temp-for-logstash/logstash-6.1.2/logstash-offline-plugins-6.1.2.zip`
#>>>>output>>>>>
#重新构建logstash-with-plugin软件包
cd ../
mkdir logstash-6.1.2-with-plugin
tar -zvxf logstash-6.1.2.tar.gz -C logstash-6.1.2-with-plugin
cp logstash-6.1.2/logstash-offline-plugins-6.1.2.zip logstash-6.1.2-with-plugin/logstash-6.1.2/logstash-offline-plugins-6.1.2.zip
cd logstash-6.1.2-with-plugin
tar -czvf logstash-6.1.2-with-plugin.tar.gz logstash-6.1.2此时logstash-6.1.2-with-plugin.tar.gz就是包含插件离线安装包的软件包了5。
2.2.5 安装、配置和启动
#解压
tar -zvxf logstash-6.1.2-with-plugin.tar.gz
rm -rf logstash-6.1.2-with-plugin.tar.gz
mv logstash-6.1.2 logstash-6.1.2-for-logstash
cd logstash-6.1.2-for-logstash
#离线安装插件
##开始安装
bin/logstash-plugin install file:///path/to/logstash/logstash-6.1.2-for-logstash/logstash-offline-plugins-6.1.2.zip
#>>>>output>>>>>
Installing file: /path/to/logstash/logstash-6.1.2/logstash-offline-plugins-6.1.2.zip
Install successful
#>>>>output>>>>>
##验证安装
bin/logstash-plugin list | grep lumberjack
#>>>>output>>>>>
logstash-input-lumberjack
logstash-output-lumberjack
#>>>>output>>>>>
#新增配置文件
vi config/logstash.conf
##>>>>>>>>>>>>>>>>>>>>>>update start>>>>>>>>>>>>>>>>>>>
input {
file {
path => "/path/to/log/**/*.log"
add_field => {"appName" => "dbaas-indicator"}
type => "dbaas-indicator"
discover_interval => 10
}
}
filter{
if([message] =~ "^\{\"params\".*$"){
drop{}
}
}
output{
lumberjack {
hosts => ["192.168.0.150"]
port => 5045
ssl_certificate => "/root/server.crt"
codec => json
}
}
##>>>>>>>>>>>>>>>>>>>>>>update end>>>>>>>>>>>>>>>>>>>>>
ESC
:wq
# 验证配置文件
bin/logstash -t -f config/config.conf
#>>>>>>>>>output>>>>>>>>>>>>>
Configuration OK
#>>>>>>>>>output>>>>>>>>>>>>>
#可以启动了
cd ../bin
#可能需要指定JAVA_HOME
#export JAVA_HOME=/path/to/java/home
bin/logstash -f config/logstash.conf &更多配置请参考官方参考手册。
3. ProxyAgent(Logstash)
3.1 安装、配置和启动
安装过程和Agent安装Logstash几乎一样,只是将Logstash作为input而不是Agent的output到Logestash。
#新增配置文件
vi config/logstash.conf
##>>>>>>>>>>>>>>>>>>>>>>update start>>>>>>>>>>>>>>>>>>>
input {
lumberjack {
port => 5045
ssl_certificate => "/root/server.crt"
ssl_key => "/root/server.key"
codec => json
tags => ["logstash-input"]
}
beats {
port => 5044
tags => ["filebeat-input"]
}
}
output{ ##按照appName推送到不同的topic
if "logstash-input" in [tags] {
kafka {
codec => json
bootstrap_servers => "192.168.0.113:9092"
topic_id => "%{[appName]}"
acks => "1"
compression_type => "gzip"
}
} else if "filebeat-input" in [tags] {
kafka {
codec => json
bootstrap_servers => "192.168.0.113:9092"
topic_id => "%{[fields][appName]}"
acks => "1"
compression_type => "gzip"
}
} else {
stdout {
codec => json
}
}
}
##>>>>>>>>>>>>>>>>>>>>>>update end>>>>>>>>>>>>>>>>>>>>>
ESC
:wq其中input和output配置中的codec => json有丶关键,否则一些附加的field可能解析不出来,比如Logstash的input.add_field中添加的字段、Filebeat的filebeat.prospectors.fields等,更多配置请参考官方参考手册。
3.2 Logstash多实例与负载均衡
3.2.1 水平集群
Logstash is horizontally scalable and can form groups of nodes running the same pipeline. Logstash’s adaptive buffering capabilities will facilitate smooth streaming even through variable throughput loads. If the Logstash layer becomes an ingestion bottleneck, simply add more nodes to scale out. Here are a few general recommendations:
- Beats should load balance across a group of Logstash nodes.
