介 绍
Kubernetes在Github上拥有超过4万颗星,7万以上的commits,以及像Google这样的主要贡献者。Kubernetes可以说已经快速地接管了容器生态系统,成为了容器编排平台中的真正领头羊。
理解Kubernetes和它的Abstractions
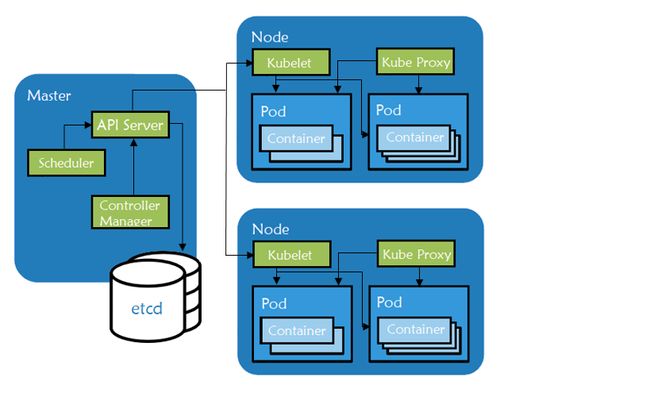
在基础设施层,Kubernetes集群好比是一组扮演特定角色的物理或虚拟机器。其中扮演Master角色的机器作为全部操作的大脑,并由运行在节点上的编排容器控制。
- Master组件管理pod的生命周期,pod是Kubernetes集群中部署的基本单元。pod完成周期,Controller会创建一个新的。如果我们向上或向下(增加减少)Pod副本的数量,Controller会相应的创建和销毁pod来满足请求。Master角色包含了下面组件:
°kube-apiserver – 为其他master组件提供APIs
°etcd – 具有一致性且高可用的key/value存储,用于存储所有内部集群数据
°kube-scheduler – 使用pod规范中的信息来确定运行pod的节点
°kube-controller-manager – 负责节点管理(检测节点是否失败)、pod复制和端点创建
°cloud-controller-manager – 运行与底层云提供商交互的controller
- Node组件是Kubernetes中的worker机器,由Master来管理。一个节点可能表示未一个虚拟机(VM)或者物理机,而Kubernetes都可以在它们上面运行。每个节点都包含了运行pods所需要的组件:
°kubelet:处理Master和运行它的节点之间的所有通信。它在使用container runtime时提供接口来部署和监视容器。
