Multi-Probe LSH原理分析
Multi-Probe LSH
Multi-Probe LSH,即多探寻的局部敏感哈希,由Qin Lv、William Josephson、Zhe Wang、Moses Charikar、Kai Li在发表于VLDB 2007中的论文《MultiProbe LSH: Efficient Indexing for HighDimensional Similarity Search》中提出。该方法针对基本LSH方法需要查询大量哈希表来保证搜索质量的缺点进行优化,其核心思想是**使用一个严格挑选的探测序列来检测多个可能包含最近邻点的桶。根据lsh的性质,如果查询点q的近邻p没有被映射到q所在的桶,那么p很可能在p所在桶附近的桶中。Multiprobe lsh的目的就是找到这些邻近的桶,增大找到q的近邻点的概率。**论文的作者通过实验证明,在保证相同时间效率的情况下,Multi-Probe LSH比基本的LSH方法减少了一个数量级的哈希表数量;在保证相同的搜索质量的情况下,Multi-Probe LSH比基于熵的LSH方法(Entropy-based LSH)减少了查询时间,同时少用了5-8倍的哈希表。算法概述
我们知道,给定一个查询点q,基本的局部敏感哈希方法查询哈希桶 g(q)=h1(q),…,hm(q) ;而在Multi-Probe LSH里,对于查询点q,我们定义一个扰动序列向量 Δ=δ1,…,δm ,当我们应用扰动序列Δ,我们将探询桶g(q)+Δ。 假定我们使用基于P 稳定分布的局部敏感哈希函数 H(o)=[a⃗ .o⃗ +b]w ,如果我们选择的w 足够大,邻近的数据点将以很高的概率落在相同或者邻近的值上(相差不超过1),因此,我们约束Δ的取值范围为{-1,0,1}。 每一个扰动向量将直接作用于查询对象的哈希值,所以,与基于熵的局部敏感哈希方法相比,节省了计算扰动点的哈希值的时间。我们将设计一组扰动序列作用于哈希值的集合使得查询一个哈希桶的次数不会超过一次。 图1 显示了多探寻的局部敏感哈希方法的原理,在图中,g i(q)是在第i个表中的查询点q 的哈希值, (Δ1,Δ2,….) 是一组探寻序列, gi(q)+Δ1 是应用扰动向量Δ1 后产生的新的哈希值,它指向表中的一个新的哈希桶,通过使用多个扰动向量,我们可以获得多个与q 指向的哈希桶“邻近”的桶,这些桶中很有可能含有与q邻近的元素。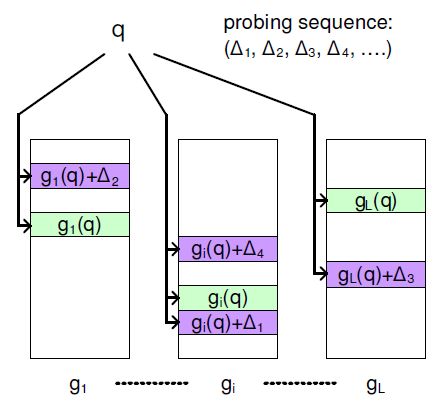
步进式探寻
一个n 步的扰动序列Δ有n 个非零坐标。这个扰动序列对应于查询一个哈希桶(它与查询点所在的哈希桶的一组哈希值有n 个不同 )。根据局部敏感哈希函数的性质,只有一步距离的哈希桶(也就是说,在查询点的一组哈希值中,仅有一个不同)比二步距离的哈希桶更有可能包含查询点的邻近的数据点。
根据LSH的这个性质,我们首先检查一步距离的桶,然后是二步距离的桶,直到我们找到足够的哈希桶。而在大多数情况下,一个2 步内的步进式探寻足以保证我们可以找到大部分成功概率较高的桶。对于一个含有L 个哈希表以及m个局部敏感哈希函数的局部敏感哈希算法,n 步的查询桶的总数为 L×Cnm×2n ,而s 步内查询哈希桶的总数为 L×∑sn=1×Cnm×2n 。
对于基于欧氏距离的局部敏感算法,我们可以对哈希值做+1 或者-1 扰动。而对于基于汉明距离的局部敏感哈希算法,它的哈希值为0 或1,也就是说,在它等于0 时,它不能做-1 扰动,而它在等于1 时,不能做+1 扰动。我们使用一个简单的方法来替代它,当我们选定一个哈希值时,我们将它做01 变换,也就是说,若它为0,则将它变为1,若它为1,则将它变为0。
图2显示了k个最近邻所在桶的距离的分布情况。左图描述的是单个哈希值( δi )上的差异,右图则描述的是与查询点(n步距离桶)的哈希值相比,不同哈希值的个数的差异。从图中我们可以看出,在单个哈希值上,几乎全部k个最近邻点都与查询点相同,或者相差+1或-1。同时,绝大多数k最近邻点都被映射到了查询点两步距离内的桶里。
