Node.js Stream(流)
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。
Node.js,Stream 有四种流类型:
Readable - 可读操作。
Writable - 可写操作。
Duplex - 可读可写操作.
Transform - 操作被写入数据,然后读出结果。
所有的 Stream 对象都是 EventEmitter 的实例。常用的事件有:
data - 当有数据可读时触发。
end - 没有更多的数据可读时触发。
error - 在接收和写入过程中发生错误时触发。
finish - 所有数据已被写入到底层系统时触发。
从流中读取数据
创建 input.txt 文件,内容如下:
hello world!
创建 main.js 文件, 代码如下:
var fs = require("fs");
var data = '';
// 创建可读流
var readerStream = fs.createReadStream('input.txt');
// 设置编码为 utf8。
readerStream.setEncoding('UTF8');
// 处理流事件 --> data, end, and error
readerStream.on('data', function(chunk) {
data += chunk;
});
readerStream.on('end',function(){
console.log(data);
});
readerStream.on('error', function(err){
console.log(err.stack);
});
console.log("程序执行完毕");

写入流
创建 main.js 文件, 代码如下:
var fs = require('fs');
var data = "hello world!!!"
// 创建一个可以写入的流,写入到文件 output.txt 中
var writerStream = fs.createWriteStream('output.txt');
// 使用 utf8 编码写入数据
writerStream.write(data,'UTF8');
// 标记文件末尾
writerStream.end();
// 处理流事件 --> finish, end, and error
writerStream.on('finish',function{
console.log('写入完成!');
});
writerStream.on('error',function(err){
console.log(err.stack);
});
console.log('程序执行完毕');
以上程序会将 data 变量的数据写入到 output.txt 文件中。代码执行结果如下:

查看 output.txt 文件的内容:

管道流
管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。

如上面的图片所示,我们把文件比作装水的桶,而水就是文件里的内容,我们用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就慢慢的实现了大文件的复制过程。
以下实例我们通过读取一个文件内容并将内容写入到另外一个文件中。
设置 input.txt 文件内容如下:
hello world
管道流操作实例
创建 main.js 文件, 代码如下:
var fs = require('fs');
//创建一个输入流
var readerStream = fs.createReadStream('input.txt');
//创建一个输出流
var writerStream = fs.createWriteStream('output.txt');
// 管道读写操作
// 读取 input.txt 文件内容,并将内容写入到 output.txt 文件中
readerStream.pipe(writerStream);
console.log('程序执行完毕');
代码执行结果如下:

查看 output.txt 文件的内容:

链式流
链式是通过连接输出流到另外一个流并创建多个对个流操作链的机制。链式流一般用于管道操作。
接下来我们就是用管道和链式来压缩和解压文件。
创建 compress.js 文件, 代码如下:
var fs = require("fs");
var zlib = require('zlib');
// 压缩 input.txt 文件为 input.txt.gz
fs.createReadStream('input.txt')
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream('input.txt.gz'));
console.log("文件压缩完成。");
代码执行结果如下:

执行完以上操作后,我们可以看到当前目录下生成了 input.txt 的压缩文件 input.txt.gz。
接下来,让我们来解压该文件,创建 decompress.js 文件,代码如下:
var fs = require('fs');
var zip = require('zlib');
fs.createReadStream('input.txt.gz').pipe(zip.createGunzip()).pipe(fs.createWriteStream('input.txt'));
console.log('文件解压完成');
代码执行结果如下:

Node.js模块系统
为了让Node.js的文件可以相互调用,Node.js提供了一个简单的模块系统。
模块是Node.js 应用程序的基本组成部分,文件和模块是一一对应的。换言之,一个 Node.js 文件就是一个模块,这个文件可能是JavaScript 代码、JSON 或者编译过的C/C++ 扩展。
创建模块
在 Node.js 中,创建一个模块非常简单,如下我们创建一个 'main.js' 文件,代码如下:
var hello = require('./hello');
hello.world();
以上实例中,代码 require('./hello') 引入了当前目录下的hello.js文件(./ 为当前目录,node.js默认后缀为js)。
Node.js 提供了exports 和 require 两个对象,其中 exports 是模块公开的接口,require 用于从外部获取一个模块的接口,即所获取模块的 exports 对象。
接下来我们就来创建hello.js文件,代码如下:
exports.world = function() {
console.log('Hello World');
}
在以上示例中,hello.js 通过 exports 对象把 world 作为模块的访问接口,在 main.js 中通过 require('./hello') 加载这个模块,然后就可以直接访 问 hello.js 中 exports 对象的成员函数了。
有时候我们只是想把一个对象封装到模块中,格式如下:
module.exports = function() {
// ...
}
例如:
//hello.js
var Hello = function() {
var name;
this.setName = function(thyName) {
name = thyName;
};
this.sayHello = function() {
console.log('Hello ' + name);
};
};
module.exports = Hello;
这样就可以直接获得这个对象了:
//main.js
var Hello = require('./hello');
hello = new Hello();
hello.setName('HB');
hello.sayHello();
模块接口的唯一变化是使用 module.exports = Hello 代替了exports.world = function(){}。 在外部引用该模块时,其接口对象就是要输出的 Hello 对象本身,而不是原先的 exports。
服务端的模块放在哪里
也许你已经注意到,我们已经在代码中使用了模块了。像这样:
var http = require("http");
...
http.createServer(...);
Node.js中自带了一个叫做"http"的模块,我们在我们的代码中请求它并把返回值赋给一个本地变量。
这把我们的本地变量变成了一个拥有所有 http 模块所提供的公共方法的对象。
Node.js 的 require方法中的文件查找策略如下:
由于Node.js中存在4类模块(原生模块和3种文件模块),尽管require方法极其简单,但是内部的加载却是十分复杂的,其加载优先级也各自不同。如下图所示:
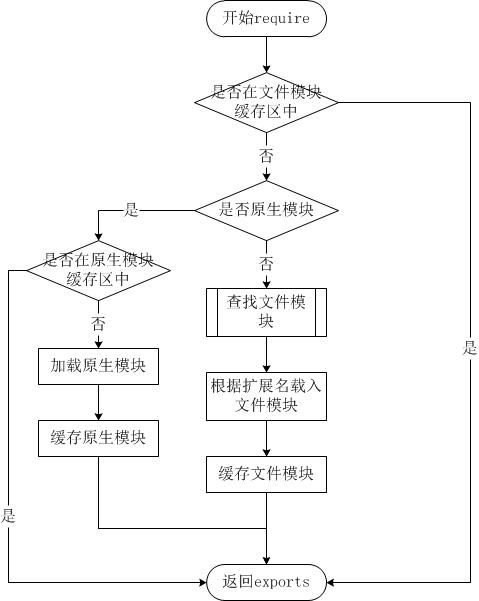
从文件模块缓存中加载
尽管原生模块与文件模块的优先级不同,但是都不会优先于从文件模块的缓存中加载已经存在的模块。
从原生模块加载
原生模块的优先级仅次于文件模块缓存的优先级。require方法在解析文件名之后,优先检查模块是否在原生模块列表中。以http模块为例,尽管在目录下存在一个http/http.js/http.node/http.json文件,require("http")都不会从这些文件中加载,而是从原生模块中加载。
原生模块也有一个缓存区,同样也是优先从缓存区加载。如果缓存区没有被加载过,则调用原生模块的加载方式进行加载和执行。
从文件加载
当文件模块缓存中不存在,而且不是原生模块的时候,Node.js会解析require方法传入的参数,并从文件系统中加载实际的文件,加载过程中的包装和编译细节在前一节中已经介绍过,这里我们将详细描述查找文件模块的过程,其中,也有一些细节值得知晓。
require方法接受以下几种参数的传递:
在路径 Y 下执行 require(X) 语句执行顺序:
1. 如果 X 是内置模块
a. 返回内置模块
b. 停止执行
2. 如果 X 以 '/' 开头
a. 设置 Y 为文件根路径
3. 如果 X 以 './' 或 '/' or '../' 开头
a. LOAD_AS_FILE(Y + X)
b. LOAD_AS_DIRECTORY(Y + X)
4. LOAD_NODE_MODULES(X, dirname(Y))
5. 抛出异常 "not found"
LOAD_AS_FILE(X)
1. 如果 X 是一个文件, 将 X 作为 JavaScript 文本载入并停止执行。
2. 如果 X.js 是一个文件, 将 X.js 作为 JavaScript 文本载入并停止执行。
3. 如果 X.json 是一个文件, 解析 X.json 为 JavaScript 对象并停止执行。
4. 如果 X.node 是一个文件, 将 X.node 作为二进制插件载入并停止执行。
LOAD_INDEX(X)
1. 如果 X/index.js 是一个文件, 将 X/index.js 作为 JavaScript 文本载入并停止执行。
2. 如果 X/index.json 是一个文件, 解析 X/index.json 为 JavaScript 对象并停止执行。
3. 如果 X/index.node 是一个文件, 将 X/index.node 作为二进制插件载入并停止执行。
LOAD_AS_DIRECTORY(X)
1. 如果 X/package.json 是一个文件,
a. 解析 X/package.json, 并查找 "main" 字段。
b. let M = X + (json main 字段)
c. LOAD_AS_FILE(M)
d. LOAD_INDEX(M)
2. LOAD_INDEX(X)
LOAD_NODE_MODULES(X, START)
1. let DIRS=NODE_MODULES_PATHS(START)
2. for each DIR in DIRS:
a. LOAD_AS_FILE(DIR/X)
b. LOAD_AS_DIRECTORY(DIR/X)
NODE_MODULES_PATHS(START)
1. let PARTS = path split(START)
2. let I = count of PARTS - 1
3. let DIRS = []
4. while I >= 0,
a. if PARTS[I] = "node_modules" CONTINUE
