定义
PV是page view的缩写,即页面浏览量,通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。网页浏览数是评价网站流量最常用的指标之一,简称为PV
UV是unique visitor的简写,是指通过互联网访问、浏览这个网页的自然人。
通过以上的概念,可以清晰的看出pv是比较好设计的,网站的每一次被访问,pv都会增加,但是uv就不一定会增加了,uv本质上记录的是按照某个标准划分的自然人,这个标准其实我们可以自己去定义,比如:可以定义同一个IP的访问者为同一个UV,这也是最常见的uv定义之一,另外还有根据cookie定义等等。无论是pv还是uv,都需要一个时间段来加以描述,平时我们所说的pv,uv数量指的都是24小时之内(一个自然日)的数据。
pv相比较uv来说,技术上比较容易一些,今天咱们就来说一说uv的统计,为什么说uv的统计相对来说比较难呢,因为uv涉及到同一个标准下的自然人的去重,尤其是一个uv千万级别的网站,设计一个好的uv统计系统也许并非想象的那么容易。
那我们就来设计一个以一个自然日为时间段的uv统计系统,一个自然人(uv)的定义为同一个来源IP(当然你也可以自定义其他标准),数据量级别假设为每日千万uv的量级。
注意:今天我们讨论的重点是获取到自然人定义的信息之后如何设计uv统计系统,并非是如何获取自然人的定义。uv系统的设计并非想象的那么简单,因为uv可能随着网站的营销策略会出现瞬间大流量,比如网站举办了一个秒杀活动。
基于DB方案
服务端编程有一句名言曰:没有一个表解决不了的功能,如果有那就两个表三个表。一个uv统计系统确实可以基于数据库来实现,而且也不复杂,uv统计的记录表可以类似如下(不要太纠结以下表设计是否合理):
| 字段 | 类型 | 描述 |
|---|---|---|
| IP | varchar(30) | 客户端来源ip |
| DayID | int | 时间的简写,例如 20190629 |
| 其他字段 | int | 其他字段描述 |
当一个请求到达服务器,服务端每次需要查询一次数据库是否有当前IP和当前时间的访问记录,如果有,则说明是同一个uv,如果没有,则说明是新的uv记录,插入数据库。当然以上两步也可以写到一个sql语句中:
if exists( select 1 from table where ip='ip' and dayid=dayid )
Begin
return 0
End
else
Begin
insert into table .......
End所有基于数据库的解决方案,在数据量大的情况下几乎都更容易出现瓶颈。面对每天千万级别的uv统计,基于数据库的这种方案也许并不是最优的。
优化方案
面对每一个系统的设计,我们都应该沉下心来思考具体的业务。至于uv统计这个业务有几个特点:
-
每次请求都需要判断是否已经存在相同的uv记录
-
持久化uv数据不能影响正常的业务
- uv数据的准确性可以忍受一定程度的误差
哈希表
基于数据库的方案中,在大数据量的情况下,性能的瓶颈引发原因之一就是:判断是否已经存在相同记录,所以要优化这个系统,肯定首先是要优化这个步骤。根据菜菜以前的文章,是否可以想到解决这个问题的数据结构,对,就是哈希表。哈希表根据key来查找value的时间复杂度为O(1)常数级别,可以完美的解决查找相同记录的操作瓶颈。
也许在uv数据量比较小的时候,哈希表也许是个不错的选择,但是面对千万级别的uv数据量,哈希表的哈希冲突和扩容,以及哈希表占用的内存也许并不是好的选择了。假设哈希表的每个key和value 占用10字节,1千万的uv数据大约占用 100M,对于现代计算机来说,100M其实不算大,但是有没有更好的方案呢?
优化哈希表
基于哈希表的方案,在千万级别数据量的情况下,只能算是勉强应付,如果是10亿的数据量呢?那有没有更好的办法搞定10亿级数据量的uv统计呢?这里抛开持久化数据,因为持久化设计到数据库的分表分库等优化策略了,咱们以后再谈。有没有更好的办法去快速判断在10亿级别的uv中某条记录是否存在呢?