° kube-proxy:维护主机上的网络规则,处理在pods、host和外部世界之间包的传输。
°container runtime:负责在host上运行容器。虽然Kubernetes支持来自rkt、runc以及其他各式的container runtime,当下最流行的引擎还是Docker。
从逻辑层面来看,Kubernetes部署由各种组件组成,每个组件在集群中提供的服务都有特定的目的。
-
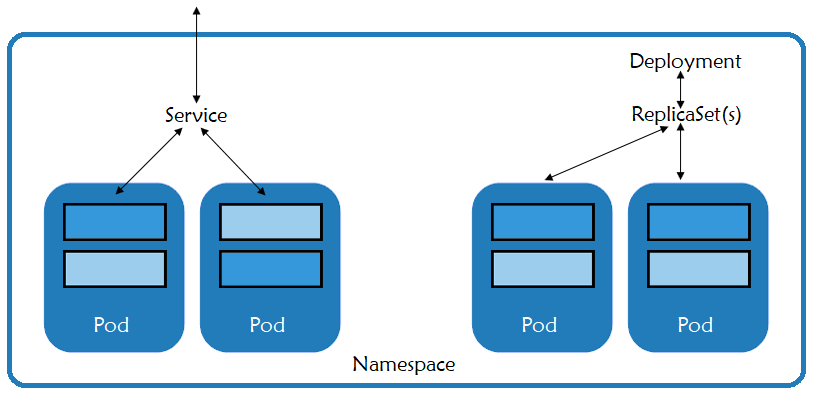
Pods是Kubernetes部署时的基本单元。一个pod由一个或者多个共享相同网络命名空间和IP地址的容器组成。最佳实践推荐我们为每个应用程序创建一个pod,这样你就可以分别扩展和控制它们。
-
Services设置在pods集合之前,给它们提供一致的IP地址以及一套策略用来控制对它们的访问。Service所针对的pod集合通常由label selector(标签选择器)决定。这样在升级或者蓝/绿部署期间很容易就让Service指向不同的pod集合。
-
ReplicaSets由部署控制,并确保运行该部署所需要的pods数量。
-
Namespaces为诸如pods和services资源定义了一个逻辑命名空间。它们允许资源使用相同的名称,而单个命名空间中的资源名称必须唯一。Rancher使用命名空间和机遇角色的访问控制,为命名空间和其中运行的资源之间提供安全隔离。
- Metadata根据容器的部署特性来标记容器。
监控Kubernetes
多个服务和命名空间可以跨基础设施分布。就像上面所说,每个服务都是由pods组成,而pod可以包含一个或多个容器。有了如此多的移动部件,即便是监控一个小型的Kubernetes集群也会带来挑战。为了高效地监控它,这就需要深入了解应用程序体系结构和功能。
Kubernetes提供了用于监控集群的工具:
-