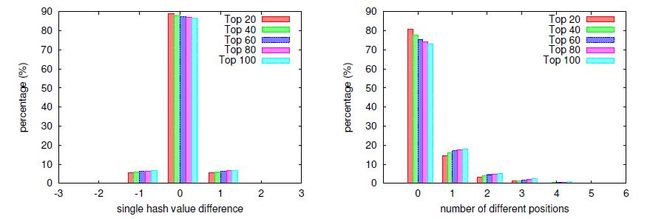
成功概率评估
在步进式探寻中,查询点q 的所有哈希值被同等地对待,也就是说,每个哈希值的被扰动的概率相同,同时,对每个哈希值加1还是减1的概率也是相同的。然而一个更加优化的构造探寻序列的方法需要考虑查询点q的各个哈希值是怎么计算的。
每个哈希函数 ha,b(q) 会将查询点q 映射到一条直线上,这条直线以w 为宽度从左到右划分为不同的区域,得到的哈希值就是点q 所要映射到的区域,一个与点q相邻近的点p 可能落在与点q 一样或相邻的区域,事实上,点p 落在点q 右边(或左边)的区域取决于点q 落下的位置与它落下的区域的右边界(左边界)的距离。
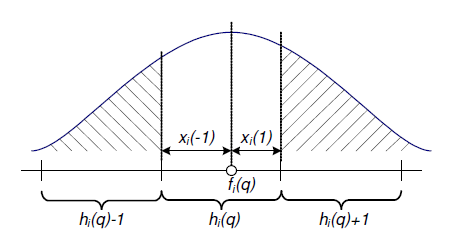
图3描述了查询点q的近邻点落在其相邻区域的概率。这里 fi(q)=a⃗ i.q+bi 是在使用第i个哈希函数后,查询点q在直线上的映射,hi(q) 是查询点q哈希到的区域,对于δ∈{-1,1},定义 xi(δ) 为查询点q到区域 hi(q)+δ 边界的距离,也就是说, xi(−1)=fi(q)−hi(q)×w,xi(1)=w–xi(−1) ,方便起见,我们定义 xi(0)=0 。对于任何一个固定的点p, fi(p)−fi(q) 是一个服从均值为0的高斯分布的随机变量,这个随机变量的方差与点p和点q的距离成比例,假设选择的w足够大,使得我们感兴趣的点p以足够高的概率落在区域 hi(q) , hi(q)−1 , hi(q)+1 上。高斯随机变量的概率密度函数为 e−x2σ ,所以,点p落在区域 hi(q)+δ 的概率可以估计为:
其中C为一个常数,其值取决于 ||p−q||2 。(p是固定的,求其落在h-1(或h+1)上的概率)
我们现在可以估计一个扰动向量 Δ=(δ1,...,δm) 的成功概率(找到一个q的紧邻的p)为:
因此,我们可以对一个扰动向量能够产生查询点q附近的扰动点的可能性进行评分:
且分数(score)越低,可能性越高,因为从上面的概率计算公式我们可以看到,p的成功概率与score是负相关的。
查询导向(Query-Directed)的探寻序列
我们可以直接依据查询点q 中获得扰动向量,并按其得分从小到大来产生扰动向量。一个初步的生成扰动序列的方法是生成所有的序列,计算它们的得分并对其进行排序。但是,总共有L*(2K-1)个扰动序列,而我们只希望准确的使用它们其中分数最小的一部分,所以生成所有的扰动序列是极浪费的。下面描述了一种按得分的升序来产生扰动向量的更加有效的方法。
首先,我们注意到扰动向量Δ的得分仅依赖于那些Δ中的非零坐标(因为对于δ= 0,xi(δ) = 0),我们预计得分低的扰动向量仅含有一些非零坐标。在扰动序列生成中,我们把向量的非零坐标表示为一组(i,δi)对,一个(i,δ)对表示在查询点q 的第i 个哈希值上加上δ。
给定一个查询点q 和一个哈希表对应的哈希函数h1,i=1,2,…,m,对应于一个单一的哈希表,我们首先计算xi(δ)∈{-1,1},i=1,2,…,m,我们将这2m 个元素从小到大进行排序,并定义zj 为该序列中的第j 个元素。定义πj,如果zj= xi(δ),则定义πj=(i,δ),这表示值xi(δ)是在序列中第j 个小的值。注意到xi(1)+ xi(-1)=w,如果πj=(i,δ),那 π2m+1−j=(i,−δ) (因为概率分布曲线是对称的)。现在我们把扰动向量表示成集合{1,2,…,2m}的子集,相当于一个扰动集。对于每一个这样的扰动集A,相应的扰动向量为根据扰动集合A从集合{πj|j∈{1,…,2m}}中获得 {πj|j∈A}的扰动坐标及其值。定义每一个扰动集A的评分score(A)为属于集合A 的zj 值的平方和,这与其对应的扰动向量的得分相等。整个过程举例如图4所示。

因此给定一个排好序的(i,δi)对的队列π以及值zj,j = 1,…,2m,产生扰动向量的问题简化为从集合{1,2,…,2m}按其得分从小到大产生扰动集。在扰动集上定义两个操作:
