darknet源码解读-forward_region_layer
讨论forward_region_layer函数的话我们把它放在yolov2场景下,因为[region]层是yolov2的一大特色,所以函数中用到的一些参数也是参考的cfg/yolov2.cfg的默认参数配置。在yolov2网络中,经过前向传播最后会落到region层,而相应的处理函数便是forward_region_layer。yolov2的精髓集中于此,十分重要,同时理解起来也不那么容易。考虑到整体代码比较长,我逐段进行分析。
void forward_region_layer(const layer l, network net)
{
int i,j,b,t,n;
//l.outputs仅是一张图最终feature map的元素个数,所以还得乘以个l.batch
memcpy(l.output, net.input, l.outputs*l.batch*sizeof(float));
#ifndef GPU
for (b = 0; b < l.batch; ++b){
for(n = 0; n < l.n; ++n){
int index = entry_index(l, b, n*l.w*l.h, 0);
//why 2?2就是表示只对(x,y)进行了激活,有没有想到什么,对!
//就是论文中的那个bx = sigmoid(tx)+cx,作者就是在这里对
//tx做sigmoid处理的
activate_array(l.output + index, 2*l.w*l.h, LOGISTIC);
//skip coords(e.g. 4)
index = entry_index(l, b, n*l.w*l.h, l.coords);
//activate confidence
if(!l.background) activate_array(l.output + index, l.w*l.h, LOGISTIC);
//skip coords+confidence
index = entry_index(l, b, n*l.w*l.h, l.coords + 1);
//activate classes
if(!l.softmax && !l.softmax_tree) activate_array(l.output + index, l.classes*l.w*l.h, LOGISTIC);
}
}
if (l.softmax_tree){
//省略
} else if (l.softmax){
//省略
}
#endif
只考虑CPU的情形,所以会进入这两层for循环。
static int entry_index(layer l, int batch, int location, int entry)
{
int n = location / (l.w*l.h);
int loc = location % (l.w*l.h);
return batch*l.outputs + n*l.w*l.h*(4+l.classes+1) + entry*l.w*l.h + loc;
}这里面entry_index的计算得说道说道,不然后面都没法理解。简单起见,我就假定如下几个参数:最后一层输出的宽(l.w)和高(l.h)为3,每个网格单元的anchor box数为5(n),分类数为20。因此,对于一张图像来说最终的feature map为3x3x125。为啥是125?这个理解yolov2的应该都懂的,125=5*(4 + 1 + 20)。三维到一维的映射关系,通过下面这种图应该看得明白了。
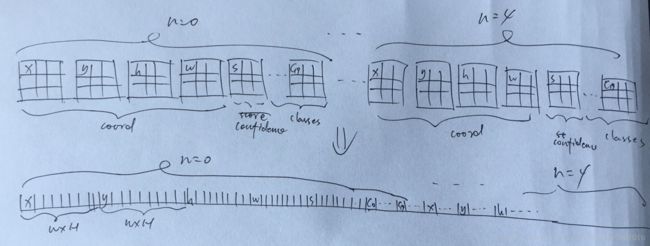
激活完成后是一些变量的初始化,这个好理解。
//clear gradient
memset(l.delta, 0, l.outputs * l.batch * sizeof(float));
if(!net.train) return;
float avg_iou = 0;
float recall = 0;
float avg_cat = 0; //average class recognition ratio
float avg_obj = 0;
float avg_anyobj = 0;
int count = 0;
int class_count = 0;
*(l.cost) = 0;然后进入真正的大头了。
for (b = 0; b < l.batch; ++b) {
if(l.softmax_tree){ //no execution
//省略
}
for (j = 0; j < l.h; ++j) {
for (i = 0; i < l.w; ++i) {
for (n = 0; n < l.n; ++n) {
//cell(j,i)上第n类anchor上对应box的索引,注意这个解码的顺序
int box_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, 0);
//cell(j,i)上第n类anchor的预测box相对于整张feature map的位置和大小
box pred = get_region_box(l.output, l.biases, n, box_index, i, j, l.w, l.h, l.w*l.h);
//cell(j,i)上的每一类anchor的预测box,都要遍历一遍所有的truth box,
//找到与预测box IoU最好的truth box
float best_iou = 0;
for(t = 0; t < 30; ++t){
//get (x,y,w,h,c) of truth box
box truth = float_to_box(net.truth + t*(l.coords + 1) + b*l.truths, 1);
