文 | 潘国庆 携程大数据平台实时计算平台负责人
 本文主要从携程大数据平台概况、架构设计及实现、在实现当中踩坑及填坑的过程、实时计算领域详细的应用场景,以及未来规划五个方面阐述携程实时计算平台架构与实践,希望对需要构建实时数据平台的公司和同学有所借鉴。
本文主要从携程大数据平台概况、架构设计及实现、在实现当中踩坑及填坑的过程、实时计算领域详细的应用场景,以及未来规划五个方面阐述携程实时计算平台架构与实践,希望对需要构建实时数据平台的公司和同学有所借鉴。
一、携程大数据平台之总体架构
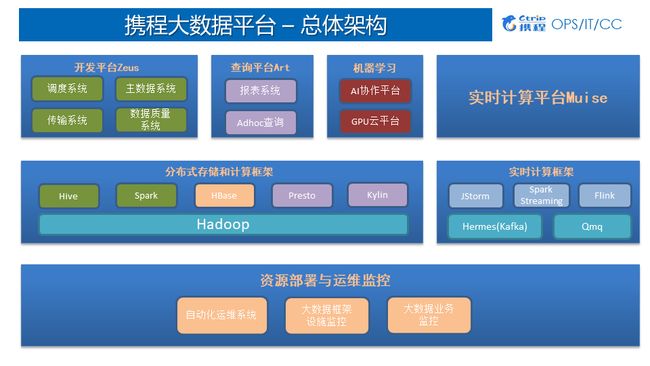
携程大数据平台结构分为三层:
应用层:开发平台Zeus(分为调度系统、Datax数据传输系统、主数据系统、数据质量系统)、查询平台(ArtNova报表系统、Adhoc查询)、机器学习(基于tensorflow、spark等开源框架进行开发;GPU云平台基于K8S实现)、实时计算平台Muise;
中间层:基于开源的大数据基础架构,分为分布式存储和计算框架、实时计算框架;
离线主要是基于Hadoop、HDFS分布式存储、分布式离线计算基于Hive及Spark、KV存储基于HBase、Presto和Kylin用于Adhoc以及报表系统;
实时计算框架底层是基于Kafka封装的消息队列系统Hermes, Qmq是携程自研的消息队列, Qmq主要用于定单交易系统,确保百分之百不丢失数据而打造的消息队列。
底层:资源监控与运维监控,分为自动化运维系统、大数据框架设施监控、大数据业务监控。
二、架构设计与实现
1.Muise平台介绍
1)Muise是什么
Muise,取自希腊神话的文艺女神缪斯之名,是携程的实时数据分析和处理的平台;Muise平台底层基于消息队列和开源的实时处理系统JStorm、Spark Streaming和Flink,能够支持秒级,甚至是毫秒级延迟的流式数据处理。
2)Muise的功能
数据源:Hermes Kafka/Mysql、Qmq;
数据处理:提供Muise JStorm/Spark/FlinkCore API消费Hermes或Qmq数据,底层使用Jstorm、Spark或实时处理数据,并提供自己封装的API给用户使用。API对接了所有数据源系统,方便用户直接使用;
作业管理:Portal提供对于JStorm、Spark Streaming和Flink作业的管理,包含新建作业,上传jar包以及发布生产等功能;
监控和告警:使用Jstorm、Spark和Flink提供的Metrics框架,支持自定义的metrics;metrics信息中心化管理,接入Ops的监控和告警系统,提供全面的监控和告警支持,帮助用户在第一时间内监控到作业是否发生问题。
2.Muise平台现状
平台现状:
Jstorm 2.1.1、Spark 2.0.1、Flink1.6.0、Kafka 2.0;
集群规模:
13个集群、200+台机器150+Jstorm、50+Yarn、100+ Kafka;
作业规模:
11个业务线、350+Jstorm作业、120+SS/Flink作业;
消息规模:
Topic 1300+、增量 100T+ PD、Avg 200K TPS、Max 900K TPS;
消息延时:
Hermes 200ms以内、Storm 20ms以内;
消息处理成功率:
99.99%。
3.Muise平台演进之路
2015 Q2~2015 Q3 :基于Storm开发实时计算平台;
2016 Q1~2016 Q2 :Storm迁移JStorm、引入StreamCQL;