Probes能积极地监控容器的健康状态。如果Probe检测到容器不健康,那么它就会重启容器。
-
cAdvisor是一个开源代理,它监控资源的使用情况并分析容器的性能。cAdvisor最初由Google创建,现在已经和Kubelet集成。它能够收集、聚合、处理和导出在给定节点上运行的所有勇气的度量指标,比如CPU、内存、文件和网络的使用情况。
- kubernetes dashboard(仪表板)是一个附加组件,它能提供集群上运行的资源的概述信息。此外还提供了非常基本的方法来部署这些资源并和它们交互。
Kubernetes由从故障中自动回复的强大能力。如果进程发生崩溃,它可以重新启动pods,如果节点出现错误,它能重新分配pods。然而,尽管有如此能力,还是会有不能解决问题的情况。为了检测到这些情况,我们还需要额外的监控。
监控的层次
基础设施
服务器级别的问题会在工作负载中出现,因此所有集群都应该监控底层服务器组件
监控什么
CPU利用率。监控CPU既能显示系统和用户的开销,也能显示iowait。挡在云中或者任何网络存储中运行集群时,iowait会提示存储读写(i/o过程)的瓶颈等待时间。超额订阅的存储框架会影响性能。
内存使用情况。监控内存可以显示出有多少内存在使用,以及有多少可用内存,可用内存可以是空闲内存,也可以是缓存。出现内存限制的系统会开始进行交换(swap),交换会迅速降低性能。
磁盘压力。如果系统正在运行诸如etcd或者任何数据存储这样的写入密集型服务时,如果磁盘空间耗尽,那将是灾难性的问题。不能写入数据会出现崩溃,而这种崩溃会转化为真实世界的损失。有了像LVM这样的技术,就能很容易地根据需要增加磁盘空间,但是尽管如此还是要监控它。
网络带宽。在当今千兆接口的时代,似乎带宽永远都不会耗尽。然而,仅仅是出现一些异常的服务、数据泄漏、系统损坏或者DOS***,就可能耗尽所有的带宽导致停机。如果了解自己的正常数据使用情况和应用程序的模式,就能有效降低成本,有助于规划容量。
