Solr是Apache旗下基于NoSQL技术的全文本搜索引擎。
简单来说,Solr具有如下特点:
- 强大的全文本搜索能力
- 针对大容量流量进行优化
- 提供基于XML/JSON/HTTP的标准开放接口
- 提供高效的管理页面
- 提供易于使用的监控工具
- 高度易于扩展和容错
- 使用简单的配置文件,灵活且适应性强
- 近实时索引
- 提供可扩展的插件
安装
Cli命令?不存在的….emmm
curl或wget吧
curl https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/7.4.0/solr-7.4.0.zip
这里使用的链接是清华的镜像,具体请参见Apache Download Mirrors
将Solr下载后解压,得到如下的文件夹:

/bin:存放solr相关的运行脚本和配置文件
关于solr的quick start,大家参见Solr quick start
使用solr建立自己的搜索服务
启动solr
首先,切换到solr下的bin目录:
cd solr-7.4.0/bin
使用如下命令运行solr
./solr start

看到这个输出,说明solr就启动成功了,可以打开 http://localhost:8983/solr 查看solr的运行情况。
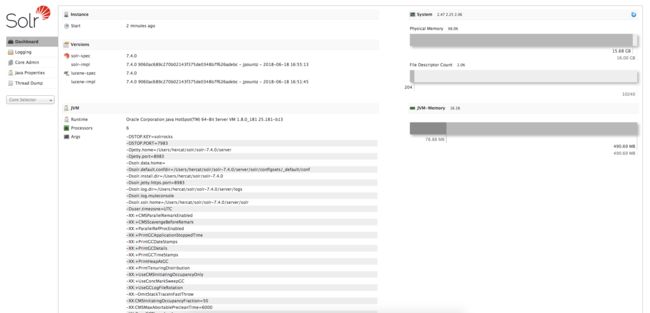
此外,solr还支持如下命令
- ./solr restart 重启solr
- ./solr stop 停止solr
- ./solr -h 查看帮助
创建自己的核心(core)
核心(core)其实就是一个搜索的仓库,可以往这个搜索仓库添加索引文档,再进行相关的搜索和查询。
使用如下命令创建一个新的核心:
./solr create -c
注意:该命令创建核心时,使用了solr的默认配置文件,solr官方不推荐我们在应用到实际产品时使用它的默认配置文件。但是我们可以在默认文件的基础上进行修改。当我们需要部署多个solr实例的时候,这份配置文件就可以复用了。其次,如果你的solr运行在cloud模式下,可以添加 -s 2 -rf 2,对于这两个参数起到的作用,这里简单说明一下,solr为你创建的核心添加了两个节点(node),每个节点都添加了两个区块(shard),这两个参数在SolrCloud中才会起作用。

执行创建核心的命令后,可以在solr管理面板中查看新核心的基本信息:
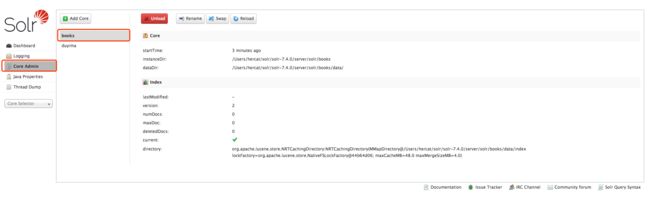
Solr配置文件
在上一步说到,我们创建的核心使用了solr的默认配置文件,那默认配置文件在哪里呢?这些默认配置文件有什么用呢?
Solr的默认配置文件在solr-7.4.0/server/solr/configsets/_default/conf目录下:

简单说明一下这些文件的作用:
synonyms.txt 同义词替换配置
这个文件的作用就是配置一些常用的同义词替换。比如说你的文档里面有一个关键词土豆,但是显然用户如果搜索马铃薯、洋芋,solr也应该返回包含土豆的文档。synonyms.txt文件就是配置这样的一些同义词映射关系的。
stopwords.txt停用词配置
对于停用词配置,我暂时找不到一个中文搜索的例子来解释这个东西。但是在英文里面,有很多冠词之类的,如”a”,”an”,”the”等,这些冠词是不需要作为关键词进行索引的,用户提交的搜索里面包含这些无意义的词汇时,也应当剔除。因此stopwords.txt就是用来配置这些没有意义的词汇表的。但是在中文里面,这些无意义的词汇可能比较少。我能想到的可能是量词之类的,比如个、颗等;当用户搜索”一颗苹果”时,颗不应该作为关键词进行查询。
solrconfig.xmlsolr核心配置文件
该文件配置了solr核心运行的基本参数。该文件一般不需要进行修改,里面的默认配置已经能够满足大部分应用的需求。
managed-schemacore模式配置
这个文件没有后缀,但其实他是一个xml文档,solr不希望我们手工编辑这个文件,所以没有写明它的后缀名吧。这个文件是核心如何对文档进行索引、分析、查询处理的配置文件,solr确实也提供了相应的API对这个文件进行修改。在老版本中,古老的程序员都是手工修改这个文件的。
当你使用solr create命令创建自己的核心时,solr就会把该文件夹提交到新核心的配置文件目录下。默认情况下,新核心在 solr-7.4.0/server/solr/ 目录下
managed-schema详细介绍
首先,选用一款你最爱的文本编辑器打开solr-7.4.0/server/solr/

如图,solr默认为我们配置的四个字段。其中id作为solr索引和存储的主键;_version记录了每个字段的版本信息;如果solr没有匹配到你文档的字段信息的话,就会默认把你的文档全部索引成为text字段。
对了,这里随便说一句。对于需要添加到solr进行索引的结构化文档,必须包含id字段;但是对于类似于word、pdf这种文件可以不用指明id。
紧接着,solr还定义了一大推默认的动态字段:
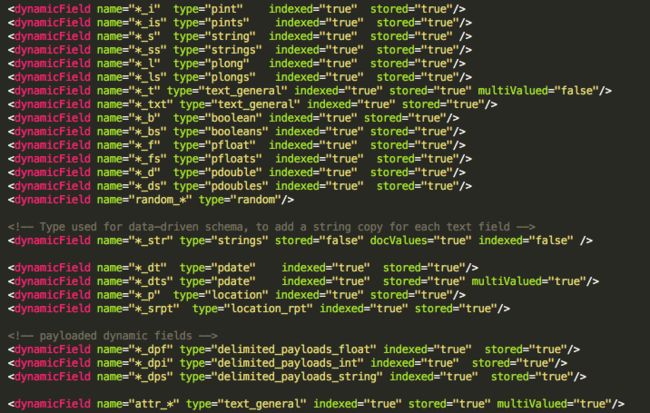
动态字段的作用就是模糊匹配字段进行索引。举个例子,比如你的文档里面有类似于”age_i”,”level_i”等,就会被动态字段”*_i”匹配到,并识别为int数据类型。
这个文件余下的部分就是定义了一堆默认的字段类型,比如:
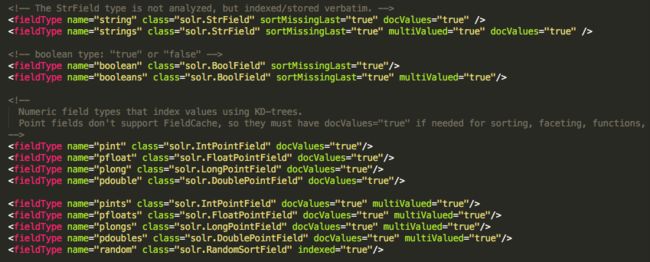
这种低级的基础数据类型,这些基础的类型都不带有数据分析的功能。
当然还有待数据分析、过滤功能的类型:

Solr定义的类型默认是不支持中文解析的,但是我们完全可以自己去定义这些类型。比如定义对中文进行分词、过滤的字段类型。
根据需要索引的文档配置manage-schema
这里的配置主要是对manage-schema进行配置。由于每个公司管理的数据在结构上差异巨大,数据类型也不尽相同。因此,对于管理的数据进行针对性的配置,对实现更好的搜索效果至关重要。
对于需要搜索的数据,我们需要对其配置字段信息、字段的类型信息等。虽然solr提供了schemaless的功能,该功能可以根据你提交的文档自动生成字段并推测字段类型。但是这个功能坑比较多,实际使用的时候经常会触发solr内部的一大推数据类型转换异常。由于solr是基于Java这类强类型语言开发的,因此这里我们还是手动对需要搜索的数据进行配置比较好。
比如,需要添加的文档结构如下:

