一,node.js的作用,
I/O的意义,(I/O是输入/输出的简写,如:键盘敲入文本,输入,屏幕上看到文本显示输出。鼠标移动,在屏幕上看到鼠标的移动。终端的输入,和看到的输出。等等)
node.js想解决的问题,(处理输入,输入,高并发 。如 在线游戏中可能会有上百万个游戏者,则有上百万的输入等等)(node.js适合的范畴:当应用程序需要在网络上发送和接收数据时Node.js最为适合。这可能是第三方的API,联网设备或者浏览器与服务器之间的实时通信)
并发的意义,(并发这个术语描述的是事情会在同时发生并可能相互交互。Node的事件化的I/O模型让我们无需担心互锁和并发这两个在多线程异步I/O中常见的问题)
演示网络I/O
Js代码
var http = require('http'),
urls = ['www.baidu.com','www.10jqka.com.cn','www.duokan.com'];
function fetchPage(url){
var start = new Date();
http.get({host:url},function(res){
console.log("Got response from:" + url);
console.log("Request took:",new Date() - start, "ms");
});
}
for(var i=0; i
命名为,node.js
我们在终端里面运行node node.js
输出:

我们要求node.js访问三个url并报告收到响应的情况以及所耗费的时间。
我们可以看到两次输出的时间是不一样的。受各种影响,解析DNS请求的时间,服务器繁忙程序等等。
为什么javascript是一个事件驱动的语言
javascript围绕着最初与文档对象模型(DOM)相关的事件架构。开发人员可以在事件发生时做事情。这些事件有用户点击一个元素,页面完成加载等。使用事件,开发人员可以编写事件的监听器,当事件发生时被触发。
二,回调(Callback)
1,什么是回调
2,剖析回调
回调指的是将一个函数作为参数传递给另一个函数,并且通常在第一个函数完成后被调用。
例子:如jquery中的hide()方法,
Js代码
1,$("p").hide('slow');
2,$("p").hide('slow',function(){alert("The paragraph is now hidden")});
回调是可选的,
1就不需要回调
2,是有回调的,当段落隐藏完成后它就会被调用,显示一个alert提示。
为了可以看到带与不带回调的代码之间的区别
Js代码
$("p").hide('slow');
alert("The paragraph is now hidden");//1
$("p").hide('slow',function(){alert("The paragraph is now hidden")});//2
1,是没有回调,,执行顺序是一样但是,我们可以看到p段落还没有隐藏完全,alert就出来
2,是有回调的,执行则是hide完成后在alert
剖析回调
Js代码
function haveBreakfast(food,drink,callback){
console.log('Having barakfast of' + food + ', '+ drink);
if(callback && typeof(callback) === "function"){
callback();
}
}
haveBreakfast('foast','coffee',function(){
console.log('Finished breakfast. Time to go to work!');
});
输出:
Having barakfast of foast,coffee Finished breakfast. Time to go to work!
这里是创建了一个函数,有三个参数,第三个参数是callback,这个参数必须是个函数。
haveBreakfast函数将所吃的东西记录到控制台中然后调用作为参数传递给它的回调函数。
Node.js如何使用回调
node.js中使用filesystem模块从磁盘上读入文件内容的示例
Js代码
var fs = require('fs');
fs.readFile('somefile.txt','utf8',function(err,data){
if(err) throw err;
console.log(data);
});
结果是:somefile.txt里面的内容。
1,fs(filesystem)模块被请求,以便在脚本中使用
2,讲文件系统上的文件路径作为第一个参数提供给fs.readFile方法
3,第二个参数是utf8,表示文件的编码
4,将回调函数作为第三个参数提供给fs.readFile方法
5,回调函数的第一个参数是err,用于保存在读取文件时返回的错误
6,回调函数的第二参数是打他,用户保存读取文件所返回的数据。
7,一旦文件被读取,回调就会被调用
8,如果err为真,那么就会抛出错误
9,如果err为假,那么来自文件的数据就可以使用
10,在本例中,数据会记录到控制台上。
再一个,http模块,http模块使得开发人员可以创建http客户端和服务器。
Js代码
var http = require('http');
http.get({host:'shapeshed.com'},function(res){
console.log("Got response:" + res.statusCode);
}).on('error',function(e){
console.log("Got error:" + e.message);
});
结果:Got response:200
1,请求http模块,以便在脚本中使用
