函数定义与调用
#python中如何函数无返回值, 默认返回None;
def 函数名(形参)
函数体
return 返回值
函数名(实参)
#打印返回值
print 函数名
#定义了一个函数
def fun(*args): # 形式参数
print args
#调用函数
fun("python", 12, 0) # 实参
#必选参数
#默认参数
#可变参数----> *args args是元组类型
#关键字参数----->**kwargs kwargs是字典类型
函数的形式参数的默认值不要是可变参数;
def add_end(L=[]): # 默认参数 L = [1,2,3]
L.append('END') # [1,2,3, 'END']
return L # return [1,2,3, 'END']
print add_end([1, 2, 3])
print add_end()
print add_end()
print add_end()测试结果:
参数组合时: 必选 > 默认参数 > 可变参数 > 关键字参数
def fun(a, b=0, *c, **d):
print a, b, c, d
fun(1, 2, 4, 5, 6, 7, c=3, x=2, z=2)测试结果:![]()
测试练习:利用函数定义用户管理系统
#!/usr/bin/env python
#coding:utf-8
info = """"
###########user's administration###########
1.add user
2.login user
3.logout user
4.show users'messages
5.exit
"""
userinfor = {
'root': {
'name': 'root',
'password': 'root',
'age': 18,
'sex': 0,
'email': '[email protected]'
},
}
def createUser():
user = raw_input("please input username:")
if user in userinfor:
print " %s exist!!!" % (user)
else:
password = raw_input("*please input password:")
age = raw_input("*please input age:")
sex = raw_input("please input sex:<0:male,1:female>")
if not sex:
sex = None
email = raw_input("please input email:")
if not email:
email = None
userinfor[user] = {
'name': user,
'password': password,
'age': age,
'sex': sex,
'email': email
}
print "%s created!!!" % (user)
def userLogin():
user = raw_input("please input your username:")
if userinfor.has_key(user):
password = raw_input("please input your password:")
if userinfor[user]['password'] == password:
print "%s logined" % (user)
else:
print "error:password doesn't match!!!"
else:
print "error:please create your username!!!"
def userLogout():
user = raw_input("please input username:")
if userinfor.has_key(user):
password = raw_input("please input password:")
if userinfor[user]['password'] == password:
userinfor.pop(user)
print "%s has delet" % (user)
else:
print "error:password doesn't match!!!"
else:
print "error:please input currect username!!!"
def userView():
print userinfor.items()
def main():
print info
while 1:
choice = raw_input("*please input your choice:")
if choice == '1':
createUser()
elif choice == '2':
userLogin()
elif choice == '3':
userLogout()
elif choice == '4':
userView()
elif choice == '5':
exit(0)
else:
print 'error'
if __name__ == "__main__":
main()测试结果: 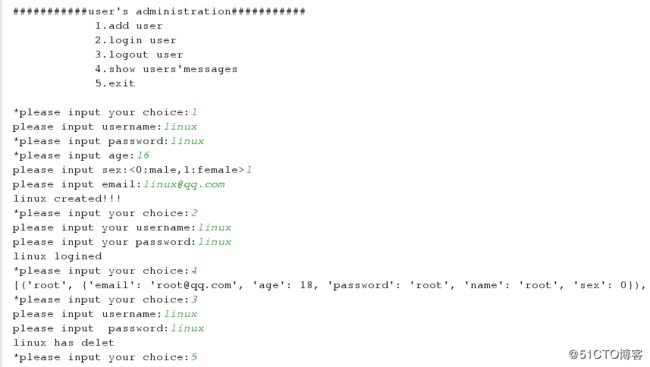
利用函数判断质数
输入描述:输入数字,判断输入数字以内的所有质数,并输出。
def isPrime(n):
for i in range(2, n):
if n % i == 0:
return False
else:
return True
n = input('N:')
print [i for i in range(2,n) if isPrime(i)]测试结果:![]()
迭代器
#!/usr/bin/env python
#coding:utf-8
list()
import collections
li = range(3)
#iter()转化li为迭代对象;
it = li.__iter__()
while True:
try:
print it.next()
except StopIteration:
Break测试结果:
测试练习:斐波那契数列
计算的斐波那契数列前10项
#!/usr/bin/env python
#coding:utf-8
from collections import Iterable
class Fib(object):数列
def __init__(self):
self._a =0
self._b =1
def __iter__(self):
"ob.__iter__() <==> iter(ob)"
return self
def next(self):
self._a, self._b =self._b, self._a+self._b
return self._a
f = Fib()
for i,j in enumerate(f):
if i>9:
break
print j测试结果:
生成器
1.生成器的第1种实现方式: 列表生成式改为生成器;
In [81]: [i for i in range(5)]
Out[81]: [0, 1, 2, 3, 4]
In [82]: (i for i in range(5))
Out[82]: at 0x1e58a00> - return 和 yield的异同点:
#python中yield关键字
函数中如果有yield, 那么调用这个函数的返回值为生成器。
当生成器g调用next方法, 执行函数, 知道遇到yield就停止;
再执行next,从上一次停止的地方继续执行;
函数中遇return直接退出, 不继续执行后面代码;
def fun():
print 'a'
return 'b'
print 'c'
print fun()3.生成器的第2种实现方式;
def fib(max):
num1, num2 = 0, 1
for i in range(max):
yield num2
num1, num2 = num2, num1 + num2
g = fib(100000)
for i, j in enumerate(g):
if i > 10:
break
print j
生成器_无缓冲区的生产者消费者模型
#!/usr/bin/env python
#coding:utf-8
import time
import random
def consumer(name):