if(!truth.x) break;
float iou = box_iou(pred, truth);
if (iou > best_iou) {
best_iou = iou;
}
}
//cell(j,i)上第n类anchor的预测confidence的索引,l.coords通常是4,因为要跳过(x,y,w,h)
int obj_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, l.coords);
avg_anyobj += l.output[obj_index]; //表示有目标的概率
//所有的predict box都当做noobject,计算其损失梯度,主要是为了计算速度考虑
l.delta[obj_index] = l.noobject_scale * (0 - l.output[obj_index]);
//no execution
if(l.background) l.delta[obj_index] = l.noobject_scale * (1 - l.output[obj_index]);
//best_iou大于阈值说明该预测框中有目标
if (best_iou > l.thresh) {
l.delta[obj_index] = 0;
}
//what's meaning?why 12800?
//可能为了在训练前期能够让预测框尽快学到先验框(anchor box)的形状,
//所以这里的truth就直接用了anchor box
if(*(net.seen) < 12800){
box truth = {0};
//当前cell(i,j)为中心对应的第n类anchor box(先验box)
truth.x = (i + .5)/l.w;
truth.y = (j + .5)/l.h;
truth.w = l.biases[2*n]/l.w; //相对于feature map的大小,tw=0
truth.h = l.biases[2*n+1]/l.h; //th=0
//将预测的tx,ty,tw,th和上面的box差值存入l.delta
delta_region_box(truth, l.output, l.biases, n, box_index,
i, j, l.w, l.h, l.delta, .01, l.w*l.h);
}
}
}
}最外层的大循环执行net->batch,好理解嘛,一张图像一次。内部紧接着的三3层for循环针对的是最终feature map上的每一个网格单元。按照yolov2的逻辑,根据Anchor box的数量n,在每个网格单元上有n组预测box输出。entry_index获取的是在cell(j,i)上第n个预测box在一维数组b上的起始索引。有了这个索引,再结合步长stride等信息,我们就可以计算出cell(j,i)第n个预测box的4个坐标(w,y,h,w),这一步在get_region_box函数中完成。
box get_region_box(float *x, float *biases, int n, int index, int i, int j, int w, int h, int stride)
{
box b;
b.x = (i + x[index + 0*stride]) / w;
b.y = (j + x[index + 1*stride]) / h;
b.w = exp(x[index + 2*stride]) * biases[2*n] / w;
b.h = exp(x[index + 3*stride]) * biases[2*n+1] / h;
return b;
}理解这个函数还是得结合论文来看,论文中相关段我摘取了下来。

(i,j)是相当于feature map左上角的横纵坐标(Cx,Cy),x[index + 0*stride])和x[index + 1*stride]对应的是![]() 和
和![]() ,与faster-rcnn不同之处就在于这个sigmoid函数的引入,它限定了预测box的中心只在能cell(j,i)这个网格单元中。得到的(x,y,w,h)针对feature map的宽高(w,h)做了归一化。在拿到cell(j,i)上第n类预测box后要和已知的所有ground truth box进行IoU计算,得到最大的IoU值赋给best_iou。这个best_iou会与配置文件中设定的阈值l.thresh进行对比,只要当best_io大于l.thresh的时候才该预测box中包含有目标。前12800张训练图片,为了让预测box尽快学到anchor box的形状,直接把truth中的(x,y,w,h)设置成anchor box的坐标,将预测box和anchor box的差值存入到l.delta中。
,与faster-rcnn不同之处就在于这个sigmoid函数的引入,它限定了预测box的中心只在能cell(j,i)这个网格单元中。得到的(x,y,w,h)针对feature map的宽高(w,h)做了归一化。在拿到cell(j,i)上第n类预测box后要和已知的所有ground truth box进行IoU计算,得到最大的IoU值赋给best_iou。这个best_iou会与配置文件中设定的阈值l.thresh进行对比,只要当best_io大于l.thresh的时候才该预测box中包含有目标。前12800张训练图片,为了让预测box尽快学到anchor box的形状,直接把truth中的(x,y,w,h)设置成anchor box的坐标,将预测box和anchor box的差值存入到l.delta中。
for(t = 0; t < 30; ++t){
