欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~
作者:段石石
前言
前段时间,因为项目需求, 开始接触了NLP,有感自己不是科班出身,很多东西理解不深,于是花时间再读了一些NLP的经典教程的部分章节,这里是第一部分,主要包括三小块:中文分词、词向量、词性标注, 这三块是前段时间项目上有用到过,所以稍做总结与大家分享下,只有更极致地深入了解才能学习得更多。
分词
分词可能是自然语言处理中最基本的问题,在英文中,天然地使用空格来对句子做分词工作,而中文就不行了,没有特点符号来标志某个词的开始或者结尾,而分词通常对语义的理解是特别重要的,这里举个栗子:
下雨天留客天留我不留==>下雨天 留客天 留我不留
==>下雨 天留客 天留我不留不同的分词,会造成完全不同的语义理解,其重要性不明而喻,那么如何把词从句子中正确地切分出来呢?
我爱北京天安门分成我 爱 北京天安门 而不是 我爱 北 京天安门? 对于计算机而已,天安门和京天安门都是二进制存储在硬盘或者内存中,没有其他差别,那么我们如何让计算机知道切分为天安门而不是京天安门呢? 这里我们需要提到词典的帮助,做过NLP的小伙伴通常都知道在一些基础任务上,词典的好坏决定最后的性能指标,那么词典是如何对分词起作用的呢?
分词词典
最简单的一个想法,是构造一个常用词的候选集合,如我、爱、天安门、北京这些词,然后从句子头到尾遍历,如何词在候选集合中出现过则切分该词,那么很容易将我爱天安门分词为我 爱 天安门,这样的逻辑很容易理解,所以接下来就是如何去设计这个候选集合的数据结构,常用的list,当然是可以的,但是很明显,将一个海量词的词典载入,词典元素的查找还有存储,如果使用list必然会存在很严重的性能问题,如果高效地存储词典,还有高效地查询词或者短语在词典中,是这部分分词最重要的工作,Trie树在自然语言处理词库的存储和查找上使用的比较普遍。
Trie树存储及最长匹配法
Wikipedia上对于Trie树是这样解释的:在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
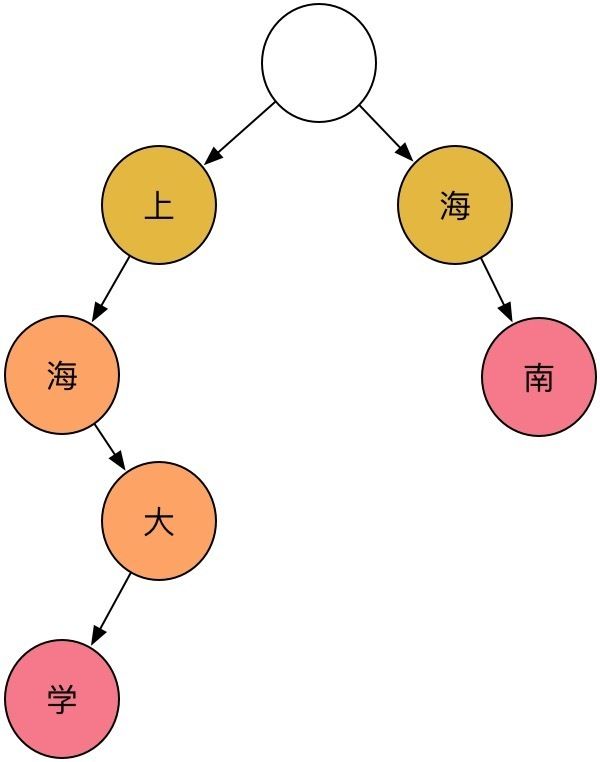
图中主要包括三种节点:开始节点、中间节点、和结束节点,利用Trie树存储后,根据一条路径上来存储一个词典的词如上海大学、当然中间节点也可以做为一个词的结尾来保存如上海,常用的中文字不到5000,大概只需要一个一层分支为2^12的Trie树来保存所有的中文词库信息,树形的结构,保证了高效的存储和查找方法,遍历sentence时,只需要依次向树下一层访问,如果无法访问到下一节点,则切分,如到叶子节点,也切分即可,这就是基于Tire树的最长匹配法,分词性能的好坏完全依赖于词库。 具体的实现可以读下cppjieba的MPSEGMENT的部分https://github.com/yanyiwu/cp... ,这里主要关注下Calc和CutByDag即可比较好的理解。 