1. Spark Streaming
- Spark Streaming是一个基于Spark Core之上的实时计算框架,可以从很多数据源消费数据并对数据进行处理
- Spark Streaing中有一个最基本的抽象叫DStream(代理),本质上就是一系列连续的RDD,DStream其实就是对RDD的封装
- DStream可以认为是一个RDD的工厂,该DStream里面生产都是相同业务逻辑的RDD,只不过是RDD里面要读取数据的不相同
- 在一个批次的处理时间间隔里, DStream只产生一个RDD
- DStream就相当于一个"模板", 我们可以根据这个"模板"来处理一段时间间隔之内产生的这个rdd,以此为依据来构建rdd的DAG
2. 当下比较流行的实时计算引擎
吞吐量 编程语言 处理速度 生态
Storm 较低 clojure 非常快(亚秒) 阿里(JStorm)
Flink 较高 scala 较快(亚秒) 国内使用较少
Spark Streaming 非常高 scala 快(毫秒) 完善的生态圈
3. Spark Streaming处理网络数据
//创建StreamingContext 至少要有两个线程 一个线程用于接收数据 一个线程用于处理数据
val conf = new SparkConf().setAppName("Ops1").setMaster("local[2]")
val ssc = new StreamingContext(conf, Milliseconds(3000))
val receiverDS: ReceiverInputDStream[String] = ssc.socketTextStream("uplooking01", 44444)
val pairRetDS: DStream[(String, Int)] = receiverDS.flatMap(_.split(",")).map((_, 1)).reduceByKey(_ + _)
pairRetDS.print()
//开启流计算
ssc.start()
//优雅的关闭
ssc.awaitTermination()
4. Spark Streaming接收数据的两种方式(Kafka)
Receiver
- 偏移量是由zookeeper来维护的
- 使用的是Kafka高级的API(消费者的API)
- 编程简单
- 效率低(为了保证数据的安全性,会开启WAL)
- kafka0.10的版本中已经彻底弃用Receiver了
- 生产环境一般不会使用这种方式
Direct
- 偏移量是有我们来手动维护
- 效率高(我们直接把spark streaming接入到kafka的分区中了)
- 编程比较复杂
- 生产环境一般使用这种方式
5. Spark Streaming整合Kafka
基于Receiver的方式整合kafka(生产环境不建议使用,在0.10中已经移除了)
//创建StreamingContext 至少要有两个线程 一个线程用于接收数据 一个线程用于处理数据
val conf = new SparkConf().setAppName("Ops1").setMaster("local[2]")
val ssc = new StreamingContext(conf, Milliseconds(3000))
val zkQuorum = "uplooking03:2181,uplooking04:2181,uplooking05:2181"
val groupId = "myid"
val topics = Map("hadoop" -> 3)
val receiverDS: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
receiverDS.flatMap(_._2.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
基于Direct的方式(生产环境使用)
//创建StreamingContext 至少要有两个线程 一个线程用于接收数据 一个线程用于处理数据
val conf = new SparkConf().setAppName("Ops1").setMaster("local[2]")
val ssc = new StreamingContext(conf, Milliseconds(3000))
val kafkaParams = Map("metadata.broker.list" -> "uplooking03:9092,uplooking04:9092,uplooking05:9092")
val topics = Set("hadoop")
val inputDS: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
inputDS.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
6. 实时流计算的架构
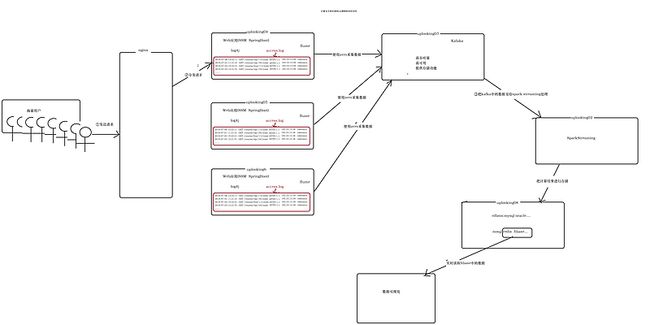
1. 生成日志(模拟用户访问web应用的日志)
public class GenerateAccessLog {
public static void main(String[] args) throws IOException, InterruptedException {
//准备数据
int[] ips = {123, 18, 123, 112, 181, 16, 172, 183, 190, 191, 196, 120};
String[] requesTypes = {"GET", "POST"};
String[] cursors = {"/vip/112", "/vip/113", "/vip/114", "/vip/115", "/vip/116", "/vip/117", "/vip/118", "/vip/119", "/vip/120", "/vip/121", "/free/210", "/free/211", "/free/212", "/free/213", "/free/214", "/company/312", "/company/313", "/company/314", "/company/315"};
