[TOC]
Scala简介
Scala是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。
Scala运行在Java虚拟机上,并兼容现有的Java程序。
Scala源代码被编译成Java字节码,所以它可以运行于JVM之上,并可以调用现有的Java类库。
函数编程范式更适合用于Map/Reduce和大数据模型,它摒弃了数据与状态的计算模型,着眼于函数本身,而非执行的过程的数据和状态的处理。函数范式逻辑清晰、简单,非常适合用于处理基于不变数据的批量处理工作,这些工作基本都是通过map和reduce操作转换数据后,生成新的数据副本,然后再进行处理。
像Spark,Flink等都是采用Scala开发的,所以学习好大数据,掌握scala是必要的。
官网:http://scala-lang.org/
Scala安装验证
1、安装JDK
2、JAVA_HOME, PATH
3、Maven
4、SCALA SDK
下载地址:http://scala-lang.org/download/all.html
这里选择的版本为Scala 2.10.5,分为windows和linux版本
5、配置SCALA_HOME
在windows环境变量中添加SCALA_HOME
6、验证
scala -version
Scala code runner version 2.10.5 -- Copyright 2002-2013, LAMP/EPFL入门程序
object HelloWorld {
def main(args:Array[String]):Unit = {
println("Hello World!")
}
}保存为HelloWorld.scala,然后再执行下面两步即可:
scalac HelloWorld.scala
scala HelloWorldScala基础知识和语法
语言特点
1.可拓展
面向对象
函数式编程
2.兼容JAVA
类库调用
互操作
3.语法简洁
代码行短
类型推断
抽象控制
4.静态类型化
可检验
安全重构
5.支持并发控制
强计算能力
自定义其他控制结构Scala与Java的关系
-
1、都是基于JVM虚拟机运行的
Scala编译之后的文件也是.class,都要转换为字节码,然后运行在JVM虚拟机之上。
-
2、Scala和Java相互调用
在Scala中可以直接调用Java的代码,同时在Java中也可以直接调用Scala的代码
-
3、Java8 VS Scala
1)Java8(lambda)没有出来之前,Java只是面向对象的一门语言,但是Java8出来以后,Java就是一个面向对象和面向函数的混合语言了。
2)首先我们要对Scala进行精确定位,从某种程度上讲,Scala并不是一个纯粹的面向函数的编程语言,有人认为Scala是一个带有闭包的静态面向对象语言),更准确地说,Scala是面向函数与面向对象的混合。
3)Scala设计的初衷是面向函数FP,而Java起家是面向对象OO,现在两者都是OO和FP的混合语言,是否可以这么认为:Scala= FP + OO,而Java =OO + FP?
由于面向对象OO和面向函数FP两种范式是类似横坐标和纵坐标的两者不同坐标方向的思考方式,类似数据库和对象之间的不匹配阻抗关系,两者如果结合得不好恐怕就不会产生1+1>2的效果。
面向对象是最接近人类思维的方式,而面向函数是最接近计算机的思维方式。如果你想让计算机为人的业务建模服务,那么以OO为主;如果你希望让计算机能自己通过算法从大数据中自动建模,那么以FP为主。所以,Java可能还会在企业工程类软件中占主要市场,而Scala则会在科学计算大数据分析等领域抢占Java市场,比如Scala的Spark大有替代Java的Hadoop之趋势。
Scala解释器和IDEA
1、Scala解释器读到一个表达式,对它进行求值,将它打印出来,接着再继续读下一个表达式。这个过程被称做读取--求值--打印--循环,即:REPL。
从技术上讲,scala程序并不是一个解释器。实际发生的是,你输入的内容被快速地编译成字节码,然后这段字节码交由Java虚拟机执行。正因为如此,大多数scala程序员更倾向于将它称做“REPL”
2、scala
scala>"Hello"
res1: String = Hello
scala> 1+2
res5: Int = 3
scala>"Hello".filter(line=>(line!='l'))
res2: String = Heo你应该注意到了在我们输入解释器的每个语句后,它会输出一行信息,类似res0:
java.lang.String