Trie树的更高效的实现方式包括三数组Trie和二数组Trie,三数组Trie结构包括三个数组结:base,next和check;二数组Trie包含base和check两个数组,base的每个元素表示一个Trie节点,而check数组表示某个状态的前驱状态,高效Trie树的实现,大家有兴趣可以拿源码来读读,这里我先略过。
基于HMM的分词方法
基于Trie Tree的分词方法,主要依赖词典,通常能满足大部分场景,但是很多时候也会效果不好,通常会引入概率模型来做分词,隐性马尔科夫模型通过引入状态见的概率转换,来提高分词的效果,尤其是对未登录词效果要好很多。 相信大家在很多场景下听过HMM,HMM的基本部分包括状态值集合、观察值集合、状态转移矩阵、条件概率矩阵、初始化概率。
这里稍微解释下这五个术语在分词中是啥意思:
- 状态值序列,这里一般有四种状态:B:Begin, M:Middel, E:End, S:single,对于一个待分词序列:大家都爱北京天安门对应的状态序列为BESSBEBME,这样就很容易切分为:BE S S BE BME。
- 观察值序列,指的就是待切分的词,如:我爱北京天安门;
- 初始化概率,指的是BMES这四种状态在第一个字的概率分布情况;
- 状态转移矩阵,在马尔科夫模型里面十分重要,在HMM中,假设当前状态只与上一个状态有关,而这个关系我们可以使用转移矩阵来表示,在这里我们是一个44的矩阵;
- 条件概率矩阵,HMM中,观察值只取决于当前状态值(假设条件),条件概率矩阵主要建模在BMES下各个词的不同概率,和初始化概率、状态转移矩阵一样,我们需要在语料中计算得到对应的数据。
举个例子来说明下: 如大家都爱北京天安门,我们初始化一个weight4,则数组第一列值为初始化概率条件概率集,依次为:P(B)P(大|B),P(E)P(大|E),P(M)P(大|M),P(E)*P(大|E)。然后根据转移概率计算下一个字的状态概率分布:weightk + _transProbk +_emitProbj],依次到最后即可,即可计算句子中所有词的状态分布,然后确定好边界对比条件,即可计算出对应状态序列。 HMM是中文分词中一种很常见的分词方法,由上述描述我们知道,其分词状态主要依赖于语料的标注,通过语料初始化概率、状态转移矩阵、条件概率矩阵的计算,对需要分词的句子来进行计算,简单来说,是通过模型学习到对应词的历史状态经验,然后在新的矩阵中取使用。HMM的模型计算简单,且通常非常有效,对词典中未出现词有比较好的效果。
更复杂的概率分词模型:CRF
这里我们提到的CRF,不是广义的CRF,而是线性链式CRF,和HMM一样,CRF的分词问题,同样是一个序列标注问题,将BEMS标注到句子中的不同词上,相对与HMM,CRF能够利用更多特征,数学原理不讲啦,都是图加概率模型的解释,有兴趣的可以去看下