Pod资源。如果能知道pod需要什么资源的话,Kubernetes调度器就能最大化发挥作用。它可以确保在可用的节点上放置pod。在设计网络时,为了避免剩余节点无法运行所有所需的资源的情况,需要预先考虑有多少节点可能会失败。使用云自动伸缩组之类的服务可以快速恢复,但要确保其余节点在失败节点恢复回来之前,能够处理增加的负载。
Kubernetes服务
组成Kubernetes Master或者Worker的所有组件(包括etcd)都对应用程序的健康运行至关重要。如果其中任何一个出现失败,监控系统就需要检测失败,修复它并且发送警告。
内部服务
最后一层是Kubernetes资源本身。Kubernetes公开了关于资源的度量,我们还可以直接监控应用程序。虽然Kubernetes会尽力维持理想的状态,但如果它无能为力的话,我们就需要一种由人类干预和解决问题的方法了。
用Rancher来监控
除了管理运行在任何提供者上、任何位置的Kubernetes集群外,Rancher还会监控这些集群中运行的资源,并在资源超过定义的阈值时发送警报。
现在已经有许多关于如何部署Rancher的教程。如果你还没有正在运行的集群,请先在这里暂停,进入我们的快速上手指南:https://rancher.com/quick-start/。等到集群正在运行了再返回到这里开始监控。
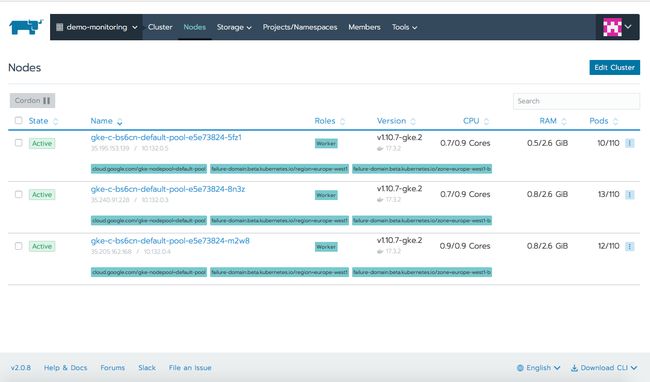
集群概述可以让你了解正在使用的资源和Kubernetes组件的状态。在我们的例子中,我们使用了78%的CPU、26%的RAM和11%的最大pod数量。

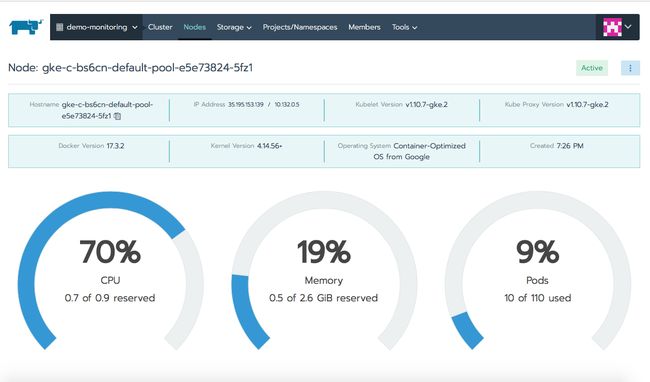
点击Nodes选项卡,你可以看到关于运行在集群上每个节点的附加信息,点击具体节点时,可以看到关于该成员的健康状况。