print "%s准备买粉条...... " %(name)
while True:
kind = yield
print "客户[%s]购买了[%s]口味的粉条" %(name,kind)
c1 = consumer("jackson")
c1.next()
c1.send("微辣")
def producer(name):
c1 = consumer("roy")
c2 = consumer("jackson")
c1.next()
c2.next()
print "厨师[%s]准备制作粉条......" %(name)
for kind in ["微辣", "麻辣", "三鲜"]:
time.sleep(random.random())
print "[%s]制作了[%s]口味的粉条,卖给了用户......" %(name,kind)
c1.send(kind)
c2.send(kind)
c1.close()
c2.close()
producer("lee")测试结果:
生成器_有缓冲区的生产者消费者模型
#!/usr/bin/env python
#coding:utf-8
import time
import random
cache = []
def consumer(name):
print "%s准备买粉条...... " %(name)
while True:
kind = yield
cache.remove(kind)
print "客户[%s]购买了[%s]口味的粉条" %(name,kind)
def producer(name):
print "厨师[%s]准备制作粉条......" %(name)
for kind in ["微辣", "麻辣", "三鲜"]:
time.sleep(random.random())
print "[%s]制作了[%s]口味的粉条,卖给了用户......" %(name,kind)
cache.append(kind)
producer("lee")
c1 = consumer('roy')
c1.next()
c1.send('微辣')
print "本店现有粉条口味:"
for i in cache:
print i测试结果:
生成器_throw方法
#throw方法: 给生成器发送一个异常;
def gen():
while True:
try:
yield 'a'
yield 'b'
except TypeError:
print 'Type Error'
except ValueError:
print 'value error'
g = gen()
#print g.next()
print next(g) #g.next()<====>next(g)
g.throw(ValueError)
#print g.next()
print next(g)运行结果:
测试练习:迷你的聊天机器人
def chat_robot():
res = ''
while True:
receive = yield res
if 'hi' in receive:
res = "你好"
elif 'name' in receive or '姓名' in receive:
res = "我是机器人小冰......"
elif 'age' in receive or '年龄' in receive:
res = "年龄保密......"
else:
res = "我不太清楚你在说什么,我还在学习中......"
Chat = chat_robot()
next(Chat)
while True:
send_data = raw_input("A>>: ")
if send_data == 'q' or send_data == 'quit':
print "机器人不和你玩了......"
break
response = Chat.send(send_data)
print "Robot>>: %s" %(response)
Chat.close()测试结果:
生成器的优势总结:
-
生成器提供了一种更为便利的产生迭代器的方式, 一般用户不需要自己实现iter和next方法,
它默认返回一个可迭代对象; -
代码更为简洁,优雅;
函数式编程
函数作为实际参数传给函数的函数称为高阶函数
函数名可以看作是变量名;
实际参数可以是函数, 返回值也可以是函数;这样就称为高阶函数;
内置高阶函数map
In [85]: map(abs, [-1, 10, 20, 30, -100])
Out[85]: [1, 10, 20, 30, 100]
In [88]: def fun(x):
return x**2+100
....:
In [89]: map(fun, range(5))
Out[89]: [100, 101, 104, 109, 116]
reduce,第一个参数function,必须能接收两个参数;
In [90]: def add(x, y):
....: return x + y
....: reduce(add, range(5))
....:
Out[90]: 10
阶乘实现:
def jiecheng(x,y):
return x*y
while True:
n = input("N:")
print reduce(jiecheng,range(1,n+1))测试结果:
匿名函数
- 匿名函数的关键字为 lambda, 冒号前面是形式参数, 冒号后面是返回值;
- 匿名函数的形式参数可以是: 必选, 默认, 可变, 关键字参数.
In [92]: f = lambda x, y=2, *args, *kwargs : (xy,args, kwargs)
In [93]: f(2,3,4,5,6,7, a=1, b=2, c=3)
Out[93]: (6, (4, 5, 6, 7), {'a': 1, 'b': 2, 'c': 3})
filter,第一个参数function,返回值必须是Bool值;
In [94]: filter(lambda x: x % 2 == 0, range(1,20))
Out[94]: [2, 4, 6, 8, 10, 12, 14, 16, 18]
输出200-300以内的质数
def isPrime(n):
for i in range(2, n):
if n % i == 0:
return False
else:
return True
li = range(200,301)
print filter(isPrime, li)测试结果:![]()
sorted 排序
由小到大排序
In [95]: sorted([91, 2, 23])
Out[95]: [2, 23, 91]
由大到小排序
In [96]: sorted([91, 2, 23], reverse=True)
Out[96]: [91, 23, 2]
忽略大小写的排序
In [97]: users = ['adam', 'LISA', 'barT', 'Adam']
In [98]: def ignore_cmp(s1, s2):
....: s1 = s1.upper()
....: s2 = s2.upper()
....: return cmp(s1, s2)
....: sorted(users, cmp=ignore_cmp)
....:
Out[98]: ['adam', 'Adam', 'barT', 'LISA']
指定key值进行排序
goods = {
'001': {
'name': 'computer',
'price': 4000,
'count': 20,
},
'002': {
'name': 'apple',
'price': 2,
'count': 100
},
'003': {
'name': 'xiaomi',
'price': 2999,
'count': 10
}
}
#根据价格进行排序, 打印出价格最高的商品名称;
price_sorted_goods = sorted(goods.values(), key=lambda a : a['price'])
print "价格最高的商品名称为:", price_sorted_goods[-1]['name']
#根据商品库存进行排序, 打印出库存最少的商品名称和商品数量;
count_sorted_goods = sorted(goods.values(), key=lambda a : a['count'])
print count_sorted_goods[0]['name'], count_sorted_goods[0]['count']
测试结果:![]()