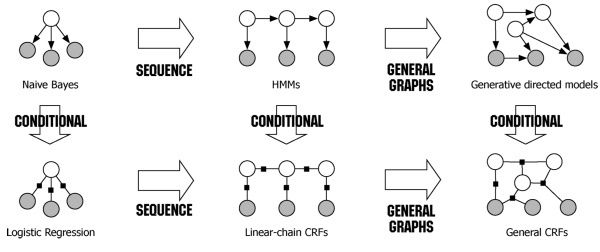
和HMM不同的是,HMM描述的是已知量和未知量的一个联合概率分布,属于generative model,而CRF则是建模条件概率,属于discriminative model。另外CRF特征更加丰富,可通过自定义特征函数来增加特征信息,通常CRF能建模的信息应该包括HMM的状态转移、数据初始化的特征,CRF理论和实践上通常都优于HMM,CRF主要包括两部分特征:一,简单特征,只涉及当前状态的特征;二,转移特征,涉及到两种状态之间的特征;特征模板的说明可以看下 https://taku910.github.io/crfpp/
深度学习在分词上的尝试: bi-lstm+crf

基本做法包括:首先,训练字向量,使用word2vec对语料的字训练50维的向量,然后接入一个bi-lstm,用来建模整个句子本身的语义信息,最后接入一个crf完成序列标注工作,bi-lstm+crf可以用来完成分词、词性标注这类的工作。 这个我会在之后做一些相关的尝试。
词向量
词向量是在NLP中比较基础的一个工作,相对计算机而言,人要聪明的多,人很容易明白幸福和开心是两个比较近的词,而计算机要想了解,其实是很难的,而在现代计算机中,对语言的理解显得越来越重要,如何去表示一个词,也成为了理解语言的基础。
one-hot编码
One-hot编码可能是最简单的一种编码方法,每个词只在对应的index置1,其他位置都是0,One-hot编码的问题在于很难做相似度计算,在大规模语料上时,One-hot编码的长度可能为几十万、几百万甚至更大,One-hot编码显然不行;
矩阵分解方法(LSA)
"You shall know a word by the company it keeps" --Firth, J. R针对一个词来说,它的语义由其上下文决定。 LSA使用词-文档矩阵,矩阵通常是一个稀疏矩阵,其行代表词语、其列代表文档。词-文档矩阵表示中的值表示词在该文章出现的次数,通常,我们可以简单地通过文档的出现次数分布来表示对应的词,但是由于这个矩阵通常是比较稀疏的,我们可以利用矩阵分解,学习到对应词的低秩表示,这个表示建模了文档中词的共现关系,让相似度的计算变得更加容易。 同理,可以也可以在更小粒度上计算矩阵的构建,如设定指定窗口大小,若在该窗口内出现,则数值加一,构建好词-词共现矩阵,最终使用如svd这类的矩阵分解方法即可。 这类方法明显的弊病在于当copur过大时,计算很消耗资源,且对于未出现词或者新文档不友好。
Word2Vec
关于Word2vec有很多很好的学习资料,大致包括CBOW和Skip-gram模型,其中CBOW的输入就是上下文的表示,然后对目标词进行预测;skip-gram每次从目标词w的上下文c中选择一个词,将其词向量作为模型的输入。之前有写Word2vec的文章可以简单看看Stanford CS224d笔记之Word2Vec.