Workloads选项卡显示了运行在集群上的pods。如果你还没有任何运行的pod,先发布一个运行nginx镜像的工作负载,把它扩展成多个副本。
当需要选择工作负载名称时,Rancher会弹出一个显示有关该工作负载的信息页面。在页面顶部,它展示了每个pod所运行的节点,pod的IP地址以及它们的状态。点击任何一个pod会看到更多内容,现在我们看到了关于该pod的详细信息。右上角的汉堡菜单图标能让我们和pod交互,通过该图标,我们可以执行shell、查看日志或者删除pod。
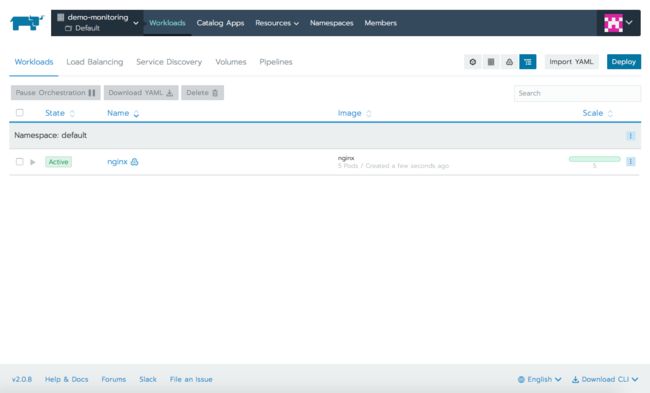
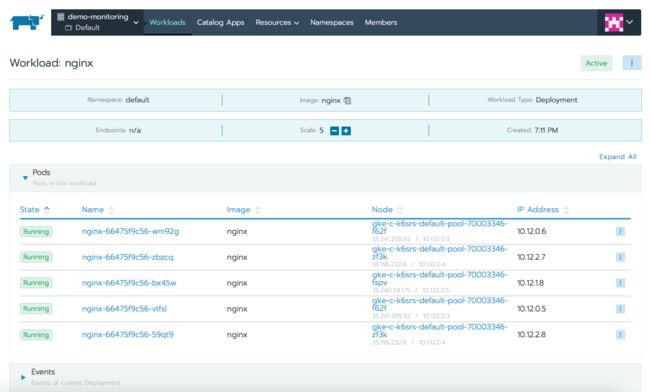
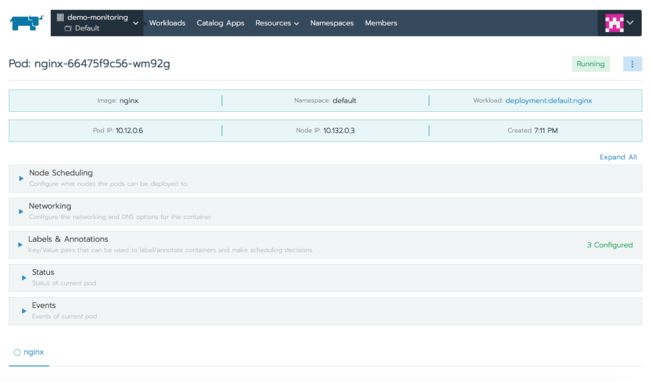
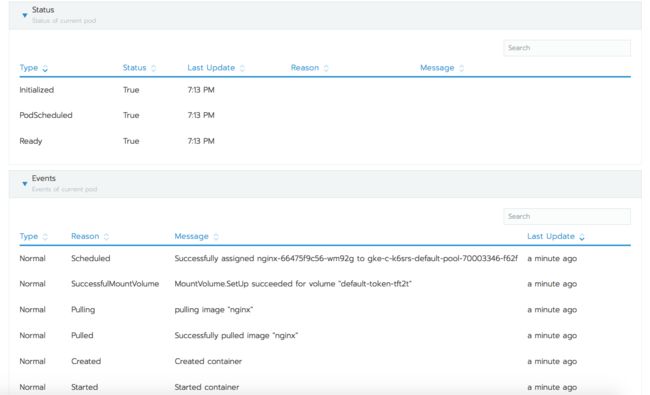
Other选项卡展示了不同Kubernetes资源的信息,包括ingress或LoadBalancer类型的服务的Load Balancing,其他服务类型的Service Discovery以及在集群中配置卷的Volumes。
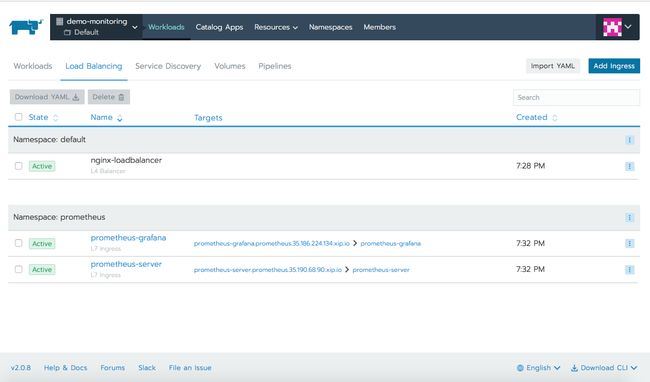
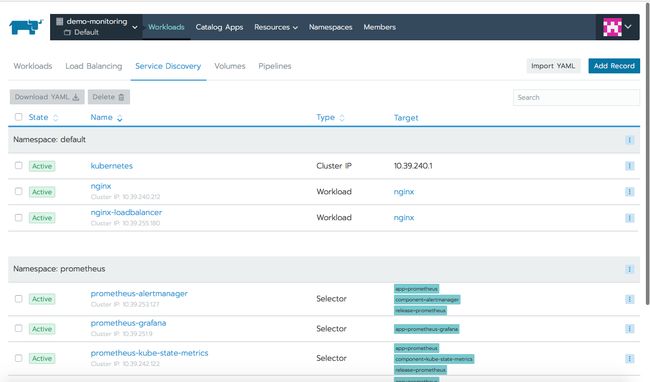
使用Prometheus监控
Rancher UI中可以看到的信息对故障排除非常有帮助,不过这并不是在集群生命周期的每一时刻积极追踪集群状态的最佳方法。我们将使用Prometheus,它是Kubernetes公司的一个兄弟项目,由Cloud Native Computing Foundation负责维护和运营。我们还将使用到Grafana工具,它能把时间序列数据转换成漂亮的图形和仪表板显示。