为了尽量缩小使用的内存,我们可以这样设计,可以预先分配bit类型的数组,数组的大小是统计的最大数据量的一个倍数,这个倍数可以自定义调整。现在假设系统的uv最大数据量为1千万,系统可以预先分配一个长度为5千万的bit数组,bit占用的内存最小,只占用一位。按照一个哈希冲突比较小的哈希函数计算每一个数据的哈希值,并设置bit数组相应哈希值位置的值为1。由于哈希函数都有冲突,有可能不同的数据会出现相同的哈希值,出现误判,但是我们可以用多个不同的哈希函数来计算同一个数据,来产生不同的哈希值,同时把这多个哈希值的数组位置都设置为1,从而大大减少了误判率,刚才新建的数组为最大数据量的一个倍数也是为了减小冲突的一种方式(容量越大,冲突越小)。当一个1千万的uv数据量级,5千万的bit数组占用内存才几十M而已,比哈希表要小很多,在10亿级别下内存占用差距将会更大。
以下为代码示例:
class BloomFilter
{
BitArray container = null;
public BloomFilter(int length)
{
container = new BitArray(length);
}
public void Set(string key)
{
var h1 = Hash1(key);
var h2 = Hash2(key);
var h3 = Hash3(key);
var h4 = Hash4(key);
container[h1] = true;
container[h2] = true;
container[h3] = true;
container[h4] = true;
}
public bool Get(string key)
{
var h1 = Hash1(key);
var h2 = Hash2(key);
var h3 = Hash3(key);
var h4 = Hash4(key);
return container[h1] && container[h2] && container[h3] && container[h4];
}
//模拟哈希函数1
int Hash1(string key)
{
int hash = 5381;
int i;
int count;
char[] bitarray = key.ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash += (hash << 5) + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
int Hash2(string key)
{
int seed = 131; // 31 131 1313 13131 131313 etc..
int hash = 0;
int count;
char[] bitarray = (key+"key2").ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash = hash * seed + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF)% container.Length;
}
int Hash3(string key)
{
int hash = 0;
int i;
int count;
char[] bitarray = (key + "keykey3").ToCharArray();
count = bitarray.Length;
for (i = 0; i < count; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (bitarray[i]) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (bitarray[i]) ^ (hash >> 5)));
}
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
int Hash4(string key)
{
int hash = 5381;
int i;
int count;
char[] bitarray = (key + "keykeyke4").ToCharArray();
count = bitarray.Length;
while (count > 0)
{
hash += (hash << 5) + (bitarray[bitarray.Length - count]);
count--;
}
return (hash & 0x7FFFFFFF) % container.Length;
}
}测试程序为:
BloomFilter bf = new BloomFilter(200000000);
int exsitNumber = 0;
int noExsitNumber = 0;
for (int i=0;i < 10000000; i++)
{
string key = $"ip_{i}";
var isExsit= bf.Get(key);
if (isExsit)
{
exsitNumber += 1;
}
else
{
bf.Set(key);
noExsitNumber += 1;
}
}
Console.WriteLine($"判断存在的数据量:{exsitNumber}");
Console.WriteLine($"判断不存在的数据量:{noExsitNumber}");测试结果:
判断存在的数据量:7017
判断不存在的数据量:×××983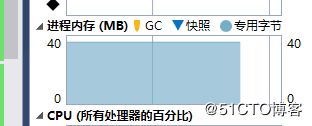
占用内存40M,误判率不到 千分之1,在这个业务场景下在可接受范围之内。在真正的业务当中,系统并不会在启动之初就分配这么大的bit数组,而是随着冲突增多慢慢扩容到一定容量的。
异步优化
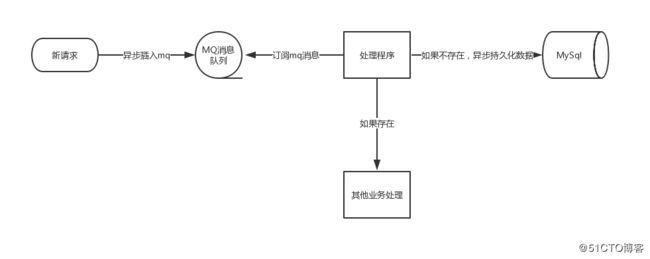
当判断一个数据是否已经存在这个过程解决之后,下一个步骤就是把数据持久化到DB,如果数据量较大或者瞬间数据量较大,可以考虑使用mq或者读写IO比较大的NOSql来代替直接插入关系型数据库。
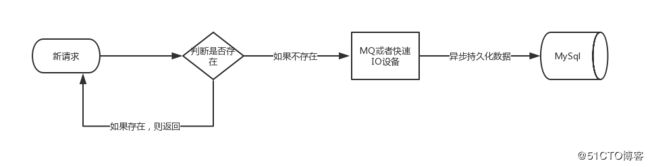
思路一转,整个的uv流程其实也都可以异步化,而且也推荐这么做。