2017 Q1~2017 Q2 :Spark Streaming调研与接入;
2017 Q3~2018 Q1 :Flink调研与接入。
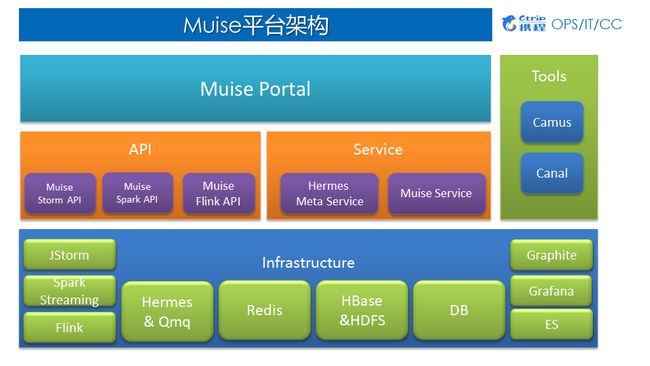
4.Muise平台架构
1)Muise平台架构
应用层:Muise Portal 目前主要支持了 Storm 与 Spark Streaming两类作业,支持新建作业、Jar包发布、作业运行与停止等一系列功能;
中间层:对底层Infrastructure做了封装,为用户提供基于Storm、Spark、Flink相对应的API以及各方面Services;
底层:Hermes & Qmq是数据源、Redis、HBase、HDFS、DB等作为外部的数据存储、Graphite、Grafana、ES主要用于监控。
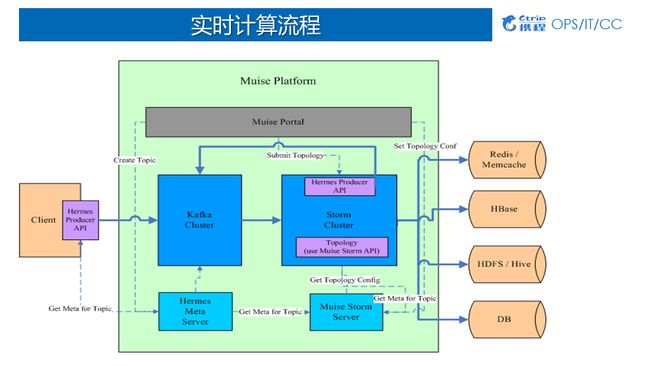
2)Muise实时计算流程
Producer端:用户先申请Kafka的topic,然后将数据实时写到Kafka中;
Muise Portal端:用户基于我们提供的API做开发,开发完以后通过Muise Portal配置、上传和启动作业;作业启动后,jar包会分发到各个对应的集群消费Kafka数据;
存储端:数据在被消费之后可以写回QMQ或Kafka,也可以存储到外部系统Redis、HBase、HDFS/Hive、DB。
5.平台设计 ——易用性
首先:作为一个平台设计第一要点就是要简单易用,我们提供综合的Portal,便于用户自己新建管理它的作业,方便开发实时作业第一时间能够上线;
其次:我们封装了很多Core API,支持多套实时计算框架:
支持HermesKafka/MySQL 、QMQ;
集成Jstorm、Spark Streaming、Flink;
作业资源管控;
提供DB、Redis、HBase和HDFS输出组件;
基于内置Metric系统定制多项metric进行作业预警监控;
用户可自定义Metric用于监控与预警;
支持AtLeast Once 与Exactly Once语义。
上文讲到平台设计要易用,下面讲平台的容错,确保数据一定不能出问题。
6.平台设计——容错
Jstorm:基于Acker机制确保At Least Once;
Spark Streaming:基于Checkpoint实现Exactly Once、基于Kafka Offset回溯实现At Least Once;
Flink:基于Flinktwo-phase commit + Kafka 0.11事务性支持实现Exactly Once。
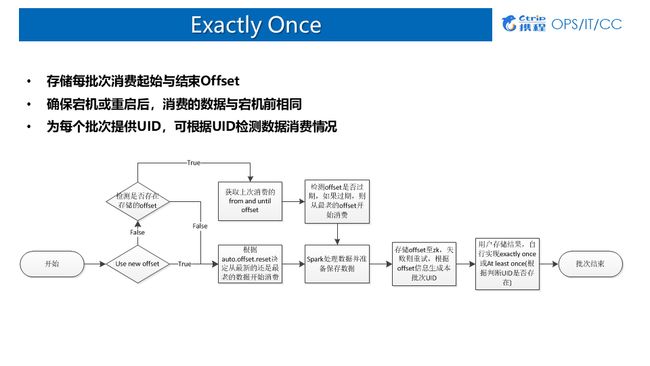
7.Exactly Once
1)Direct Approach
当前大部分拿Spark Streaming消费Kafka的话,都是用Direct Approach的方式:
优点:记录每个批次消费的Offset,作业可通过offset回溯;
缺点:数据存储与offset存储异步:
数据保存成功,应用宕机,offset未保存 (导致数据重复);
offset保存成功,应用宕机,数据保存失败 (导致数据丢失);
2)CheckPoint
优点:默认记录每个批次的运行状态与源数据,宕机时可从cp目录恢复;
缺点:
1. 非100%保证ExactlyOnce;
https://www.iteblog.com/archives/1795 描述了无法保证Exactly once的场景;
https://issues.apache.org/jira/browse/SPARK-17606 也存在doCheckPoint时出现块丢失的情况;