b. DIR = path join(PARTS[0 .. I] + "node_modules")
c. DIRS = DIRS + DIR
d. let I = I - 1
5. return DIRS
Node.js 函数
在JavaScript中,一个函数可以作为另一个函数的参数。我们可以先定义一个函数,然后传递,也可以在传递参数的地方直接定义函数。
Node.js中函数的使用与Javascript类似,举例来说,你可以这样做:
function say(word) {
console.log(word);
}
function execute(someFunction, value) {
someFunction(value);
}
execute(say, "Hello");
以上代码中,我们把 say 函数作为execute函数的第一个变量进行了传递。这里返回的不是 say 的返回值,而是 say 本身!
这样一来, say 就变成了execute 中的本地变量 someFunction ,execute可以通过调用 someFunction() (带括号的形式)来使用 say 函数。
当然,因为 say 有一个变量, execute 在调用 someFunction 时可以传递这样一个变量。
匿名函数
我们可以把一个函数作为变量传递。但是我们不一定要绕这个"先定义,再传递"的圈子,我们可以直接在另一个函数的括号中定义和传递这个函数:
function execute(someFunction,value){
someFunction(value);
}
execute(function(world){console.log(world)},'hello');
我们在 execute 接受第一个参数的地方直接定义了我们准备传递给 execute 的函数。
用这种方式,我们甚至不用给这个函数起名字,这也是为什么它被叫做匿名函数 。
函数传递是如何让HTTP服务器工作的
带着这些知识,我们再来看看我们简约而不简单的HTTP服务器:
var http = require("http");
http.createServer(function(request, response) {
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}).listen(8888);
现在它看上去应该清晰了很多:我们向 createServer 函数传递了一个匿名函数。
用这样的代码也可以达到同样的目的:
var http = require("http");
function onRequest(request, response) {
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
Node.js 路由
我们要为路由提供请求的URL和其他需要的GET及POST参数,随后路由需要根据这些数据来执行相应的代码。
因此,我们需要查看HTTP请求,从中提取出请求的URL以及GET/POST参数。这一功能应当属于路由还是服务器(甚至作为一个模块自身的功能)确实值得探讨,但这里暂定其为我们的HTTP服务器的功能。
我们需要的所有数据都会包含在request对象中,该对象作为onRequest()回调函数的第一个参数传递。但是为了解析这些数据,我们需要额外的Node.JS模块,它们分别是url和querystring模块。
url.parse(string).query
|
url.parse(string).pathname |
| |
| |
------ -------------------
http://localhost:8888/start?foo=bar&hello=world
--- -----
| |
| |
querystring.parse(queryString)["foo"] |
|
querystring.parse(queryString)["hello"]
当然我们也可以用querystring模块来解析POST请求体中的参数.
现在我们来给onRequest()函数加上一些逻辑,用来找出浏览器请求的URL路径:
var http = require("http");
var url = require("url");
var start = function() {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
好了,我们的应用现在可以通过请求的URL路径来区别不同请求了--这使我们得以使用路由(还未完成)来将请求以URL路径为基准映射到处理程序上。
在我们所要构建的应用中,这意味着来自/start和/upload的请求可以使用不同的代码来处理。稍后我们将看到这些内容是如何整合到一起的。
现在我们可以来编写路由了,建立一个名为 router.js 的文件,添加以下内容:
function route(pathname) {
console.log("About to route a request for " + pathname);
}
exports.route = route;
如你所见,这段代码什么也没干,不过对于现在来说这是应该的。在添加更多的逻辑以前,我们先来看看如何把路由和服务器整合起来。
我们的服务器应当知道路由的存在并加以有效利用。我们当然可以通过硬编码的方式将这一依赖项绑定到服务器上,但是其它语言的编程经验告诉我们这会是一件非常痛苦的事,因此我们将使用依赖注入的方式较松散地添加路由模块。
首先,我们来扩展一下服务器的start()函数,以便将路由函数作为参数传递过去,server.js 文件代码如下
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
console.log("Request for " + pathname + " received.");
route(pathname);
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello World");
response.end();
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
同时,我们会相应扩展index.js,使得路由函数可以被注入到服务器中:
var server = require('./main');
var router = require('./route');
server.start(router.route);
现在启动应用(node index.js,始终记得这个命令行),随后请求一个URL,你将会看到应用输出相应的信息,这表明我们的HTTP服务器已经在使用路由模块了,并会将请求的路径传递给路由:

浏览器访问 http://127.0.0.1:8888/,输出结果如下:
