自己动手写docker笔记(2)Linux Cgroups
书中讲到,之前介绍的是构建Linux容器的namespace技术,它能够很好的帮助进程隔离出自己单独的空间,但Docker又是怎么限制每个空间的大小,保证他们不会互相争抢呢?这就要用到Linux的Cgroups技术。
概念
Linux Cgroups(Control Groups) 提供了对一组进程及将来的子进程的资源的限制 ,控制和统计的能力,这些资源包括CPU,内存,存储,网络等。通过Cgroups,可以方便的限制某个进程的资源占用,并且可以实时的监控进程的监控和统计信息。
Cgroups中的三个组件:
Linux Cgroups有三个重要的组件:
cgroup
cgroup 是对进程分组管理的一种机制,一个cgroup包含一组进程,并可以在这个cgroup上增加Linux subsystem的各种参数的配置,将一组进程和一组subsystem的系统参数关联起来。亦即,管理“组进程”并关联参数-
subsystem
subsystem 是一组资源控制的模块,一般包含有:- blkio 设置对块设备(比如硬盘)的输入输出的访问控制(block/io)
- cpu 设置cgroup中的进程的CPU被调度的策略
- cpuacct 可以统计cgroup中的进程的CPU占用(cpu account)
- cpuset 在多核机器上设置cgroup中的进程可以使用的CPU和内存(此处内存仅使用于NUMA架构)
- devices 控制cgroup中进程对设备的访问
- freezer 用于挂起(suspends)和恢复(resumes) cgroup中的进程
- memory 用于控制cgroup中进程的内存占用
- net_cls 用于将cgroup中进程产生的网络包分类(classify),以便Linux的tc(traffic controller) (net_classify) 可以根据分类(classid)区分出来自某个cgroup的包并做限流或监控。
- net_prio 设置cgroup中进程产生的网络流量的优先级
- ns 这个subsystem比较特殊,它的作用是cgroup中进程在新的namespace fork新进程(NEWNS)时,创建出一个新的cgroup,这个cgroup包含新的namespace中进程。
每个subsystem会关联到定义了相应限制的cgroup上,并对这个cgroup中的进程做相应的限制和控制,这些subsystem是逐步合并到内核中的
可以通过安装cgroup的命令行工具(apt-get install cgroup-bin)看到当前的内核支持哪些subsystem,然后通过lssubsys看到kernel支持的subsystem。
taroballs@taroballs-PC:~$ lssubsys
cpuset
cpu,cpuacct
blkio
memory
devices
freezer
net_cls,net_prio
perf_event
pids
- hierarchy
hierarchy 的功能是把一组cgroup串成一个树状的结构,一个这样的树便是一个hierarchy,通过这种树状的结构,Cgroups可以做到继承。比如我的系统对一组定时的任务进程通过cgroup1限制了CPU的使用率,然后其中有一个定时dump日志的进程还需要限制磁盘IO,为了避免限制了影响到其他进程,就可以创建cgroup2继承于cgroup1并限制磁盘的IO,这样cgroup2便继承了cgroup1中的CPU的限制,并且又增加了磁盘IO的限制而不影响到cgroup1中的其他进程。
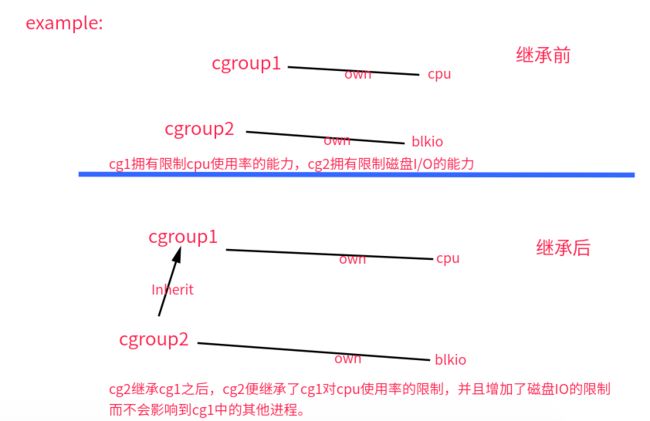
三个组件相互的关系:
通过上面的组件的描述我们就不难看出,Cgroups的是靠这三个组件的相互协作实现的,那么这三个组件是什么关系呢?
- 系统在创建新的hierarchy之后,系统中所有的进程都会加入到这个hierarchy的根cgroup节点中,这个cgroup根节点是hierarchy默认创建,后面在这个hierarchy中创建cgroup都是这个根cgroup节点的子节点。
- 一个subsystem只能附加到一个hierarchy上面
- 一个hierarchy可以附加多个subsystem
- 一个进程可以作为多个cgroup的成员,但是这些cgroup必须是在不同的hierarchy中
- 一个进程fork出子进程的时候,子进程是和父进程在同一个cgroup中的,也可以根据需要将其移动到其他的cgroup中。
这些都是cgroup之间约定俗成的一些规定。
kernel接口:
上面介绍了那么多的Cgroups的结构,那到底要怎么调用kernel才能配置Cgroups呢?
之前了解到Cgroups中的hierarchy是一种树状的组织结构,Kernel为了让对Cgroups的配置更直观,Cgroups通过一个虚拟的树状文件系统去做配置的,通过层级的目录虚拟出cgroup树,下面我们就以一个配置的例子来了解下如何操作Cgroups。
首先,我们要创建并挂载一个hierarchy(cgroup树):
```
➜ ~ mkdir cgroup-test # 创建一个hierarchy挂载点
➜ ~ sudo mount -t cgroup -o none,name=cgroup-test cgroup-test ./cgroup-test # 挂载一个hierarchy
➜ ~ ls ./cgroup-test # 挂载后我们就可以看到系统在这个目录下生成了一些默认文件
cgroup.clone_children cgroup.procs cgroup.sane_behavior notify_on_release release_agent tasks
```