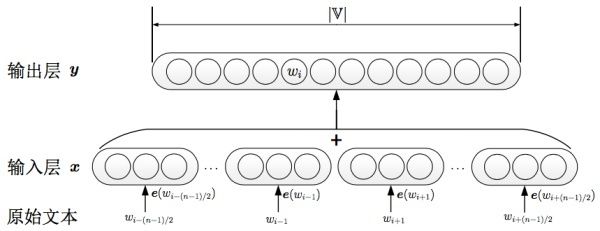
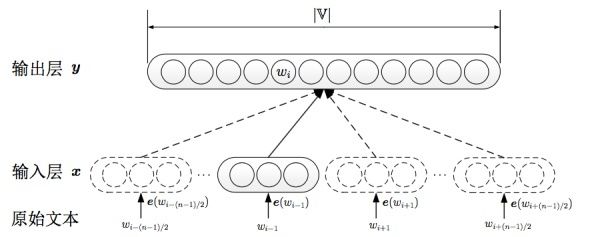
其中skip-gram主要由包括以下几块:
- 输入one-hot编码;
- 隐层大小为次维度大小;
- 对于常见词或者词组,我们将其作为单个word处理;
- 对高频词进行抽样减少训练样本数目;
- 对优化目标采用negative sampling,每个样本训练时,只更新部分网络权重。
Glove
Glove实际上是结合了矩阵分解方法和Window-based method的一种方法,具体看下中公式2-7的推导,Glove的优势主要在于:
- skip-gram利用local context,但是没有考虑大量词共现的信息,而文中认为词共现信息可以在一定程度上解释词的语义,通过修改目标函数,z
- 作者认为相对于原始的额条件概率,条件概率的比值更好地反映出词之间的相关性,如下图:

- 为保证神经网络建模线性结构关系(神经网络容易建模非线性关系,容易欢笑线性关系),对词差值建模,并且增加一个权重函数;
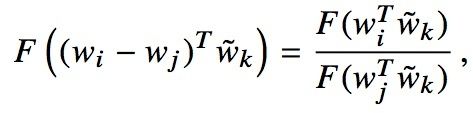
- 使用AdaGrad:根据参数的历史梯度信息更新每个参数的学习率;
- 为减少模型复杂度,增加假设词符合幂率分布,可为模型找下界限,减少参数空间;
NNLM

如上图,早在2001年,Bengio就使用神经网络学习语言模型,中间可输出词向量,NNLM和传统的方法不同,不通过计数的方法对n元条件概率估计,而是直接通过神经网络结构对模型求解,传统的语言模型通常已知序列,来预测接下来的出现词的可能性,Bengio提出的nnlm通过将各词的表示拼接,然后接入剩下两层神经网络,依次得到隐藏层h和输出层y,其中涉及到一些网络优化的工作,如直连边的引入,最终的输出节点有|V|个元素,依次对应此表中某个词的可能性,通过正向传播、反向反馈,输入层的e就会更新使得语言模型最后的性能最好,e就是我们可拿来的向量化的一种表示。
知识表示
知识表示是最近开始火起来的一种表示方式,结合知识图谱,实体之间的关系,来建模某个实体的表示,和NLP里的很类似,上下文通常能表征词的关系,这里也是一样,结合知识图谱的知识表示,不仅考虑实体间链接关系,还可以通过引入更多的如text、image信息来表征实体,这里可以关注下清华刘知远老师的相关工作。
词性标注
词性标注的相关学习路线,基本可以重搬下分词相关的工作,也是一个词性标注的工作
- 基于最大熵的词性标注
- 基于统计最大概率输出词性
- 基于HMM词性标注
- 基于CRF的词性标注 可以稍微多聊一点的是Transformation-based learning,这里主要参考曼宁那本经典的NLP教材 Transformation-based learning of Tags, Transformation 主要包括两个部分:a triggering environment, rewrite rule,通过不停统计语料中的频繁项,若满足需要更改的阈值,则增加词性标注的规则。
总结
从来都认为基础不牢、地动山摇,后面会继续努力,从源码、文章上更深了解自然语言处理相关的工作,虽然现在还是半调子水平,但是一定会努力,过去一段时间由于工作相对比较忙,主要还沉沦了一段时间打农药,后面会多花点时间在技术上的积淀,刷课、读paper、读源码。另外,为了加强自己的coding能力,已经开始用cpp啦(周六写了500+行代码),想想都刺激,哈哈哈!!!我这智商够不够呀,anyway,加油吧!!!
2017-10-22: 个人博客,出了点问题,貌似是因为七牛图床需要再搞个啥备案,看来以后博客要费啦!!!
哎, 真麻烦
阅读推荐
一站式满足电商节云计算需求的秘诀
LSF-SCNN:一种基于 CNN 的短文本表达模型及相似度计算的全新优化模型
循环神经网络(Recurrent Neural Networks)简介
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:
https://cloud.tencent.com/com...