- A minimum of two Logstash nodes are recommended for high availability.
- It’s common to deploy just one Beats input per Logstash node, but multiple Beats inputs can also be deployed per Logstash node to expose independent endpoints for different data sources.6
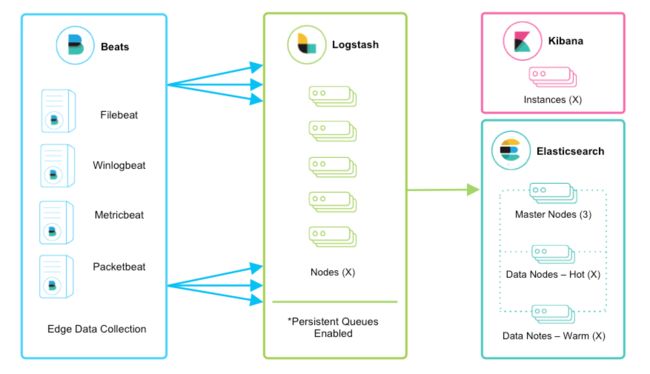
所以水平集群搭建相当简单,只需要在多个节点启动Logstash实例,它们的配置应该相同,然后在Beats端做负载均衡7,但是目前好像只支持Beats->Logstash的负载均衡,没有找到Logstash->Logstash负载均衡相关的资料。
3.2.2 垂直集群
同样,这里还是针对Beats的集群,问题的关键是如何在同一个机器上启动多个实例。Logstash有两种安装方式,一种是解压即用,一种是执行bin/system-install,后者可以作为一个服务启动。
- 安装方法如果是前者,可以之际拷贝两个软件目录,然后分别启动即可,并不会出现冲突,因为
logstash会自动在9600-9700之间寻找未被占用的端口(见config/logstash.yml中http.port的解释),如果指定了http.port,只要实例的http.port与其他实例不同即可,在Beats输出到多个hosts并设置loadbalance: true即可。 - 安装方法如果是后者,可以参考这里:Multiple Logstash Instances on Single Server,相对麻烦一点,目前没有这样的需要,暂不做深入研究。
4. Kafka
4.1 安装、配置和启动
#hostname:::host113
#hostip:::::192.168.0.113
#这里是standalone
#集群基于zookeeper集群,先要搭建zookeeper集群,才能搭建kafka集群,只需简单修改一些配置文件重启zookeeper和kafka即可
#下载tar包
wget http://apache.claz.org/kafka/1.0.0/kafka_2.11-1.0.0.tgz
#解压
tar -zvxf kafka_2.11-1.0.0.tgz
#启动zookeeper
cd kafka_2.11-1.0.0/bin
./zookeeper-server-start.sh ../config/zookeeper.properties &
#配置kafka
vim ../config/server.properties
#>>>>>>>>>>>>>>>>>>>>update start>>>>>>>>>>>>>>>>>
#很重要,否则默认只能以hostname:9092访问kafka,consumer主机必须配置hosts文件
listeners=PLAINTEXT://192.168.0.113:9092
#下面几个也配置上,可能不同版本的客户端需要使用这些参数
advertised.listeners=PLAINTEXT://192.168.0.113:9092
advertised.port=9092
port=9092
advertised.host.name=192.168.0.113
#同一个Group使用6个Consumer来消费最佳
num.partitions=6
#>>>>>>>>>>>>>>>>>>>>update end>>>>>>>>>>>>>>>>>>>
#启动kafka
./kafka-server-start.sh ../config/server.properties &
#查询PID
jps -ml
##>>>>>>>>>>>>>>>>>>>>output start>>>>>>>>>>>>>>>>>>
#25987 org.apache.zookeeper.server.quorum.QuorumPeerMain ../config/zookeeper.properties
#26298 kafka.Kafka ../config/server.properties
##>>>>>>>>>>>>>>>>>>>>output end>>>>>>>>>>>>>>>>>>5. Spring-kafka
基于spring-boot。
5.1 dependency
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>5.2 Java Consumer
5.2.1 kafka配置和consumer创建
- 首先配置
kafka相关信息,直接在application.properties添加配置;
spring.kafka.bootstrap-servers=192.168.0.113:9092
spring.kafka.listener.concurrency=3
spring.kafka.listener.poll-timeout=3000
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.consumer.auto-commit-interval=100
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.group-id="dbaas-logger"
spring.kafka.consumer.auto-offset-reset=latest- 监听直接使用
@KafkaListener注解就好好了;
@Component
public class KafkaListenerConfig {
@KafkaListener(topics = {"dbaas-indicator"})
public void listen1(ConsumerRecord record) {
Optional kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
Object objectMessage = kafkaMessage.get();