- shift(A):这个操作将用元素1+max(A)来替代集合A 中的元素max(A),例如,shift({1,3,4})={1,3,5};
- expand(A):这个操作扩充集合A,将元素1+max(A)添加到集合A 中,例如,shift({1,3,4})={1,3,4,5}
通过这两个操作,我们显示我们如何产生T 个扰动集的算法,算法具体描述如下:
Algorithm Generate T perturbation sets
1 A0 = {1}
2 minHeap_insert(A0,score(A0))
3 for i = 1 to T do
4 repeat
5 Ai = minHeap_extractMin()
6 As = shift(Ai)
7 minHeap_insert(As,score(As))
8 Ae = expand(Ai)
9 minHeap_insert(Ae,score(Ae))
10 until valid(Ai)
11 output Ai
12 end for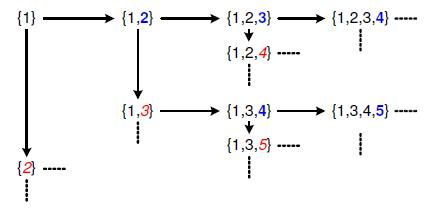
关于shift 和expand 操作有两个性质对于保证上述产生扰动集过程的正确性很重要。
- 对于任意的扰动集A,集合shift(A)和expand(A)的得分都比A 的得分高。
- 对于一个任意的扰动集A,有一个单一的shift 和expand 过程从{1}开始直到生成A。
基于上面两个性质,很容易得出下面两个正确的性质:
性质1:该产生过程按集合的得分从小到大正确地产生了所有有效的扰动集。
性质2:在任何时候,堆中的元素数量总是比一轮操作前的元素数量多一个。
为了简化描述,我们只是描述了在一个单一的哈希表上的扰动序列的产生过程。事实上,我们必须对所有的L 个哈希表产生扰动序列,对于每一个哈希表,我们维护一个排好序的(i,δi)对的队列以及值zj。但是我们可以只使用一个最小堆来同时对每个哈希表产生扰动集。每一个在堆中的坐标扰动集合都于一个哈希表t,t = 1,…,L 相关联。我们初始化L 份集合{1}的拷贝,并将对这些集合的操作分别于不同的哈希表t 相关联。
扰动序列的构造优化
上一节所阐述的扰动序列构造方法通过维护一个堆以及在查询时查询堆来生成扰动向量。除此之外,作者还在文中描述了一种方法来在查询时维护和查询这个堆的开销。该方法预先计算一组序列来替代在查询时对堆的查询以及插入,从而减少扰动序列的生成时间。注意到扰动序列的生成可以被分为两个部分:(1) 按顺序生成扰动集合,(2)将每个扰动集合映射为一个扰动向量。第一个部分需要值zj 而第二个部分需要一个映射π将集合{1,…,2K}映射到(i,δ)对。这些都是基于查询点q 的函数。稍后我们将会解释,事实上我们可以预先精确的知道值zj 的分布并对于每个j计算E[(zj)2],所以,我们可以做如下优化:我们通过这个期望来近似值(zj)2。使用这个近似,我们可以事先按顺序计算扰动集合(因为集合的分数是值(zj)2 的函数)。这个生成的过程可以于上一节描述的过程一样,但是使用值E[(zj)2]来替代它们真实的值。这个可以独立于查询点q 完成。在查询时,我们根据查询点q 来计算映射π(每个哈希表是不同的)。这些映射将预先准备好的每个扰动集合转换为扰动向量。这个预先处理的过程减少了在查询时动态生成扰动集合的时间。为了完成这个方法,我们还需要解释如何来获得E[(zj)2]。回顾值zj 是排列好的值xi(δ)中的一个值。注意到xi(δ)时在[0,r]中均匀分布,另外xi(-1)+ xi(1) = w,因为K 个哈希函数中的每一个都是独立选择的,对于j≠i,值xi(δ)独立于值xj(δ)。值zj(j=1,…,K)的联合分布如下所述:随机从均匀分布[0, r/2]中选择K 个数,zj 是这个集合中第j 大的数。这是一个已经被很好地研究过的分布,使用已知的关于这个分布的知识,对于j∈{1,…,K},可以得到:
对于j∈{K+1,…,2K},我们可以得到:
正如先前所述,这些值可以用来预先计算扰动集合的顺序。