= Hello。输出的第一部分是REPL给表达式起的变量名。在这几个例子里,REPL为每个表达式定义了一个新变量(res0到res3)。输出的第二部分(:后面的部分)是表达式的静态类型。第一个例子的类型是java.lang.String,最后一个例子的类型则是scala.util.matching.Regex。输出的最后一部分是表达式求值后的结果的字符串化显示。一般是对结果调用toString方法得到的输出,JVM给所有的类都定义了toString方法。

var和val定义变量
1、Scala中没有static的类,但是他有一种类似的伴生对象
2、字段:
字段/变量的定义Scala中使用 var/val 变量/不变量名称 : 类型的方式进行定义,例如:
var index1 : Int = 1
val index2 : Int = 1 其中var与val的区别在于,var是变量,以后的值还可以改变,val的值只能在声明的时候赋值,但是val不是常量,只能说是不变量或只读变量。
3、大家肯定会觉得这种var/val名称 : 类型的声明方式太过于繁琐了,有另外一种方式
所以你在声明字段的时候,可以使用编译器自动推断类型,即不用写: 类型,例如:
var index1 = 1 (类型推断)
val index2 = 1 这个例子演示了被称为类型推断(type inference)的能力,它能让scala自动理解你省略了的类型。这里,你用int字面量初始化index1,因此scala推断index2的类型是Int。对于可以由Scala解释器(或编译器)自动推断类型的情况,就没有必要非得写出类型标注不可。
4、a.方法(b)
这里的方法是一个带有2个参数的方法(一个显示的和一个隐式的)
1.to(10), 1 to 10, 1 until 10
scala> 1.to(10)
res19: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> 1 to 10
res20: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> 1 until 10
res21: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)5、其实根据函数式编程思想中,var变量是个不好的存在,Scala中推荐大家尽可能的采用val的不变量,主要原因是
- 1)、val的不可变有助于理清头绪,但是相对的会付出一部分的性能代价。
- 2)、另外一点就是如果使用var,可能会担心值被错误的更改。
- 3)、使用val而不是var的第二点好处是他能更好地支持等效推论(a=b,b=c —> a=c)
数据类型和操作符
scala拥有和java一样的数据类型,和java的数据类型的内存布局完全一致,精度也完全一致。
下面表格中是scala支持的数据类型:
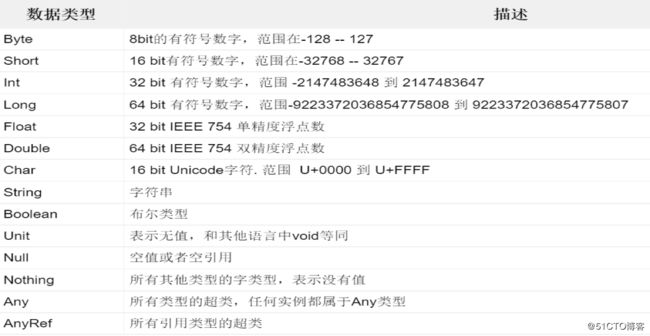
上表中列出的数据类型都是对象,也就是说scala没有java中的原生类型。也就是说scala没有基本数据类型与包装类型的概念。
Scala里,你可以舍弃方法调用的空括号。例外就是如果方法带有副作用就加上括号,如println(),不过如果方法没有副作用就可以去掉括号,如String上调用的toLowerCase:
scala> "Hello".toLowerCase
res22: String = hello
scala> "Hello".toLowerCase()
res23: String = hello数学运算
Scala里,你可以舍弃方法调用的空括号。例外就是如果方法带有副作用就加上括号,如println(),不过如果方法没有副作用就可以去掉括号,如String上调用的toLowerCase:
你可以通过中缀操作符,加号(+),减号(-),乘号(*),除号(/)和余数(%),在任何数类型上调用数学方法, scala中的基础运算与java一致
scala> 1.2 + 2.3
res6: Double = 3.5
scala> 3 - 1
res7: Int = 2
scala> 'b' - 'a'
res8: Int = 1
scala> 2L * 3L
res9: Long = 6
scala> 11 / 4
res10: Int = 2
scala> 11 % 4
res11: Int = 3
scala> 11.0f / 4.0f
res12: Float = 2.75
scala> 11.0 % 4.0
res13: Double = 3.0关系和逻辑操作
你可以用关系方法:大于(>),小于(<),大于等于(>=)和小于等于(<=)比较数类型,像等号操作符那样,产生一个Boolean结果。另外,你可以使用一元操作符!(unary_!方法)改变Boolean值
scala> 1 > 2
res16: Boolean = false
scala> 1 < 2
res17: Boolean = true
scala> 1.0 <= 1.0
res18: Boolean = true
scala> 3.5f >= 3.6f
