基于多表频繁项投票和桶映射链的快速检索方法 文章阅读
高毫林, 彭天强, 李弼程,等. 基于多表频繁项投票和桶映射链的快速检索方法[J]. 电子与信息学报, 2012, 34(11):2574-2581.
文章创新点:在 E2LSH(Exact Euclidean Locality Sensitive Hashing)的基础上提出了基于多表频繁项投票和桶映射链的快速检索方法。
本文采用多哈希表投票法减弱算法的随机性,它的核心思想是把多个哈希表的检索结果写成矩阵,计算矩阵的频繁项,也就是在多个表中出现频次较高的检索结果。这样使得检索信息得以综合利用。
具体实现步骤:根据检索向量构造基准索引向量,然后由基准索引向量构造基准索引矩阵,再对基准索引矩阵进行频繁项投票得出准最终索引,最后对准最终索引进行校正得出接近真实情况的最终索引。
多表频繁项投票法减弱随机性主要分为以下几步:
(1)通过AP(Average Precision)值及检出率从多个表中选取基准索引向量。
基准索引向量:AP值和recall值较高的某几个查询结果;
非基准索引向量:AP值和recall值较低的某几个查询结果;
注:一个哈希表获得一个查询结果(图像序号的排序)。L个哈希表获得L次查询结果,这些查询结果根据AP值的高低分为基准索引向量和非基准索引向量。
由于检出个数及排序情况不同,仅仅利用AP值的高低难于直接反映检索结果的优劣。可以选取AP较高的结果,再在此基础上选取检出率较高的结果作为最终索引的基准索引向量。
(2)构造基准索引矩阵。
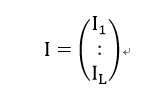
- 矩阵每一行对应于一个表的检索结果。对第L 个表进行检索的结果记为ILxn
 ,xn
,xn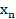 表示图像在图像集的初始序号。xn
表示图像在图像集的初始序号。xn ∈ [1,N], N表示图像集的图像数目。
∈ [1,N], N表示图像集的图像数目。 - 数学含义:矩阵第一行第一列:第一个哈希表获得的和查询图像距离最近的检索图像序号;矩阵第一行第二列:第一个哈希表获得的和查询图像距离第二近的检索图像序号;矩阵第二行第一列:第二个哈希表获得的和查询图像距离最近的检索图像序号;
由于上述基准索引向量的长度可能不同,所以需要对部分基准索引向量进行补零。补零的位置通过计算修正最小编辑距离(Modified Minimum Edit Distance, MMED)确定。MMED是指将一个向量在不同位置插入某元素补成与另外一个向量等长后两者编辑距离的最小值。
(3)计算基准索引矩阵频繁项。
对矩阵每一列进行投票的方式得出,也就是统计矩阵每列各元素频次,将出现次数最多的元素(频繁项)作为最终结果。

第 2 行表示频繁项频次,获得 准最终索引为(18 19 21 25 28 26 20 22 … 36 38)。从左到右被认为是相似性越来越弱。
(4)用非基准索引向量对准最终索引进行索引校正,也就是寻找这些频繁项在非基准索引向量中的相对位置,来确定最终索引,这样就充分利用了距离保持信息。
一般情况下,上一步获得的准最终索引就是最后的索引结果。
方法评价:
优点:利用到了多个表的查询结果,对其进行了融合
缺点:
在第三步“计算基准索引矩阵频繁项”过程中按照“按当前列取频次最高的图像”,
问题一:有可能会出现重复,也就是说在不同的两列获得相同的图像序号
问题二:有可能出现某图像序号在某一列出现的次数不是最多的,但是它在已经被检索到了。具体解释如下例子。
例:如下图所示是通过1,2两个步骤获得的待投票矩阵,图中数字均代表图像的序号,每一行表示一次查询结果。

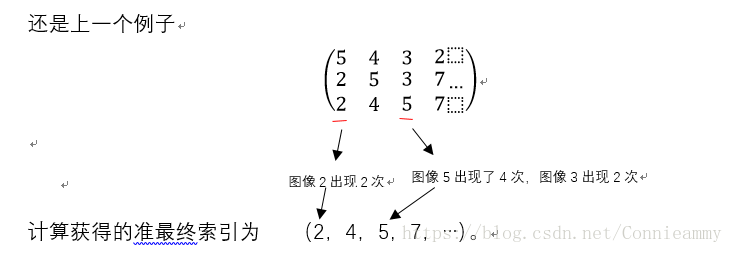
如果按照上述方法的话,计算获得的准最终索引为(2,4,3,7,…),但是其实图像5出现的次数很多,并且在很早就被检索出来,但是在这个矩阵中却被忽视了。
对于重复项的问题提出一个改进方案:
前两步同上,改进第三步。
(1)通过AP(Average Precision)值及检出率recall从多个表中选取基准索引向量。
(2)构造基准索引矩阵。
(3)计算基准索引矩阵频繁项。
在确定索引时“求之前列和当前列中出现频次最高的图像”。
还是上一个例子
改进方法总结:
把多个哈希表的检索结果写成矩阵,矩阵每一行对应于一个表的检索结果,计算矩阵的频繁项(按照“求之前列和当前列中出现频次最高的图像”),综合利用多个表的检索结果作为最终的检索结果。
该方法用L个哈希表建立L个词典,依据每个词典获得一次检索的结果,最后求频繁项整合多次检索结果。
对于LSH和bow模型有兴趣的同学,或者对于文章有异议的朋友可以加我的QQ:2634272313