2. 启用cp带来额外性能影响;
3. Streaming作业逻辑改变无法从cp恢复。
适用场景:比较适合有状态计算的场景;
使用方式:建议程序自己存储offset,当发生宕机时,如果spark代码逻辑没有发生改变,则根据checkpoint目录创建StreamingContext。如果发生改变,则根据实现自己存储的offset创建context并设立新的checkpoint点。
8.平台设计——监控与告警
如何能够第一时间帮用户发现作业问题,是一个重中之重。
集群监控
服务器监控:考量的指标有Memory、CPU、Disk IO、Net IO;
平台监控:Ganglia;
作业监控
基于实时计算框架原生Metric系统;
定制Metrics反应作业状态;
采集原生与定制Metrics用于监控和告警;
存储:Graphite展 现:Grafana 告警:Appmon;
我们现在定制的很多Metrics当中比较通用的是:
Fail:定期时间内,Jstorm数据处理失败数量、Spark task Fail数量;
Ack:定期时间内,处理的数据量;
Lag:定期时间内,数据产生与被消费的中间延迟(kafka 2.0基于自带bornTime)。
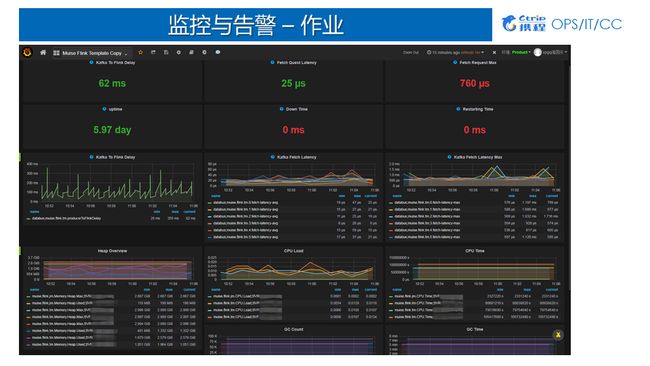
携程开发了自己告警系统,将Metrics代入系统之后基于规则做告警。通过作业监控看板完成相关指标的监控和查看,我们会把Flink作为比较关心的Metrics指标,全都导入到Graphite数据库里面,然后基于前端Grafana做展现。通过作业监控看板,我们能够直接看到Kafka to Flink Delay(Lag),相当于数据从产生到被Flink作业消费,中间延迟是62毫秒,速度相对比较快的。其次我们监控了每次从Kafka中获取数据的速度。因为从Kafka获取数据是基于一小块一小块去获取,我们设置的是每次拉2兆的数据量。通过作业监控看板可以监控到每次从Kafka拉取数据时候的平均延迟是25毫秒,Max是 760毫秒。
接下来讲讲我们在这几年踩到的一些坑以及如何填坑的。
三、踩坑与填坑
坑1:HermesUBT数据量大,埋点信息众多,服务端与客户端均承受巨大压力;
解决方案:提供统一分流作业,基于特定规则与配置将数据分流至不同topic。
坑2:Kafka无法保证全局有序;
解决方案:如果在强制全局有序的场景下,使用单Partition;如果在部分有序的情况下,可基于某个字段作Hash,保证Partition内部有序。
坑3:Kafka无法根据时间精确回溯到某时间段的数据;
解决方案:平台提供过滤功能,过滤时间早于设定时间的数据(kafka 0.10之后每条数据都带有自己的时间戳,所以这个问题在升级kafka之后自然而然的就解决了)。
坑4:最初,携程所有的Spark Streaming、Flink作业都是跑在主机群上面的,是一个大Hadoop集群,目前是几千台规模,离线和实时是混布的,一旦一个大的离线作业上来时,会对实时作业有影响;其次是Hadoop集群经常会做一些升级改造,所以可能会重启Name Node或者Node Manager,这会导致作业有时会挂掉;
解决方案:我们采用分开部署,单独搭建实时集群,独立运行实时作业。离线归离线,实时归实时的,实时集群单独跑Spark Streaming跟Yarn的作业,离线专门跑离线的作业。
当分开部署后,会遇到新的问题,部分实时作业需要去一些离线作业做一些Join或 Feature的操作,所以也是需要访问主机群数据。这相当于有一个跨集群访问的问题。