res19: Boolean = false
scala> 'a' >= 'A'
res20: Boolean = true
scala> val thisIsBoring = !true
thisIsBoring: Boolean = false
scala> !thisIsBoring
res21: Boolean = true对象相等性
scala> ("he" + "llo") == "hello"
res33: Boolean = true
=== 比较2个不同的对象
scala> 1 == 1.0
res34: Boolean = true 其比较的是值,而不是Java概念中的地址值。另外第二个例子,1 == 1.0,会为true,是因为1会做类型的提升变为1.0
Scala控制结构
If表达式有值
1、Scala的if/else语法结构和Java或者C++一样,不过,在Scala中if/else表达式有值,这个值就是跟在if或else之后的表达式的值
val x = 3
if(x > 0) 1 else -1上述表达式的值是1或-1,具体是哪一个取决于x的值,同时你也可以将if/else表达式的值复制给变量
val s = if(x>0) 1 else -1 // 这与如下语句的效果是一样的
if(x >0) s = 1 else s =-1不过,第一种写法更好,因为它可以用来初始化一个val,而在第二种写法当中,s必须是var
2、val result = if(personAge > 18) "Adult" else 0
其中一个分支是java.lang.string,另外一个类型是Int, 所以他们的公共超类是Any
3、如果else丢失了
if(x>0) 1那么有可能if语句没有输出值,但是在Scala中,每个表达式都有值,这个问题的解决方案是引入一个Unit类,写作(),不带else语句的if语句等同于if(x>0) 1else ()
语句终止
1、在Java和C++中,每个语句都已分号结束。但是在Scala中—与JavaScript和其它语言类似—行尾的位置不需要分号。同样,在}、else以及类似的位置也不需要写分号。
不过,如果你想在单行中写下多个语句,就需要将他们以分号隔开
If(n>0){r = r *n ; n-=1}我们需要用分号将r = r *n 和n -=1隔开,由于有},在第二个语句之后并不需要写分号。
2、分行显示
If(n>0){
r = r *n
n-=1
}快表达式和赋值
- 在Java或C++中,快语句是一个包含于}中的语句序列。每当需要在逻辑分支或喜欢执行多个动作时,你都可以使用快语句。
- 在Scala中,{}快包含一些列表达式,其结果也是一个表达式。块中最后一个表达式式的值就是快的值。
scala> val n = 9
n: Int = 9
scala> var f = 0
f: Int = 0
scala> var m = 5
m: Int = 5
scala> val d = if(n < 18){f = f + n ; m = m + n ; f + m}
d: AnyVal = 23输入和输出
如果要打印一个值,我们用print或println函数。后者在打印完内容后会追加一个换行符。举例来说,
print("Answer:")
println(42)与下面的代码输出的内容相同:
println("Answer:" + 42)另外,还有一个带有C风格格式化字符串的printf函数:system.in
printf("Hello,%s! You are %d years old.\n", "Fred", 42)你可以用readLine函数从控制台读取一行输入。如果要读取数字、Boolean或者是字符,可以用readInt、readDouble、readByte、readShort、readLong、readFloat、readBoolean或者readChar。与其他方法不同,readLine带一个参数作为提示字符串:
scala> val name = readLine("Please input your name:")
Please input your name:name: String = xpleaf一个简单的输入输出案例如下:
val name = readLine("What's Your name: ")
print("Your age: ")
val age = readInt()
if(age > 18) {
printf("Hello, %s! Next year, your will be %d.\n", name, age + 1)
}else{
printf("Hello, %s! You are still a children your will be %d.\n", name, age + 1 +" Come up!!!")