String[] courseNames = {"大数据", "python", "java", "c++", "c", "scala", "android", "spark", "hadoop", "redis"};
String[] references = {"www.baidu.com/", "www.sougou.com/", "www.sou.com/", "www.google.com"};
FileWriter fw = new FileWriter(args[0]);
PrintWriter printWriter = new PrintWriter(fw);
while (true) {
// Thread.sleep(1000);
//产生字段
String date = new Date().toLocaleString();
String method = requesTypes[getRandomNum(0, requesTypes.length)];
String url = "/cursor" + cursors[getRandomNum(0, cursors.length)];
String HTTPVERSION = "HTTP/1.1";
String ip = ips[getRandomNum(0, ips.length)] + "." + ips[getRandomNum(0, ips.length)] + "." + ips[getRandomNum(0, ips.length)] + "." + ips[getRandomNum(0, ips.length)];
String reference = references[getRandomNum(0, references.length)];
String rowLog = date + " " + method + " " + url + " " + HTTPVERSION + " " + ip + " " + reference;
printWriter.println(rowLog);
printWriter.flush();
}
}
//[start,end)
public static int getRandomNum(int start, int end) {
int i = new Random().nextInt(end - start) + start;
return i;
}
}
2. flume使用avro采集web应用服务器的日志数据
采集命令执行的结果到avro中
# The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called 'agent' f1.sources = r1 f1.channels = c1 f1.sinks = k1 #define sources f1.sources.r1.type = exec f1.sources.r1.command =tail -F /logs/access.log #define channels f1.channels.c1.type = memory f1.channels.c1.capacity = 1000 f1.channels.c1.transactionCapacity = 100 #define sink 采集日志到uplooking03 f1.sinks.k1.type = avro f1.sinks.k1.hostname = uplooking03 f1.sinks.k1.port = 44444 #bind sources and sink to channel f1.sources.r1.channels = c1 f1.sinks.k1.channel = c1 从avro采集到控制台 # The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called 'agent' f2.sources = r2 f2.channels = c2 f2.sinks = k2 #define sources f2.sources.r2.type = avro f2.sources.r2.bind = uplooking03 f2.sources.r2.port = 44444 #define channels f2.channels.c2.type = memory f2.channels.c2.capacity = 1000 f2.channels.c2.transactionCapacity = 100 #define sink f2.sinks.k2.type = logger #bind sources and sink to channel f2.sources.r2.channels = c2 f2.sinks.k2.channel = c2 从avro采集到kafka中 # The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called 'agent' f2.sources = r2 f2.channels = c2 f2.sinks = k2 #define sources f2.sources.r2.type = avro f2.sources.r2.bind = uplooking03 f2.sources.r2.port = 44444 #define channels f2.channels.c2.type = memory f2.channels.c2.capacity = 1000 f2.channels.c2.transactionCapacity = 100 #define sink f2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink f2.sinks.k2.topic = hadoop f2.sinks.k2.brokerList = uplooking03:9092,uplooking04:9092,uplooking05:9092 f2.sinks.k2.requiredAcks = 1
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。