box truth = float_to_box(net.truth + t*(l.coords + 1) + b*l.truths, 1);
if(!truth.x) break;
float best_iou = 0;
int best_n = 0;
//强制转换,将该truth box对应的cell(j,i)坐标给找出来
i = (truth.x * l.w);
j = (truth.y * l.h);
box truth_shift = truth;
truth_shift.x = 0;
truth_shift.y = 0;
for(n = 0; n < l.n; ++n){
int box_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, 0);
box pred = get_region_box(l.output, l.biases, n, box_index, i, j, l.w, l.h, l.w*l.h);
if(l.bias_match){
//因为是和anchor比较,所以直接使用anchor的相对大小
pred.w = l.biases[2*n]/l.w;
pred.h = l.biases[2*n+1]/l.h;
}
pred.x = 0;
pred.y = 0;
//如果l.bias_match为真的话,那这里就不是拿5个anchor box与
//cell(i,j)位置的truth box计算iou,选出最优anchor box,而是
//会使用该anchor的预测box计算与真实box的误差
float iou = box_iou(pred, truth_shift);
if (iou > best_iou){
best_iou = iou;
best_n = n;
}
}
int box_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, 0);
//这里坐标loss的权重为什么这么设置?这里相当于根据ground truth的大小对权重
//系数进行了修正,对于尺度较小的boxes,其权重系数会更大一些.在yolov1中,是通过
//平方根来达到类似的效果
float iou = delta_region_box(truth, l.output, l.biases, best_n, box_index,
i, j, l.w, l.h, l.delta, l.coord_scale * (2 - truth.w*truth.h), l.w*l.h);
//no execution
if(l.coords > 4){
int mask_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, 4);
delta_region_mask(net.truth + t*(l.coords + 1) + b*l.truths + 5,
l.output, l.coords - 4, mask_index, l.delta, l.w*l.h, l.mask_scale);
}
if(iou > .5) recall += 1;
avg_iou += iou;
//best predict box confidence
int obj_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, l.coords);
avg_obj += l.output[obj_index];
//有目标时的损失,此时预测概率当然越大越好
l.delta[obj_index] = l.object_scale * (1 - l.output[obj_index]);
if (l.rescore) {
//为true表示同时对confidence进行回归(regression score?),用iou取代了上面的1
l.delta[obj_index] = l.object_scale * (iou - l.output[obj_index]);
}
//no execution
if(l.background){
l.delta[obj_index] = l.object_scale * (0 - l.output[obj_index]);
}
//真实类型
int class = net.truth[t*(l.coords + 1) + b*l.truths + l.coords];
if (l.map) class = l.map[class];
//预测的class向量首地址
int class_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, l.coords + 1);
//类别损失
delta_region_class(l.output, l.delta, class_index, class, l.classes,
l.softmax_tree, l.class_scale, l.w*l.h, &avg_cat, !l.softmax);
++count;
++class_count;
}
}最后一步是计算损失。
//sum-squared error
*(l.cost) = pow(mag_array(l.delta, l.outputs * l.batch), 2);
printf("Region Avg IOU: %f, Class: %f, Obj: %f, No Obj: %f, Avg Recall: %f, count: %d\n", avg_iou/count, avg_cat/class_count, avg_obj/count, avg_anyobj/(l.w*l.h*l.n*l.batch), recall/count, count);