Prometheus是一个用来监控系统和生成警报的开源应用程序。从服务器到应用程序、数据库、甚至单个进程,它几乎可以监控任何东西。在Prometheus的词表中,它监控targets,目标的每个单位称为metric。检索关于目标信息的行为称为scraping(抓取)。Prometheus将在指定的时间间隔内采集目标,并把信息存储在时间序列数据库中。Prometheus拥有自己的脚本语言PromQL。
Grafana也是开源的,可以作为Web应用程序运行。虽然它经常和Prometheus一起使用,但也支持后端数据存储,如fluxDB、Graphite、Elasticsearch等等。Grafana可以很容易地创建图形,并且把它们合并称仪表板,而这些仪表板由一个强大的身份验证和授权层保护,它们还可以和其他仪表板进行共享而不需要访问服务器本身。Grafana在其对象定义中大量使用JSON,这样它的图形和仪表板都非常容易移植,并且版本控制非常方便。
在Rancher的应用程序目录中已经同时包含了Prometheus和Grafana,我们只需点击几下鼠标就能部署它们了。
安装Prometheus和Grafana
访问集群的Catalog Apps页面,搜索Prometheus。安装它的同时还会安装Grafana和AlertManager。对本文来说,所有内容都使用默认值就可以了,但如果考虑到生产部署,请阅读Detailed Descriptions下的信息,看看图表中有多少配置可供使用。
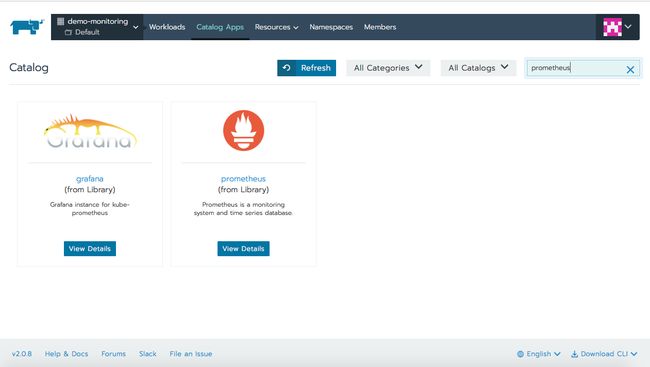
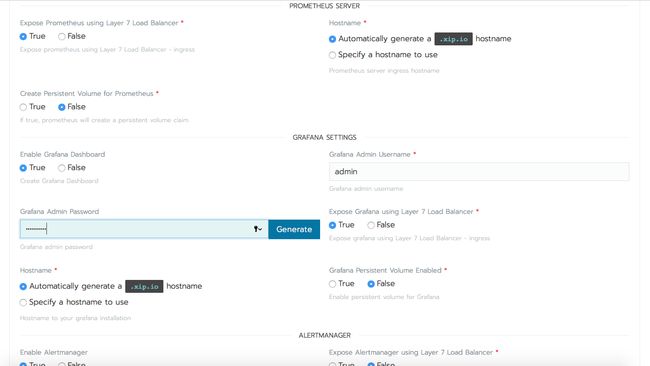
单击Launch,Rancher将把应用程序部署到集群中,几分钟之后,你就能看到prometheus命名空间下所有工作负载处于Active状态。
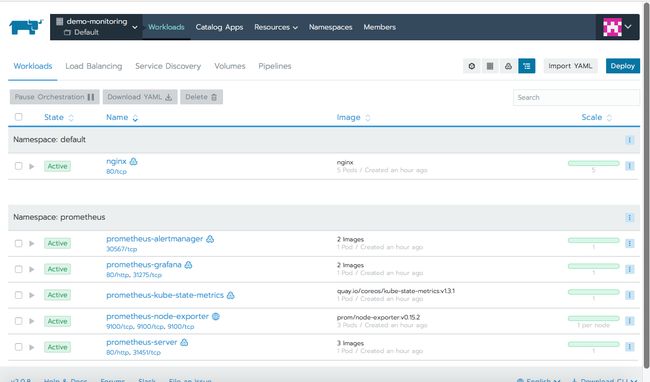