}
}循环之while
Scala拥有与Java和C++相同的while和do循环。例如:
object _04LoopDemo {
def main(args: Array[String]):Unit = {
var sum = 0
var i = 1
while(i < 11) {
sum += i
i += 1
}
}
}循环之do while
Scala 也有do-while循环,它和while循环类似,只是检查条件是否满足在循环体执行之后检查。例如:
object _04LoopDemo {
def main(args: Array[String]):Unit = {
var sum = 0
var i = 1
do {
sum += i
i += 1
} while(i <= 10)
println("1+...+10=" + sum)
}
}登录用户名密码的游戏:三次机会,从控制台输入输入用户名密码,如果成功登录,返回登录成功,失败,则反馈错误信息!如下:
object _05LoopTest {
def main(args: Array[String]):Unit = {
val dbUser = "zhangyl"
val dbPassword = "uplooking"
var count = 3
while(count > 0) {
val name = readLine("亲,请输入用户名:")
val pwd = readLine("请输入密码:")
if(name == dbUser && pwd == dbPassword) {
println("登陆成功,正在为您跳转到主页呐," + name + "^_^")
// count = 0
return
} else {
count -= 1
println("连用户名和密码都记不住,你一天到底在弄啥嘞!您还有<" + count + ">次机会")
}
}
}
}循环之for
Scala没有与for(初始化变量;检查变量是否满足某条件;更新变量)循环直接对应的结构。如果你需要这样的循环,有两个选择:一是使用while循环,二是使用如下for语句:
for (i <- 表达式)让变量i遍历< -右边的表达式的所有值。至于这个遍历具体如何执行,则取决于表达式的类型。对于Scala集合比如Range而言,这个循环会让i依次取得区间中的每个值。
遍历字符串或数组时,你通常需要使用从0到n-1的区间。这个时候你可以用until方法而不是to方法。util方法返回一个并不包含上限的区间。
val s = "Hello"
var sum = 0
for (i <- 0 until s.length) { // i的最后一个取值是s.length - 1
sum += s(i) // 注意此时为对应的ASCII值相加
} 在本例中,事实上我们并不需要使用下标。你可以直接遍历对应的字符序列:
var sum = 0
for (ch <- "Hello") sum += ch循环之跳出循环
说明:Scala并没有提供break或continue语句来退出循环。那么如果需要break时我们该怎么做呢?有如下几个选项:
-
- 使用Boolean型的控制变量。
-
- 使用嵌套函数——你可以从函数当中return。
-
- 使用Breaks对象中的break方法:
object _06LoopBreakTest {
def main(args: Array[String]):Unit = {
import scala.util.control.Breaks._
var n = 15
breakable {
for(c <- "Spark Scala Storm") {
if(n == 10) {
println()
break
} else {
print(c)
}
n -= 1
}
}
}
}循环之for高级特性
1、除了for循环的基本形态之外,Scala也提供了其它丰富的高级特性。比如可以在for循环括号里同时包含多组变量 <- 表达式 结构,组之间用分号分隔
for (i <- 1 to 3;j <- 1 to 3) print ((10 * i +j) + " ")for循环的这种结构类似Java中的嵌套循环结构。
例如要实现一个九九乘法表,使用基本的for循环形态时,代码如下:
object _07LoopForTest {
def main(args: Array[String]):Unit = {
for(i <- 1 to 9) {
for(j <- 1 to i){
var ret = i * j
print(s"$i*$j=$ret\t")
}
// println()
System.out.println()
}
}
}而使用高级for循环时,如下:
object _07LoopForTest {
def main(args: Array[String]):Unit = {
// for(i <- 1 to 9; j <- 1 to 9 if j <= i) {
for(i <- 1 to 9; j <- 1 to i) {
var ret = i * j
print(s"$i*$j=$ret\t")
if(i == j) {
println
}
}
}
}2、if循环守卫
可以为嵌套循环通过if表达式添加条件:
for (i <- 1 to 3; j <- 1 to 3 if i != j) print ((10 * i + j) + " ")if表达式是否添加括号,结果无变化:
for (i <- 1 to 3; j <- 1 to 3 if (i != j)) print ((10 * i + j) + " ")注意:注意在if之前并没有分号。
3、For推导式
Scala中的yield不像Ruby里的yield,Ruby里的yield象是个占位符。Scala中的yield的主要作用是记住每次迭代中的有关值,并逐一存入到一个数组中。用法如下:
for {子句} yield {变量或表达式}1)如果for循环的循环体以yield开始,则该循环会构造出一个集合,每次迭代生成集中的一个值:
scala> for(i <- 1 to 10) yield println(i % 3)
1
2
0
1
2
0
1
2
0
1
res47: scala.collection.immutable.IndexedSeq[Unit] = Vector((), (), (), (), (), (), (), (), (), ())
scala> val ret1 = for(i <- 1 to 10) yield(i)
