Overall Introduction
Observation: Worst-case point lookup cost, long-range lookup cost, and space amplification derive mostly from the largest level.
Infer: Merge operations at all levels of LSM-tree but the largest hardly improve on these metrics while significantly adding to the amortized cost of updates.
Result: Suboptimal trade-offs of the state-of-the-art.
The balance between the I/O cost of merging and the I/O cost of lookups and space-amplification can be tuned using two knobs.
- The size ratio T between the capacities of adjacent levels; T controls the number of levels of LSM-tree and thus the overall number of times that entry gets merged across levels.
- Merge policy; It controls the number of times an entry gets merged within a level.
Major 2 Merge Policies
- Tiering
-
Leveling
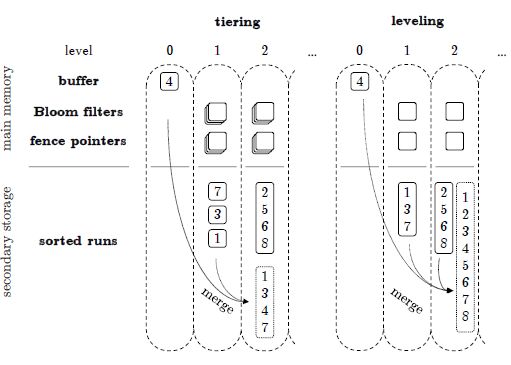 Overview of an LSM-tree using tiering and leveling merge policies
Overview of an LSM-tree using tiering and leveling merge policies
In both cases, the merge is triggered by the buffer flushing and causing Level 1 to reach capacity. With tiering, all runs at Level 1 get merged into a new run that gets placed at Level 2. With leveling, the merge also includes the preexisting run at Level 2.
Size-Tiered compaction strategy (STCS). The idea of STCS is fairly straightforward, as illustrated here:
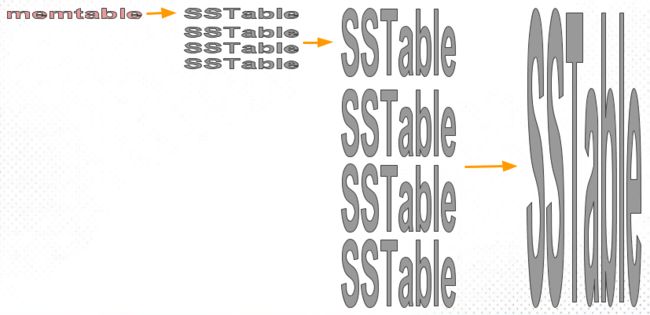 image.png
image.png
As usual, memtables are periodically flushed to new sstables. These are pretty small, and soon their number grows. As soon as we have enough (by default, 4) of these small sstables, we compact them into one medium sstable. When we have collected enough medium tables, we compact them into one large table. And so on, with compacted sstables growing increasingly large.
The full STCS algorithm is more complex than what we just described, because sstables may have overlapping data or deletions and thus the compacted sstables have varying sizes that don’t fall neatly into “small, medium, large, etc.” categories. Therefore STCS tries to fit the sstables into buckets of similarly-sized sstables, and compacts sstables within each of these buckets. Understanding these details is not necessary for the point of this post, but if you’re curious, refer to this blog post from 2014 or any other documentation of Scylla’s or Cassandra’s size-tiered compaction strategy.
Size-tiered compaction has several compelling properties which made it popular as the first and default compaction strategy of Cassandra and Scylla, and of many other LSM implementations. It results in a low and logarithmic (in size of data) number of sstables, and the same data is copied during compaction a fairly low number of times. We’ll address these issues again, using measures called read amplification and write amplification, in the following posts. In this post, we want to focus on the weakest aspect of size-tiered compaction, known as space amplification. This weakness is what eventually led to the development of alternative compaction strategies, such as leveled compaction and hybrid compaction which we will investigate in the next two posts.
总结: 针对Size-tiered compaction,每一层最多有T个sstable,每一个sstable里面的key均为有序的。每T个sstable会被merge成一个大的sstable到下一层。即为图中所示,sstable一层比一层大T倍。size-tiered compaction的写放大相对较小,但存在space amplification的问题。space amplification 意味着存储的大小大于数据被一个sstable所存储的大小。导致space amplification的原因是在merge的过程当中,需要同时保持上一层和merge后的一层的数据,最终导致数据大小翻倍。另外一种merge策略Leveled Compaction Strategy (LCS)意图解决space amplification的问题,但带来了新的问题:write amplification。
The Leveled Compaction Strategy was the second compaction strategy introduced in Apache Cassandra. It was first introduced in Cassandra 1.0 in 2011, and was based on ideas from Google’s LevelDB. As we will show below, it solves STCS’s space-amplification problem. It also reduces read amplification (the average number of disk reads needed per read request), which we will not further discuss in this post.