2,给http.get()方法提供两个参数
3,第一个参数是选项对象。在本示例中,要求获取shapeshed.com的主页
4,第二个参数是一个以响应作为参数的回调函数
5,当远程服务器返回相应时,会触发回调函数。
6,在回调函数内记录响应状态码,如果有错误的话可以记录下来。
接下来,我们看看有4个不同的I/O操作都在发生,他们都使用回调
Js代码
var fs = require('fs'),
http = require('http');
http.get({host:'www.baidu.com'},function(res){
console.log("baidu.com");
}).on('error',function(e){
console.log("Got error:" + e.message);
});
fs.readFile('somefile.txt','utf8',function(err,data){
if(err) throw err;
console.log("somefile");
});
http.get({host:'www.duokan.com'},function(res){
console.log("duokan.com");
}).on('error',function(e){
console.log("Got error:" + e.message);
});
fs.readFile('somefile2.txt','utf8',function(err,data){
if(err) throw err;
console.log("somefile2");
});
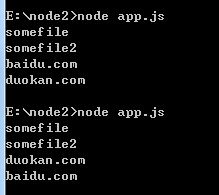
我们能知道哪个操作先返回吗?
猜测就是从磁盘上读取的两个文件先返回,因为无需进入网络,但是我们很难说哪个文件先返回,因为我们不知道文件的大小。对于两个主页的获取,脚本要进入网络,而响应时间则依赖于许多难以预测的事情,Node.js进程在还有已经注册的回调尚未触发之前将不会退出。回调首先解决不可预测性的方法,他也是处理并发(或者说一次做超过一件事情)的高效方法。
下面是我执行的结果
同步和异步代码
先看代码,同步(或者阻塞)代码
Js代码
function sleep(milliseconds){
var start = new Date().getTime();
while((new Date().getTime() -start) < milliseconds){
}
}
function fetchPage(){
console.log('fetching page');
sleep(2000);
console.log('data returned from requesting page');
}
function fetchApi(){
console.log('fetching api');
sleep(2000);
console.log('data returned from the api');
}
fetchPage();
fetchApi();
当脚本运行时,fetchPage()函数会被调用,直到它返回之前,脚本的运行是被阻塞的,在fetchPage()函数返回之前,程序是不能移到fetchApi()函数中的。这称为阻塞操作。
Node.js几乎从不使用这种编码风格,而是异步地调用回调。
看下下面编码,,
Js代码
var http = require('http');
function fetchPage(){
console.log('fetching page');
http.get({host:'www.baidu.com',path:'/?delay=2000'},
function(res){
console.log('data returned from requesting page');
}).on('error',function(e){
console.log("There was an error" + e);
});
}
function fetchApi(){
console.log('fetching api');
http.get({host:'www.baidu.com',path:'/?delay=2000'},
function(res){
console.log('data returned from requesting api');
}).on('error',function(e){
console.log("There was an error" + e);
});
}
fetchPage();
fetchApi();
允许这段代码的时候,就不再等待fetchPage()函数返回了,fetchApi()函数随之立刻被调用。代码通过使用回调,是非阻塞的了。一旦调用了,两个函数都会侦听远程服务器的返回,并以此触发回调函数。
注意这些函数的返回顺序是无法保证的,而是和网络有关。
事件循环
Node.js使用javascript的事件循环来支持它所推崇的异步编程风格。基本上,事件循环使得系统可以将回调函数先保存起来,而后当事件在将来发生时再运行。这可以是数据库返回数据,也可以是HTTP请求返回数据。因为回调函数的执行被推迟到事件反生之后,于是就无需停止执行,控制流可以返回到Node运行时的环境,从而让其他事情发生。
Node.js经常被当作是一个网络编程框架,因为它的设计旨在处理网络中数据流的不确定性。促成这样的设计的是事件循环和对回调的使用,他们似的程序员可以编写对网络或I/O事件进行响应的异步代码。
需要遵循的规则有:函数必须快速返回,函数不得阻塞,长时间运行的操作必须移到另一个进程中。
Node.js所不适合的地方包括处理大量数据或者长时间运行计算等。Node.js旨在网络中推送数据并瞬间完成。