这里给的例子时JSON文件,当然你也可以使用XML、CSV一类的结构化文件格式。
对应的,我们在managed-schema添加对如上结构的识别信息:
这里说明一下indexed和stored属性的作用:
Indexed表示对该字段需要进行索引,索引的目的是为了后面可以对该字段进行查询;
Stored表示是否存储该字段,只有存储的了字段才会显示在搜索结果中。
如何设置这个两个属性呢?我觉得可以使用如下的简单原则:
- 判断某个字段会不会为用户提供搜索的功能,如果用户能够根据该字段进行搜索,那么indexed设置为true
- 对于indexed为true的字段,stored也应该为true
-
对于不需要索引的字段,如果需要暂时给用户看,那么stored设置为true
将你的配置文件添加到solr默认的field区下面就可以了。
现在,已经完成了对solr核心的基本配置,我们可以在solr core admin中重新加载核心,让新的配置文件生效。
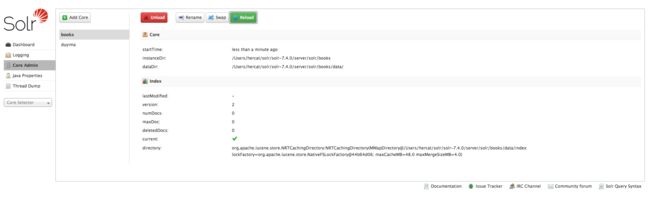 重新加载核心
重新加载核心
点了reload之后反馈的是绿色,那么说明你手工修改manage-schema已经被solr原谅了,恭喜你。
将数据添加到solr进行索引
在完成managed-schema配置后,我们就可以把数据添加到solr了。
在命令行中使用
./post -c
如下:
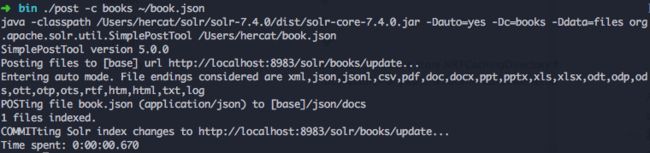
如果你的terminal疯狂输出一大堆信息的话,说明emmmm你的配置可能有点问题,参照前面的步骤仔细检查一遍哟~
到这里我们已经将数据成功的提交给solr进行索引了,那我们是不是就可以利用solr进行搜索了呢?
是的,没错。打开这个神奇的链接 http://localhost:8983/solr/#/
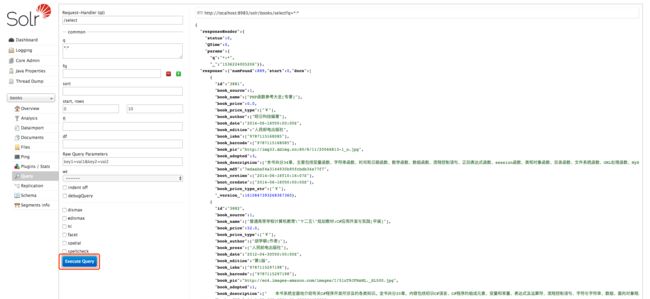
直接click Execute Query按钮!如果出现一遍原谅色的海洋,恭喜你。进入solr概览的总结,否则的话请从头仔细看一下本文章,直到出现一片原谅色的海洋,否则solr将对你永不饶恕,你已经惹怒它了。
总结
- 本文对solr进行了一个简单的介绍,并说明了solr一些基础的启动命令,并介绍了solr核心的创建方式。但是注意,文中对核心用了两个不同的词汇进行表述,分别是”core”和”collection”,不严谨的说他们都是表示核心。
- 对于核心的配置文件,本文做了一个简要的概述,介绍了一些重要配置文件的基本作用。
- 本文重点介绍了managed-schema文件的结构和配置方式。
- 本文使用solr实现了对文档的搜索。
总结一下solr的基本使用:
- 使用./solr start命令启动solr
- 使用./solr create命令创建一个核心
- 根据待索引文档的结构,配置核心的managed-schema文件
- 将准备好的数据利用./post命令添加到solr进行索引。
最后说明
本文介绍的命令均是在mac os系统上,linux系统的命令格式和本文差异不大。但windows系统存在部分差异,可以参见前文提交的sorl-quick-start链接查看详细内容。
请期待下一期关于solr在filedType中添加中文分词、从数据库导入数据倒solr已经solr高级搜索的相关内容。
please give me your ❤️ and !!!