分别讲解下这些文件,它们就是这个hierarchy中根节点cgroup配置项:
-
cgroup.clone_childrencpuset的subsystem会读取这个配置文件,如果这个的值是1(默认是0),子cgroup才会继承父cgroup的cpuset的配置。 -
cgroup.procs是树中当前节点的cgroup中的进程组ID,现在我们在根节点,这个文件中是会有现在系统中所有进程组ID。 -
notify_on_release和release_agent会一起使用,notify_on_release表示当这个cgroup最后一个进程退出的时候是否执行release_agent,release_agent则是一个路径,通常用作进程退出之后自动清理掉不再使用的cgroup。 -
tasks也是表示该cgroup下面的进程ID,如果把一个进程ID写到tasks文件中,便会将这个进程加入到这个cgroup中。
然后,我们创建在刚才创建的hierarchy的根cgroup中扩展出两个子cgroup:
➜ cgroup-test sudo mkdir cgroup-1 # 创建子cgroup "cgroup-1"
➜ cgroup-test sudo mkdir cgroup-2 # 创建子cgroup "cgroup-1"
➜ cgroup-test tree
.
|-- cgroup-1
| |-- cgroup.clone_children
| |-- cgroup.procs
| |-- notify_on_release
| `-- tasks
|-- cgroup-2
| |-- cgroup.clone_children
| |-- cgroup.procs
| |-- notify_on_release
| `-- tasks
|-- cgroup.clone_children
|-- cgroup.procs
|-- cgroup.sane_behavior
|-- notify_on_release
|-- release_agent
`-- tasks
其次,在cgroup中添加和移动进程:
1.一个进程在一个Cgroups的hierarchy中只能存在在一个cgroup节点上,
2.系统的所有进程默认都会在根节点,
3.可以将进程在cgroup节点间移动,只需要将进程ID写到移动到的cgroup节点的tasks文件中。
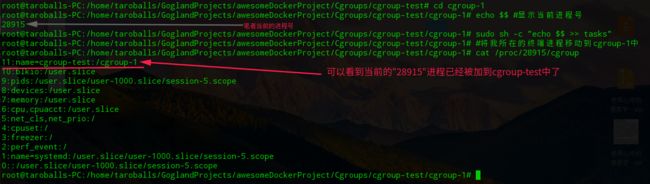
最后,通过subsystem限制cgroup中进程的资源
上面我们创建hierarchy的时候,但这个hierarchy并没有关联到任何subsystem,所以没办法通过那个hierarchy中的cgroup限制进程的资源占用,其实系统默认就已经把每个subsystem创建了一个默认的hierarchy,比如memory的hierarchy:

可以看到,在/sys/fs/cgroup/memory目录便是挂在了memory subsystem的hierarchy。下面我们就通过在这个hierarchy中创建cgroup,限制下占用的进程占用的内存:
➜ memory stress --vm-bytes 200m --vm-keep -m 1 # 首先,我们不做限制启动一个占用内存的stress进程
➜ memory sudo mkdir test-limit-memory && cd test-limit-memory # 创建一个cgroup
➜ test-limit-memory sudo sh -c "echo "100m" > memory.limit_in_bytes" sudo sh -c "echo "100m" > memory.limit_in_bytes" # 设置最大cgroup最大内存占用为100m
➜ test-limit-memory sudo sh -c "echo $ > tasks" # 将当前进程移动到这个cgroup中
➜ test-limit-memory stress --vm-bytes 200m --vm-keep -m 1 # 再次运行占用内存200m的的stress进程
运行结果如下(通过top监控):
#本机内存为2GB,未限制前内存占用约200m (2GB*10.9%==218M)实际为(1834M*10.9%==200M)
PID PPID TIME+ %CPU %MEM PR NI S VIRT RES UID COMMAND
2352 root 20 0 212056 204800 132 R 99.9 10.9 3:13.62 stress
cd /sys/fs/cgroup/memory/
sudo mkdir test-limit-memory
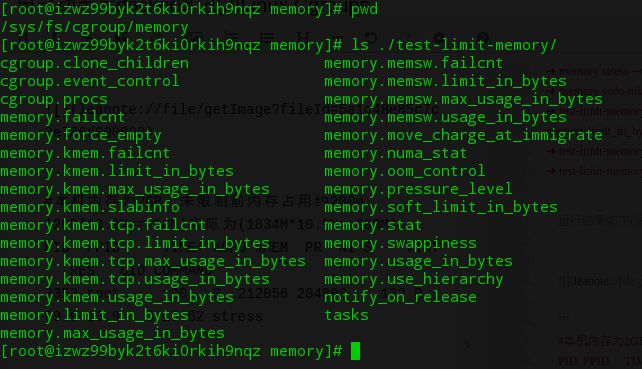
cd test-limit-memory/
#设置最大cgroup的最大内存占用为100m
sudo sh -c "echo "100m" > memory.limit_in_bytes"
#将当前进程 移动到这个cgroup中
sudo sh -c "echo $ > tasks"

限制内存占用为100M
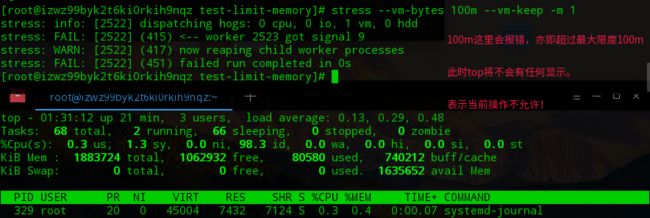
限制内存占用为99.9M(2GB~~1834MB*0.054==99.036MB)
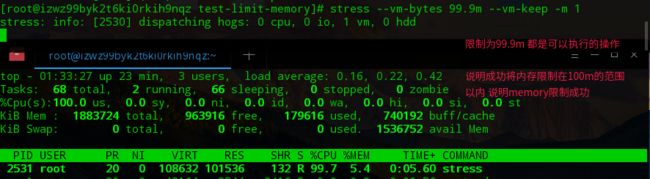
#限制后内存占用约99.9M (2GB*5%==100M)
PID PPID TIME+ %CPU %MEM PR NI S VIRT RES UID COMMAND
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2531 root 20 0 108632 101536 132 R 99.7 5.4 1:32.70 stress
可以看到通过cgroup,我们成功的将stress进程的最大内存占用限制到了100m以内。 这里笔者不予演示,笔者的系统不支持stress
清理一下

Docker是如何使用Cgroups的:
我们知道Docker是通过Cgroups去做的容器的资源限制和监控,我们下面就以一个实际的容器实例来看下Docker是如何配置Cgroups的:

可以看到Docker通过为每个容器创建Cgroup并通过Cgroup去配置的资源限制和资源监控。
用go语言实现通过cgroup限制容器的资源
package main
import (
"os/exec"
"path"
"os"
"fmt"
"io/ioutil"
"syscall"
"strconv"
)
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
func main() {
if os.Args[0] == "/proc/self/exe" {
//容器进程
fmt.Printf("current pid %d", syscall.Getpid())
fmt.Println()
cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
} else {
//得到fork出来进程映射在外部命名空间的pid
fmt.Printf("%v", cmd.Process.Pid)
// 在系统默认创建挂载了memory subsystem的Hierarchy上创建cgroup
os.Mkdir(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit"), 0755)
// 将容器进程加入到这个cgroup中
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "tasks") , []byte(strconv.Itoa(cmd.Process.Pid)), 0644)
// 限制cgroup进程使用
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "memory.limit_in_bytes") , []byte("100m"), 0644)
}
cmd.Process.Wait()
}
通过对Cgroups虚拟文件系统的配置,我们让容器中的把stress进程的内存占用限制到了100m。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10861 root 20 0 212284 102464 212 R 6.2 5.0 0:01.13 stress