LOGGER.info("dbaas-indicator:\n\t{}", String.valueOf(objectMessage));
}
}
}5.2.2 kafka预防重复消费的配置
- 为什么会重复消费:正常情况下,同一个
group下的consumer不会重复消费数据,但是某一个consumer在消费数据时遇到了问题导致kafka session(session.timeout.ms)超时,此时kafka认为消费失败,将重新分配给consumer,如果一直失败就会导致死循环一直消费重复的数据。 - 解决方法:
spring-kafka可以禁用kafka client默认的offset提交方式,spring-kafka会在消费完成后手动提交offset,从kafka取回的数据先缓存到阻塞队列,也不存在数据丢失的问题,是比较完美且省事的解决方法:kafka重复消费问题- 配置
kafka consumer,加长超时时间、修改poll策略等,但不是最好的方法:kafka9重复消费问题解决 - 手动缓存
partition_group=>offset的mapping(比如分布式的系统缓存到redis),每次消费前读取缓存并手动设置consumer的offset;消费后手动去更新缓存中的offset,这种方法的可控性非常强,但是consumer要自己用Java API写,并且各种成本都要高一些,稍微麻烦一点:Kafka重复消费和丢失数据研究|关于怎么获取kafka指定位置offset消息
6. Spring-mongo
6.1 dependency
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-mongodbartifactId>
dependency>
<dependency>
<groupId>org.mongodbgroupId>
<artifactId>mongo-java-driverartifactId>
dependency>6.2 mongo自增ID的实现方法
- 思路很简单,首先
MongoTemplate.findAndModify()是一个原子操作,和MySql的select for update有丶类似;然后根据这个特性,只要把ID存在一个colection里面,每次用这个方法取出来再+1更新进去就可以了; - 不必在每个插入方法前主动查询
ID并更新,只需写一个全局MongoEventListener即可,继承自AbstractMongoEventListener,重写onBeforeConvert()方法,在里面设置并更新ID:
@Configuration
public class MongoEventListener extends AbstractMongoEventListener {
private final static Logger LOGGER = LoggerFactory.getLogger(MongoEventListener.class);
@Autowired
MongoService mongoService;
@Override
public void onBeforeConvert(BeforeConvertEvent event) {
Object source = event.getSource();
if(source != null){
JSONObject jsonSource = (JSONObject) source;
Long dbaasId = mongoService.getNextId(COLLECTION_INDICATORS);
LOGGER.info("设置ID:{}",dbaasId);
jsonSource.put(KEY_DBAAS_ID,dbaasId);
}else {
LOGGER.error("待插入mongo的数据为空,不写入ID");
}
}
}- 试过重写
onBeforeSave()方法,发现在方法是执行了,但是里面添加的ID字段并没有存到Mongo,因为onBeforeSave()是持久化完成之后保存之前调用,而onBeforeConvert()是序列化之前调用,因此明显序列化之前是最好的选择。
6.3 删除重复数据
因为mongo删除某一个范围内数据有点麻烦,如果出现了5.2.2中重复消费的问题,那么可能需要删除重复的数据。思路是:查出重复的范围,然后根据唯一键group,此时可以用$addToSet方法,把所有的文档_id放到集合(有点类似mysql group_concat()),然后删除把集合中_id对应的文档保留一个,其他的全部删除。
db.dbIndicators.aggregate([
{$match:{CREATE_TIME:{$gte:1519228800000,$lt:1519315200000},hostId:{$exists:true}}},
{$group:{_id:{CREATE_TIME:'$CREATE_TIME',definitionId:'$definitionId',hostId:'$hostId'},count:{$sum:1},dups:{$addToSet:'$_id'}}},
{$match:{count:{$gt:1}}}],{allowDiskUse:true}).forEach(function(doc){
doc.dups.shift();//保留一个
db.dbIndicators.remove({_id:{$in:doc.dups}})}
);7. Spark
待补充。
ELK和Beats等都是elastic的产品,更多产品移步:elastic ↩- 更多
Filebeat信息请参考:Filebeat | Filebeat Reference ↩ - 更多
Logstash信息请参考:Logstash | Logstash Reference ↩ openssl使用方法:How-to-configure-SSL-for-FileBeat-and-Logstash-step-by-step ↩- 更多
Logstash plugin离线安装信息:Offline Plugin Management ↩ - 更多
Logstash scaling信息:Deploying and Scaling Logstash ↩ - 更多
Filebeat负载均衡信息:Configure the Logstash output ↩