ret1: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> for(i <- ret1) println(i)
1
2
3
4
5
6
7
8
9
102) for 循环中的 yield 会把当前的元素记下来,保存在集合中,循环结束后将返回该集合
Scala中for循环是有返回值的。如果被循环的是Map,返回的就是Map,被循环的是List,返回的就是List,以此类推。
yield关键字的简短总结:
1.针对每一次for循环的迭代, yield会产生一个值,被循环记录下来(内部实现上,像是一个缓冲区)
2.当循环结束后, 会返回所有yield的值组成的集合
3.返回集合的类型与被遍历的集合类型是一致的异常处理
Scala的异常处理和其它语言比如Java类似,一个方法可以通过抛出异常的方法而不返回值的方式终止相关代码的运行。调用函数可以捕获这个异常作出相应的处理或者直接退出,在这种情况下,异常会传递给调用函数的调用者,依次向上传递,直到有方法处理这个异常。
object _01ExceptionDemo {
def main(args:Array[String]):Unit = {
import scala.io.Source
import java.io.FileNotFoundException
try {
val line = Source.fromFile("./wordcount.txt").mkString
val ret = 1 / 0
println(line)
} catch {
case fNFE:FileNotFoundException => {
println("FileNotFoundException:文件找不到了,传的路径有误。。。")
}
case e:Exception => {
println("Exception: " + e.getMessage)
}
case _ => println("default处理方式")
} finally {
println("this is 必须要执行的语句")
}
}
}Scala函数
函数的定义与调用(类成员函数)
Scala除了方法外还支持函数。方法对对象进行操作,函数不是。要定义函数,你需要给出函数的名称、参数和函数体,就像这样:

下面是需要注意的问题:
- 1、你必须给出所有参数的类型。不过,只要函数不是递归的,你就不需要指定返回类型。Scala编译器可以通过=符号右侧的表达式的类型推断出返回类型。
- 2、“=”并不只是用来分割函数签名和函数体的,它的另一个作用是告诉编译器是否对函数的返回值进行类型推断!如果省去=,则认为函数是没有返回值的!
def myFirstFunction(name:String, age:Int) : String ={
println("name=> " + name +"\t age=> " + age)
"Welcome " + name + " to our world, your age is => " + age
}在本例中我们并不需要用到return。我们也可以像Java或C++那样使用return,来立即从某个函数中退出,不过在Scala中这种做法并不常见。
提示:虽然在带名函数中使用return并没有什么不对(除了浪费7次按键动作外),我们最好适应没有return的日子。很快,你就会使用大量匿名函数,这些函数中return并不返回值给调用者。它跳出到包含它的带名函数中。我们可以把return当做是函数版的break语句,仅在需要时使用。
无返回值的函数
def myFirstFunctionWithoutFeedBackValues: Unit ={
println("This is our first function without feedback values")
}单行函数
def printMsg(name:String) = println("Hello, " + name +", welcome happy day!!!")上面所对应函数的案例如下:
/**
注意:
1.scala中如果要给一个函数做返回值,可以不用return语句,
使用也是可以的,但是scala语言强烈建议大家不要用
因为scala崇尚的是简约而不简单
一般也就是将这个return当做break来使用
2.在scala中在同一条语句中,变量名不能和引用函数名重复
3.使用递归时,需要指定返回值类型
*/
object _02FunctionDemo {
def main(args:Array[String]):Unit = {
// val ret = myFirstFunc("xpleaf", 23)
// println(ret)
// show("xpleaf", 23)
// val ret = singleLineFunc("xpleaf")
// println(ret)
val ret = factorial(5)
println(ret)
}
def testFunc(num:Int) = {
if(num == 1) {
1
}
10
}
// 使用递归来求解5的阶乘
def factorial(num:Int):Int = {
if(num == 1) {
1
} else {
num * factorial(num - 1)
}
// 如果num * factorial(num - 1)不写在else里面,则需要return,否则会有异常,
// testFunc中则不会这样,所以猜测递归函数才会有此问题
}
// 单行函数
def singleLineFunc(name:String) = "hello, " + name // 有"="号,有返回值,自动判断返回值类型
// def singleLineFunc(name:String) {"hello, " + name} // 没有“=”号,没有返回值
// def singleLineFunc(name:String):Unit = "hello, " + name // 有"="号,但指定返回值为空,相当于没有返回值
// def singleLineFunc(name:String) = println("hello, " + name) // 没有返回值,println并不是一个表达式
// 没有返回值的函数
def show(name:String, age:Int):Unit = {
println(s"My name is $name, and I'm $age years old.")
