[整理]R-学习笔记-入门
下载及相关准备
windows操作系统
R下载:https://www.r-project.org/
Rstudio下载:https://www.rstudio.com/products/rstudio/download/
Linux操作系统 CENTOS
R是已经下好了的 Rstudio wget之后是rpm文件 没有root权限不会编译TAT
学习书籍推荐:https://xccds1977.blogspot.sg/2013/02/r.html
参考资料:http://staff.ustc.edu.cn/~zwp/teach/Stat-Comp/R4beg_cn_2.0.pdf
准备去图书馆借《R in action》...
对象
当R运行时,所有变量、数据、函数及结果都以对象(objects)的形式存在计算机的内存活动中,并冠有相应的名字代号。
对象的内在属性:
类型 mode() 数值型、字符型、复数型、逻辑型
长度 length()对象中元素的数目
> x <- 1
> mode(x)
[1] "numeric"
> length(x)
[1] 1
> x <- "helloworld"; y <- TRUE; Z <- i
Error: object 'i' not found
> x <- "helloworld"; y <- TRUE; Z <- 1i
> mode(x);mode(y);mode(Z)
[1] "character"
[1] "logical"
[1] "complex"对象的操作:
赋值/修改: <-
删除:rm()
> rm(Z)
> ls()
[1] "x" "y"
> rm(list=ls())
> ls()
character(0)Inf:+∞ -Inf:-∞ NaN:非数字
对象的分类:
向量:外在属性dim和长度的区分、
因子(数值型或字符型)、数组、矩阵(二维数组)、
数据框:由一个或几个向量和/或因子构成,必须是登场的,但可以是不同的数据类型、
时间序列:包含频率、时间等额外属性、
列表:可以包含任何类型的对象。
文件读写
R可读取的数据:储存在文本文件(ASCII)中的数据
其他格式文件(Excel、SAS、SPAA)和访问SQL类型的数据库——高级应用
读取:
read.table()
> mydata <- read.table("C:/data/test_data.txt")
#创建一个数据框mydata
Warning message:
In read.table("C:/data/test_data.txt") :
incomplete final line found by readTableHeader on 'C:/data/test_data.txt'
> View(mydata)
#数据框中每个变量被命名,缺省值为V1,V2...
> mydata$V1;mydata["V1"];mydata[,1] #单独访问变量
[1] 1 2 #向量
V1
1 1
2 2 #数据框
[1] 1 2 #向量默认缺省值:
read.table(file, header = FALSE, sep = "", quote = "\"’", dec = ".",row.names, col.names, as.is = FALSE, na.strings = "NA",colClasses = NA, nrows = -1,skip = 0, check.names = TRUE, fill = !blank.lines.skip,strip.white = FALSE, blank.lines.skip = TRUE,comment.char = "#")
| file |
文件名(包含在“”内,或使用一个字符型变量)或者一个URL链接(http://...)(用URL对文件远程访问) |
| header | 反映这个文件的第一行是否包含变量名 |
| sep | 字段分离符 |
| quote | 指定用于存储字符型数据的字符 |
| dec | 用来表示小数点的字符 |
| row.names | 保存着行名的向量,或文件中一个变量的序号或名字,缺省时行号取为1, 2, 3, . . . |
| col.names |
指定列名的字符型向量(缺省值是:V1, V2, V3, . . . ) |
| as.is | 控制是否将字符型变量转化为因子型变量(如果值为FALSE),或者仍将其保留为字符型(TRUE) as.is可以是逻辑型,数值型或者字符型向量,用来判断变量是否被保留为字符 |
| na.strings | 代表缺失数据的值(转化为NA) |
| colClasses | 指定各列的数据类型的一个字符型向量 |
| nrows | 可以读取的最大行数(忽略负值) |
| skip | 在读取数据前跳过的行数 |
| check.names | 如果为TRUE,则检查变量名是否在R中有效 |
| fill | 如果为TRUE且非所有的行中变量数目相同,则用空白填补 |
| strip.white | 在sep已指定的情况下,如果为TRUE,则删除字符型变量前后多余的空格 |
| blank.lines.skip | 如果为TRUE,忽略空白行 |
| comment.char | 一个字符用来在数据文件中写注释,以这个字符开头的行将被忽略(要禁用这个参数,可使用comment.char = "") |
scan()
可用于创建不同的对象,向量,矩阵...
> mydata <- scan("data.dat", what = list("", 0, 0)) #读取了文件data.dat中三个变量,第一个是字符型变量,后两个是数值型变量scan(file = "", what = double(0), nmax = -1, n = -1, sep = "",quote = if (sep=="\n") "" else "’\"", dec = ".",skip = 0, nlines = 0, na.strings = "NA",flush = FALSE, fill = FALSE, strip.white = FALSE, quiet = FALSE,blank.lines.skip = TRUE, multi.line = TRUE, comment.char = "")
| what | 指定数据的类型(缺省值为数值型) |
| nmax | 要读取数据的最大数量,如果what是一个列表,nmax则是可以读取的行数 (在缺省情况下,scan读取到文件最末端为止的所有数据) |
| n | 要读取数据的最大数量(在缺省情况下,没有限制) |
read.fwf():来读取文件中一些固定宽度格式的数据
> mydata <- read.fwf("C:/data/test_data.txt",widths=c(1,5,3,2)
原始数据: 处理后:
![[整理]R-学习笔记-入门_第1张图片](http://img.e-com-net.com/image/info8/2b35f8cbe09b4739b3a47d05d6fd29b7.png)
![[整理]R-学习笔记-入门_第2张图片](http://img.e-com-net.com/image/info8/511e7dfaa22a4647a7ce5c6bf5214c00.png)
存储:
write.table()
> d <- data.frame(obs=c(1,2,3),treat=c("A","B","C"),weight=c(2.3,NA,9))
> write.table(d,file="C:/data/test_data.txt")
> View(d)
> write.table(d,file="C:/data/test_data.txt",row.names=F,quote=F,sep="\t")存储数据: 列表显示:

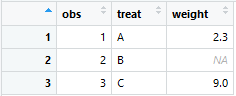
| qppend | 如果为TRUE则在写入数据时不删除目标文件中可能已存在的数据,采取往后添加的方式 |
| quote | 一个逻辑型或者数值型向量:如果为TRUE,则字符型变量和因子写在双引号""中; 若quote是数值型向量则代表将欲写在""中的那些列的列标。 (两种情况下变量名都会被写在""中;若quote = FALSE则变量名不包含在双引号中) |
| row.names | 一个逻辑值,决定行名是否写入文件;或指定要作为行名写入文件的字符型向量 |
| col.names | 一个逻辑值(决定列名是否写入文件);或指定一个要作为列名写入文件中的字符型向量 |
save():保存为R专有的文件格式
> save(d,file="C:/data/test_data.Rdata")
> setwd("C:/data") #定义路径
> load("test_data.Rdata") #加载到内存中