坑5:Hadoop实时集群跨集群访问主机群;
解决方案:Hdfs-site.xml配置ns-prod、ns双重namespace,分别指向本地与主机群;
Spark配置spark.yarn.access.namenodes or hadoopFlieSystems
坑6:无论是Jstorm还是接Storm都会遇到一个CPU抢占的问题,当你上了一个大的作业,尤其是那种消耗CPU特别厉害的,可能我给它分开了一个Worker,一个CPU Core,但是它最后有可能会给我用到3个甚至4个;
解决方案:启用cgroup限制cpu使用率。
四、应用场景
1.实时报表统计
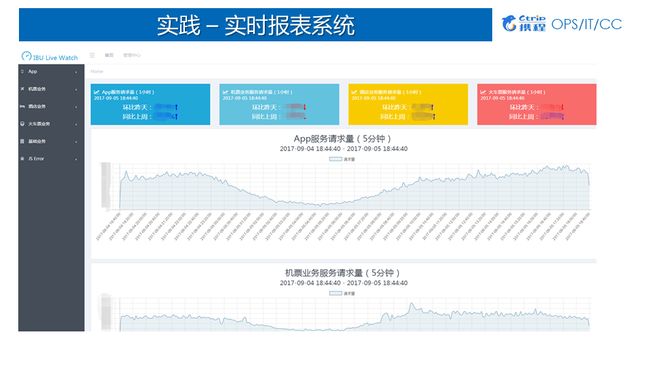
实时报表统计与展现也是Spark Streaming使用较多的一个场景,数据可以基于Process Time统计,也可以基于Event Time统计。由于本身Spark Streaming不同批次的job可以视为一个个的滚动窗口,某个独立的窗口中包含了多个时间段的数据,这使得使用SparkStreaming基于Event Time统计时存在一定的限制。一般较为常用的方式是统计每个批次中不同时间维度的累积值并导入到外部系统,如ES;然后在报表展现的时基于时间做二次聚合获得完整的累加值最终求得聚合值。下图展示了携程IBU基于Spark Streaming实现的实时看板。
2.实时数仓
1)Spark Streaming近实时存储数据
如今市面上有形形×××的工具可以从Kafka实时消费数据并进行过滤清洗最终落地到对应的存储系统,如:Camus、Flume等。相比较于此类产品,Spark Streaming的优势首先在于可以支持更为复杂的处理逻辑,其次基于Yarn系统的资源调度使得Spark Streaming的资源配置更加灵活,用户采用Spark Streaming实时把数据写到HDFS或者写到Hive里面去。
2)基于各种规则作数据质量检测
基于Spark Streaming,自定义metric功能对数据的数据量、字段数、数据格式与重复数据进行了数据质量校验与监控。
3)基于自定义metric实时预警
基于我们封装提供的Metric注册系统确定一些规则,然后每个批次基于这些规则做一个校验,返回一个结果。这个结果会基于Metric sink吐出来,吐出来基于metrics的结果做一个监控。当前我们采用Flink加载TensorFlow模型实时做预测。基本时效性是数据一旦到达两秒钟之内就能够把告警信息告出来,给用户非常好的体验。

五、未来规划
1.Flink on K8S
在携程内部有一些不同的计算框架,有实时计算的,有机器学习的,还有离线计算的,所以需要一个统一的底层框架来进行管理,因此在未来将Flink迁移到了K8S上,进行统一的资源管控。
2.Muise平台接入Flink SQL
Muise平台虽然接入了Flink,但是用户还是得手写代码,我们开发了一个实时特征平台,用户只需要写SQL,即基于Flink的SQL就可以实时采集用户所需要的模型里面或者用到的特征。之后会把实时特征平台跟实时计算平台做进行合并,用户最后只需要写SQL就可以实现所有的实时作业实现。
3.Jstorm全面启用Cgroup
当前由于部分历史原因导致现在很多作业跑在Jstorm上面,因此出现了资源分配不均衡的情况,之后会全面启用Cgroup。
4.在线模型训练
携程部分部门需要实时在线模型训练,通过用Spark训练了模型之后,然后使用Spark Streaming的模型,实时做一个拦截或者控制,应用在风控等场景。
—end—