}
// 有返回值的函数
def myFirstFunc(name:String, age:Int):String = {
println(s"My name is $name, and I'm $age years old.")
// return "Welcome you " + name + ", make yourself..."
"Welcome you " + name + ", make yourself..."
}
}默认参数和带名参数
1、我们在调用某些函数时并不显式地给出所有参数值,对于这些函数我们可以使用默认参数。
def sayDefaultFunc(name: String, address: String = "Beijing", tellphone: String ="139****") ={
println(name +"address=> " + address +"\t tellphone=> " + tellphone)
}2、不指定具体参数时:给出默认值
sayDefaultFunc("Garry")3、如果相对参数的数量,你给出的值不够,默认参数会从后往前逐个应用进来。
sayDefaultFunc("Garry","Shanhai")4、给出全部的参数值
sayDefaultFunc("Garry","Shanhai","13709872335")5、带名参数可以让函数更加可读。它们对于那些有很多默认参数的函数来说也很有用。
sayDefaultFunc(address ="上海", tellphone="12109876543",name="Tom")6、你可以混用未命名参数和带名参数,只要那些未命名的参数是排在前面的即可:
sayDefaultFunc("Tom",tellphone="12109876543",address= "上海")可变参数(一)
前面我们介绍的函数的参数是固定的,本篇介绍Scala函数支持的可变参数列表,命名参数和参数缺省值定义。
重复参数
Scala在定义函数时允许指定最后一个参数可以重复(变长参数),从而允许函数调用者使用变长参数列表来调用该函数,Scala中使用“*”来指明该参数为重复参数。例如
Scala:
def echo(args: String*) = {
for (arg <- args) println(arg)
}Java:
public staticvoid echo(String ...args){
for(String str: args){
System.out.println(str)
}
}可变参数(二)
1、在函数内部,变长参数的类型,实际为一数组,比如上例的String* 类型实际为 Array[String]。
然而,如今你试图直接传入一个数组类型的参数给这个参数,编译器会报错:
val arr= Array("Spark","Scala","AKKA")
Error message as bellows:
error: type mismatch;2、为了避免这种情况,你可以通过在变量后面添加_*来解决,这个符号告诉Scala编译器在传递参数时逐个传入数组的每个元素,而不是数组整体
val arr= Array("Spark","Scala","AKKA")
echo(arr:_*)一个例子如下:
object _04FunctionDemo {
def main(args:Array[String]):Unit = {
show("Spark", "Strom", "Hadoop")
var arr = Array("Spark", "Strom", "Hadoop")
show(arr:_*)
}
def show(strs:String*) {
for(str <- strs) {
println(str)
}
}
}过程
1、Scala对于不返回值的函数有特殊的表示法。如果函数体包含在花括号当中但没有前面的=号,那么返回类型就是Unit。这样的函数被称做过程(procedure)。过程不返回值,我们调用它仅仅是为了它的副作用。
案例:
如:我们需要打印一些图案,那么可以定义一个过程:
def draw(str:String) {
println("-------")
println("|"+" "+"|")
println("|"+ str +"|")
println("|"+" "+"|")
println("-------")
}2、我们也可以显示指定的函数的返回值:Unit
Scala Lazy特性
1、当val被声明为lazy时,它的初始化将被推迟,直到我们首次对它取值。例如,
lazy val lines= scala.io.Source.fromFile("D:/test/scala/wordcount.txt").mkString2、如果程序从不访问lines ,那么文件也不会被打开。但故意拼错文件名。在初始化语句被执行的时候并不会报错。不过,一旦你访问words,就将会得到一个错误提示:文件未找到。
3、懒值对于开销较大的初始化语句而言十分有用。它们还可以应对其他初始化问题,比如循环依赖。更重要的是,它们是开发懒数据结构的基础。(spark 底层严重依赖这些lazy)
4、加载(使用它的时候才会被加载)
println(lines)一个例子如下:
object _05LazyDemo {
def main(args:Array[String]):Unit = {
import scala.io.Source
import java.io.FileNotFoundException
try {
lazy val line = Source.fromFile("./wordcountq.txt").mkString // wordcountq.txt这个文件并不存在
// println(line)
} catch {
case fNFE:FileNotFoundException => {
println("FileNotFoundException:文件找不到了,传的路径有误。。。")
}
case e:Exception => {
println("Exception: " + e.getMessage)
}
} finally {
println("this is 必须要执行的语句")
}
}
}