The first thing that Leveled Compaction does is to replace large sstables, the staple of STCS, by “runs” of fixed-sized (by default, 160 MB) sstables. A run is a log-structured-merge (LSM) term for a large sorted file split into several smaller files. In other words, a run is a collection of sstables with non-overlapping token ranges. The benefit of using a run of fragments (small sstables) instead of one huge sstable is that with a run, we can compact only parts of the huge sstable instead of all of it. Leveled compaction indeed does this, but its cleverness is how it does it:
Leveled compaction divides the small sstables (“fragments”) into levels:
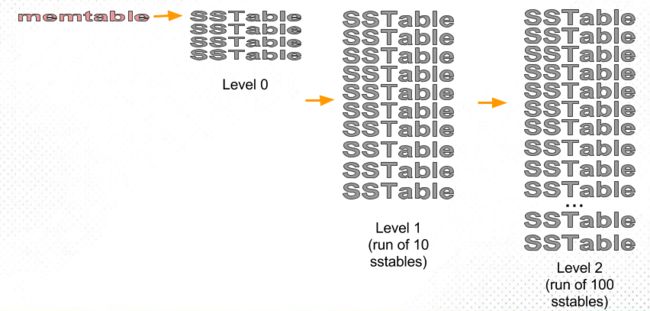 image.png
image.png
Level 0 (L0) is the new sstables, recently flushed from memtables. As their number grows (and reads slow down), our goal is to move sstables out of this level to the next levels.
Each of the other levels, L1, L2, L3, etc., is a single run of an exponentially increasing size: L1 is a run of 10 sstables, L2 is a run of 100 sstables, L3 is a run of 1000 sstables, and so on. (Factor 10 is the default setting in both Scylla and Apache Cassandra).
The job of Leveled compaction strategy is to maintain this structure while keeping L0 empty:
- When we have enough (e.g., 4) sstables in L0, we compact them into L1.
We do this by compacting all the sstables in L0 together with all the sstables in L1. The result of this compaction is a new run (large sstable split by our chosen size limit, by default 160 MB) which we put in L1, replacing the entire content of L1.- The new run in L1 may have more than the desired 10 sstables. If that happens, we pick one sstable from L1 and compact it into L2:
- A single sstable in L1 is part of a run of 10 files. The whole run covers the entire token range, which means that the single sstable we chose covers roughly 1/10th of the token range. At the same time, each of the L2 sstables covers roughly 1/100th of the token range. So the single L1 sstable we are compacting will overlap around 10 of the L2 sstables.
- So what we do is to take the single L1 sstable and the roughly 10 L2 sstables which overlap its token range, and compact those together – as usual splitting the result into small sstables. We replace the input sstables with the compaction results, putting the results in L2 (note that L2 remains a single run).
- After we compacted a table from L1 into L2, now L2 may have more than the desired number of sstables, so we compact sstables from L2 into L3. Again, this involves compacting one sstable from L2 and about 10 sstables from L3.
And so on.
总结:针对Leveled Compaction Strategy,引入runs的概念。一个run包含多个小sstable。每次merge为一个run和另外一个run之间的操作。为了优化merge操作,merge的时候选择一个sstable和下一层的对应key range的T个sstable进行merge。
Fence Pointer
All major LSM-tree based key-value stores index the first key of every block of every run in main memory. These are called fence pointers. The fence pointers take up O(N/B) space in main memory, and they enable a lookup to find the relevant key-range at every run with one I/O.
Bloom Filters
Objective: speed up the point lookups. Each run has a Bloom filter in main memory.
A Bloom Filter is a space-efficient probabilistic data structure used to answer set membership queries.
The false positive rate (FPR) depends on the ratio between the number of bits allocated to the filter and the number of entries in the set.
A point lookup probes a Bloom filter before accessing the corresponding run in storage. If the filter returns a true positive, the lookup access the run with one I/O (using the fence pointers), finds the matching entry and terminates.
If the filter returns a negative, the lookup skips the run thereby saving one I/O.
Otherwise, we have a false positive, meaning the lookup wastes one I/O by accessing the run, not finding a matching entry, and having to continue searching for the target key in the next run.
Design Space and Problem Analysis
Analysis: worse-case space-amplification and I/O costs of updates and lookups.
- merge policy
- size ratio
Note:
- In key-value stores in industry, the number of bits per entry for Bloom Filters across all levels is the same. Therefore, the Bloom Filters at the largest level are larger than the filters at all smaller levels combines.
- The FPR at the largest level is upper bounded to O(e^{-M/N}), where M is the memory budget for all filters and N is the number of entries in the system.