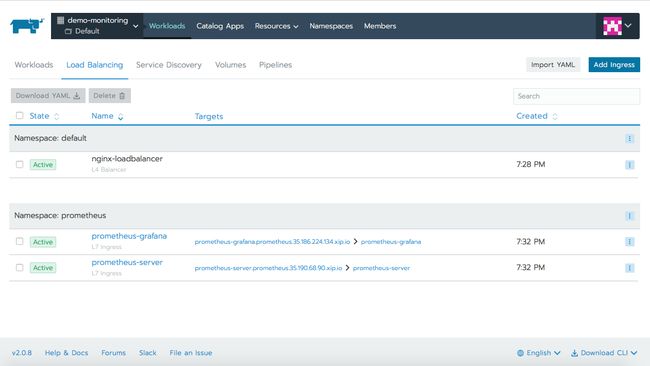
默认情况下使用了xip.io设置Layer7 ingress,我们可以在Load Balancing选项卡上看到它,单击链接打开Grafana仪表板。
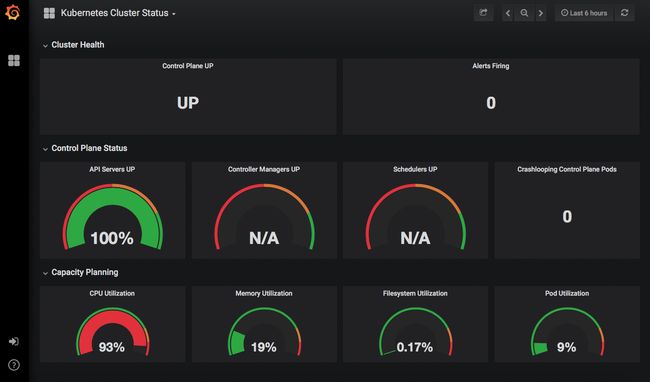
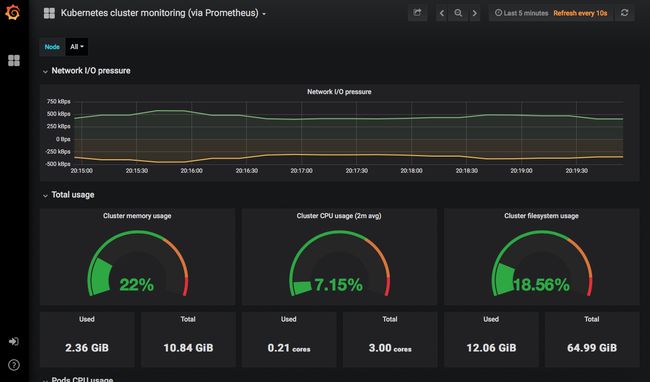
Prometheus的安装还在Grafana中部署了几个仪表板,因此我们可以马上看到关于集群的信息,查看它的性能。

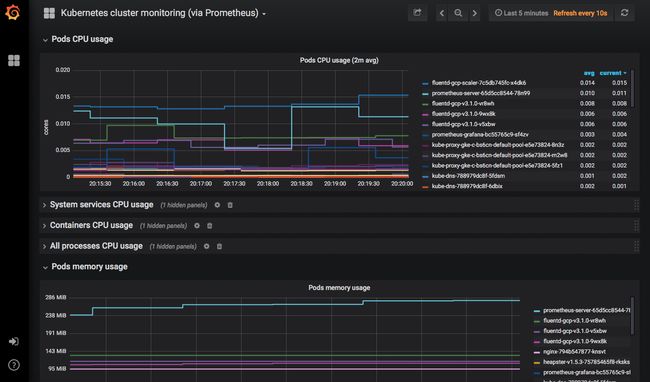

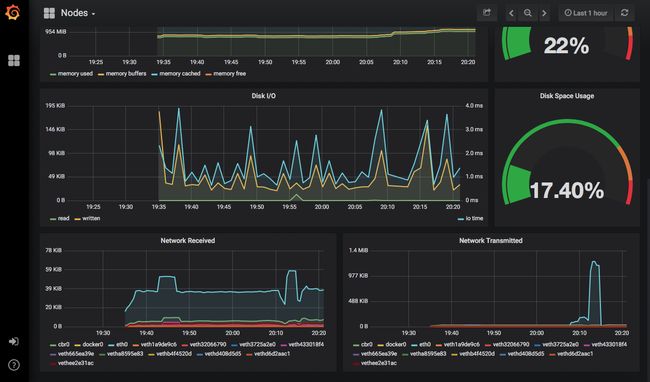
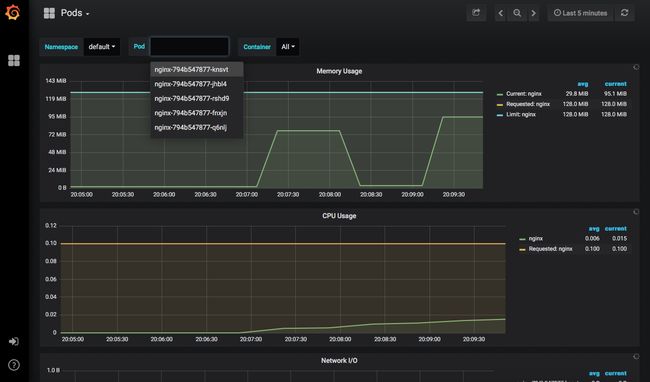
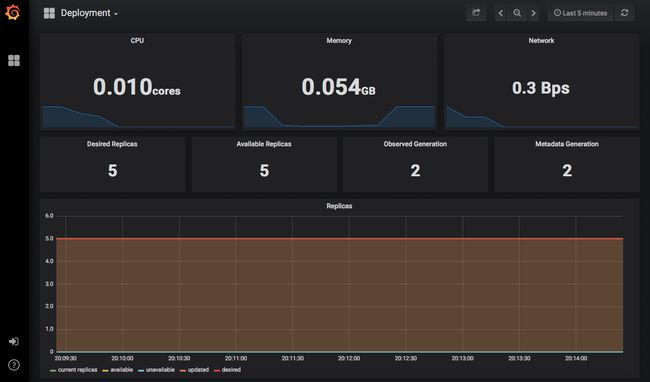
总 结
Kubernetes能尽可能保持应用程序的运行,但这并不说明我们就不需要了解应用程序运行的情况。当你开始使用Kubernetes工作时,还需要去部署监控系统,帮助你了解情况并作出决策。
Prometheus和Grafana将帮助你完成这一项工作,如果你使用了Rancher,那部署这两个应用程序只需要短短几分钟。而在即将发布的Rancher 2.2中,配备了完全集成的Prometheus和Grafana,增强所有Kubernetes集群的可见性,同时确保不同项目与用户之间的隔离。Rancher也因此成为唯一一个在多集群、多租户环境中支持Prometheus的解决方案。
使用Prometheus监控Rancher管理的Kubernetes环境,只需要两个步骤:
-
选择集群
- 一键启动监控
你可以在此了解如何更加简单快速地在多Kubernetes集群和多租户环境中使用Prometheus监控!