python学习中-廖雪峰教程笔记①(基础数制、数据形式、函数、函数参数、函数迭代)
1、输入

2、数制

浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。


3、布尔值:
只有true和false两个值,可以用and or not 与或非(也是if的判断结果)
4、空值 :None(并不是0)
5、变量:同一个变量可以反复赋值,而且可以是不同的值
变量不固定的语言被叫做动态语言。
也可以把变量赋值给变量(其实是是赋值其中数据)
6、//是地板除 :除完只取整数部分
7、字符串:
ASCII码1个字节,Unicode编码2个字节。UTF-8汉字是3个字节,英文是1个字节。
python3开始支持中文
-ord('')转化成整数
-chr()转化成中文
-\u4245是字符的整数编码等价于一个字
-unicode下的str可以通过.encode('acii')编码为指定的bytes,网络获取的byte可以用.decode('')按照指定的方法解码为unicode
-len计算长度
8、#!/usr/bin那一行是为了告诉linux系统这是一个Python可执行程序
code=utf-8是为了告诉解释器按照utf-8编码读取源代码
7、字符里面带变量输出和C一样有占位符%s('hhh'),还有.format
8、Python的各种数据组:
1>list-['',''] 有序集合,用list[0~n-1]进行访问,list[-1]是倒数第一个。可变,利用append追加元素,insert插入到指定位置,pop删除末尾元素,或者直接对该元素赋值class[1]='new1',元素是什么比较随意(如果也是[]的话就变成二位数组了)
2>tuple-(""),初始化以后不能更改的有序集合。不变指的是指向不变,如果tuple里的list变了那还是会变的。
9、条件判断:
if age>19:
print('your age is ',age)#没有占位符的时候表示就这样输出
elif age<10:
print('更加细致的判断')
else:
print('fuck yourself guys.') #不用分号
如果满足了一个条件,执行完之后就会把后面的跳过了。
注意input进来的量默认str。
格式转换的话 birth=int(s) #int只能用于可实现的整数转换
10、解释器和编译器有什么区别:
https://blog.csdn.net/touzani/article/details/1625760
11、循环(两种)
1>for 变量 in list[]/tuple()
依次迭代list和tuple里的元素
names=['','']
for name in names:
print(name)
2> while 条件判断:只要条件满足,就不断进行循环
while n>0:
n = n - 2
3>
-range(5)生成的是从0到4的整数序列。
-break 提前结束循环
-continue 跳过当前次循环(比如,如果是偶数次,提前结束本轮循环)
-Ctrl+C可以退出程序
12、使用dict和set:
1>dict:字典,也叫map映射关系,key-value存储,查找快速
names =['a','b','c']
scores=[99,12,11]
对应dict d={"a":99,"b":12,"c":11}
-直接取d['a']即可/或者用=来赋值
-用 'a' in d来判断
-d.get可以取得值,也可以返回none或者指定值 d.get('a',-1)
-d.pop('a')也可以把a删除
-key必须是不可变对象(不可以是列表)
2>set ,是key的集合,但是不存储value,因为key不能重复,所以set也不可重复。(无序不可重复集合)
-set的创建可以基于一个list s= set([1,23,2,1,2])
-s.add(key) (key就是任意想让它当key的值) ,可以添加值到set中
-s.remove(key)可以移除一个元素
-不可以加入可变对象(list)
13、对于一个字符串a而言,我们使用了a.repalce('a','A')时,实际调用方法是作用在字符串对象上的,作用完以后返回了新的对象‘A’,但是没有改变‘a’的内容。这个时候用b=a.replace,b会再次指向新字符串。
-对于不变对象而言,调用对象自身的任意方法,不会改变对象自身的内容。相反,这些方法会创建新的对象然后返回,就保证了不可变对象永远不可变。
-(1,2,3)是不可变对象,(1,2,[3,2])不是
14、函数:
1>抽象:函数也是一种抽象方式,帮助我们在跟高的角度思考问题。
2>调用名:知道函数名就可以调用。可以从Python3官方文档查看:
http://docs.python.org/3/library/functions.html#abs
3>函数名就是一个函数对象的引用,可以把函数名赋值给一个变量,相当于给了函数一个别名。
4>定义:
def myFun():
if x>1:
return x; #函数的返回值,并且执行到return时认为函数执行完毕,如果没有return语句则默认返回none,也可以只写一个return。
-出现...是正在定义函数,按两次回车可以回到界面
-如果我已经把def定义的函数保存在file.py中,我可以在同一个目录下使用from file import func来导入这个函数了
-如果想定义一个什么也不用做的操作,就用pass(用来做之后要补充的函数的占位符)
-Python会替你进行参数个数检查,但是类型检查不出来(需要我们自己做定义),具体的定义方法:
def my_abs(x):
if not isinstance(x,(int, float)):
raise TypeError('bad operand type')
5>返回多个值:
def move (x,y)
return nx,ny
使用:
x,y=move(1,2)
或者用一个变量接着,返回值其实是一个tuple
6>函数的参数:必选参数,默认参数,可变参数,关键字参数。
-位置参数:
def power(x,n):
return x*x+n #此时的x和n是位置参数,会按照传入时写的位置依次把值赋予参数x和n
-默认参数:
def power(x,n=2):
同上 #这个情况下,只传入x的值也可以。
设置默认参数的时候需要注意的点:
·必选在前,默认在后,否则会报错(因为是按照位置进行判断的)
·变化大的参数放在前,变化小的参数放后面(做默认参数,因为经常可能是同一个值)
·如果要不按顺序提供默认参数的话就,power(1,n='aaa')#特地告诉解释器我是要传n的参数
·记住默认参数必须指向不变对象!不然每次发生的改变会被留下来,具体示例如下:
默认参数很有用,但使用不当,也会掉坑里。默认参数有个最大的坑,演示如下:
先定义一个函数,传入一个list,添加一个END再返回:
def add_end(L=[]):
L.append('END')
return L
当你正常调用时,结果似乎不错:
>>> add_end([1, 2, 3])
[1, 2, 3, 'END']
>>> add_end(['x', 'y', 'z'])
['x', 'y', 'z', 'END']
当你使用默认参数调用时,一开始结果也是对的:
>>> add_end()
['END']
但是,再次调用add_end()时,结果就不对了:
>>> add_end()
['END', 'END']
>>> add_end()
['END', 'END', 'END']
很多初学者很疑惑,默认参数是[],但是函数似乎每次都“记住了”上次添加了'END'后的list。
原因解释如下:
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
定义默认参数要牢记一点:默认参数必须指向不变对象!
要修改上面的例子,我们可以用None这个不变对象来实现:
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L
现在,无论调用多少次,都不会有问题。
·为什么要设计None,str这样的不变对象,因为不变对象一旦被创建,内部的数据就不可以修改,就减少了由于修改数据导致的错误,此外,由于对象不变,多任务环境下读取对象不需要加锁,可以并行读,所以如果可以设计成不变对象尽量设计成不变对象。
-可变参数
可变参数就是传入的参数个数是可变的,可以是1、2到任意甚至0个。
如果传入一个list或者tuple的时候可以写成这样:
def calc(numbers):
sum=0
for n in numbers:
sum=sum+n*n
return sum
但是调用的时候需要自己先组装好tuple或者是list(就在这种部分所有的参数都会被接受的,但是要接收进来对运算进行判断运算能不能接受这个函数,除非自己写一个预判断的函数)
如果是可变参数方法的话:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum +n*n
return sum
这个时候调用只要写calc(1,2,3)就可以了。
在函数内部,接收到的是一个tuple,但是此时可以传入任意参数了,包括0个。
如果有一个list想调用可变参数的话,用cal(list[0],list[1],list[2])或者说cal(*list)就行,*list表示把list的所有元素作为可变参数传入,这种写法相当有用而且常见。
-关键字参数
可变参数允许传入0或者任意参数,自动组装成tuple。而关键字参数允许你传入0个或者任意个含有参数名的参数,这些关键字参数在函数内部自动组装成一个dict,比如:
def person(name,age,**kw):
print(name,age,kw)#此处的kw就是关键字参数
可以只传入前两个必选参数,这样的话最后一个会显示为{}
或者要传入关键字参数的话:person('xiaohua',12,city='qingdao')
输出会这样: xiaohua,12,{'city':'qingdao'}
·关键字参数的作用:可以扩展功能。
可以利用提取出字典然后传入的办法传入dict,也可以直接用简化写法person('xiaohua',12,**extra)传入dict
extra = {'city':'qingdao','job':'engineer'}
·如果要在函数里检查传入进来的有没有某参数的话就
if 'city' in kw:
#有city参数
pass
·如果要限制关键字参数的名字,可以使用命名关键字参数,比如
def person(name,age,*,city,job):
print(city)
和**kw不同,命名关键字需要一个特殊分隔符*,*后的参数被看成关键字参数,然后比如*args这种可变参数后面的参数也会都被看出关键字参数(只能传入字典才行),命名关键字也可以设置默认值
·记住没有可变函数的话一定要加*做分隔符,如果没有是没办法识别的
-参数组合
组合顺序:必选参数、默认参数、可变参数、命名关键字、关键字
比如说
def f1(a,b,c=0,*args,**kw):
def f2(a,b,c=0,*,d,**kw)
使用方法:
也可以通过一个tuple和一个dict调用:
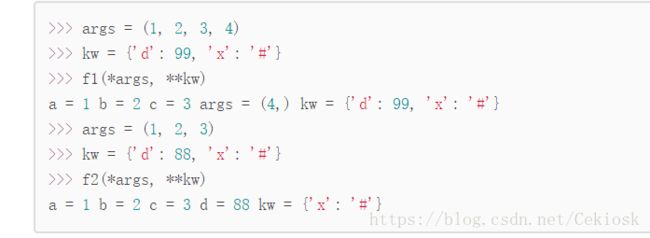
对于任意函数,都可以通过类似func(*args,**kw)的形式调用它,但是参数组合还是别写太多不然容易混淆。
6>递归函数:
如果一个函数在内部调用自身本身,这个函数就是递归函数。
def fact(n):
if n==1:
return 1
return n * fact(n - 1)使用递归函数要防止栈溢出,在计算机中,函数调用是通过栈这种结构实现的,每当进入一个函数调用,栈就增加一层栈帧,每当函数返回,就减一层。
解决递归调出栈溢出的办法是通过尾递归优化,实际上尾递归和循环的效果是一样的,所以,把循环看成一种特殊的尾递归函数是也是可以的。
尾递归是指,函数返回的时候,调用自身本身,并且return不包含表达式,这样解释器就会做优化,使得递归不管多少次,都只会占用一个栈帧,不会出现栈溢出。
如果对上面的代码做出改动的话,就是注意把每一步的乘积传入到递归函数中:
def fact(n):
return fact_iter(n,1)
def fact_iter(num,product):
if num == 1:
return product
return fact_iter(num - 1,num* product)
#仅返回递归函数本身,num-1和num*product在调用前就会被计算,不影响函数调用
#无论多少次,栈也不会增加 但是python语言没有这种优化,要小心栈溢出问题-递归的考虑方法,就是从宏观上来考虑,细节问题交给下一个递归。