序言
第1章 Scrapy介绍
第2章 理解HTML和XPath
第3章 爬虫基础
第4章 从Scrapy到移动应用
第5章 快速构建爬虫
第6章 Scrapinghub部署
第7章 配置和管理
第8章 Scrapy编程
第9章 使用Pipeline
第10章 理解Scrapy的性能
第11章(完) Scrapyd分布式抓取和实时分析
本章非常重要,你可能需要读几遍,或是从中查找解决问题的方法。我们会从如何安装Scrapy讲起,然后在案例中讲解如何编写爬虫。开始之前,说几个注意事项。
因为我们马上要进入有趣的编程部分,使用本书中的代码段会十分重要。当你看到:
$ echo hello world
hello world
是要让你在终端中输入echo hello world(忽略$),第二行是看到结果。
当你看到:
>>> print 'hi'
hi
是让你在Python或Scrapy界面进行输入(忽略>>>)。同样的,第二行是输出结果。
你还需要对文件进行编辑。编辑工具取决于你的电脑环境。如果你使用Vagrant(强烈推荐),你可以是用Notepad、Notepad++、Sublime Text、TextMate,Eclipse、或PyCharm等文本编辑器。如果你更熟悉Linux/Unix,你可以用控制台自带的vim或emacs。这两个编辑器功能强大,但是有一定的学习曲线。如果你是初学者,可以选择适合初学者的nano编辑器。
安装Scrapy
Scrapy的安装相对简单,但这还取决于读者的电脑环境。为了支持更多的人,本书安装和使用Scrapy的方法是用Vagrant,它可以让你在Linux盒中使用所有的工具,而无关于操作系统。下面提供了Vagrant和一些常见操作系统的指导。
MacOS
为了轻松跟随本书学习,请参照后面的Vagrant说明。如果你想在MacOS中安装Scrapy,只需控制台中输入:
$ easy_install scrapy
然后,所有事就可以交给电脑了。安装过程中,可能会向你询问密码或是否安装Xcode,只需同意即可。
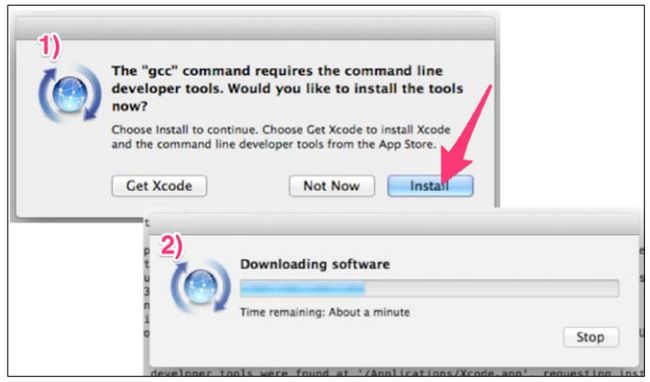
Windows
在Windows中安装Scrapy要麻烦些。另外,在Windows安装本书中所有的软件也很麻烦。我们都为你想到了可能的问题。有Virtualbox的Vagrant可以在所有64位电脑上顺利运行。翻阅相关章节,只需几分钟就可以安装好。如果真要在Windows中安装,请参考本书网站http://scrapybook.com/上面的资料。
Linux
你可能会在多种Linux服务器上安装Scrapy,步骤如下:
提示:确切的安装依赖变化很快。写作本书时,Scrapy的版本是1.0.3(翻译此书时是1.4)。下面只是对不同服务器的建议方法。
Ubuntu或Debian Linux
为了在Ubuntu(测试机是Ubuntu 14.04 Trusty Tahr - 64 bit)或是其它使用apt的服务器上安装Scrapy,可以使用下面三条命令:
$ sudo apt-get update
$ sudo apt-get install python-pip python-lxml python-crypto python-
cssselect python-openssl python-w3lib python-twisted python-dev libxml2-
dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
$ sudo pip install scrapy
这个方法需要进行编译,可能随时中断,但可以安装PyPI上最新版本的Scrapy。如果想避开编译,安装不是最新版本的话,可以搜索“install Scrapy Ubuntu packages”,按照官方文档安装。
Red Hat或CentOS Linux
在使用yum的Linux上安装Scrapy也很简单(测试机是Ubuntu 14.04 Trusty Tahr - 64 bit)。只需三条命令:
sudo yum update
sudo yum -y install libxslt-devel pyOpenSSL python-lxml python-devel gcc
sudo easy_install scrapy
从GitHub安装
按照前面的指导,就可以安装好Scrapy的依赖了。Scrapy是纯Python写成的,如果你想编辑源代码或是测试最新版,可以从https://github.com/scrapy/scrapy克隆最新版,只需命令行输入:
$ git clonehttps://github.com/scrapy/scrapy.git
$ cd scrapy
$ python setup.py install
我猜如果你是这类用户,就不需要我提醒安装virtualenv了。
升级Scrapy
Scrapy升级相当频繁。如果你需要升级Scrapy,可以使用pip、easy_install或aptitude:
$ sudo pip install --upgrade Scrapy
或
$ sudo easy_install --upgrade scrapy
如果你想降级或安装指定版本的Scrapy,可以:
$ sudo pip install Scrapy==1.0.0
或
$ sudo easy_install scrapy==1.0.0
Vagrant:本书案例的运行方法
本书有的例子比较复杂,有的例子使用了许多东西。无论你是什么水平,都可以尝试运行所有例子。只需一句命令,就可以用Vagrant搭建操作环境。

在Vagrant中,你的电脑被称作“主机”。Vagrant在主机中创建一个虚拟机。这样就可以让我们忽略主机的软硬件,来运行案例了。
本书大多数章节使用了两个服务——开发机和网络机。我们在开发机中登录运行Scrapy,在网络机中进行抓取。后面的章节会使用更多的服务,包括数据库和大数据处理引擎。
根据附录A安装必备,安装Vagrant,直到安装好git和Vagrant。打开命令行,输入以下命令获取本书的代码:
$ git clone https://github.com/scalingexcellence/scrapybook.git
$ cd scrapybook
打开Vagrant:
$ vagrant up --no-parallel
第一次打开Vagrant会需要些时间,这取决于你的网络。第二次打开就会比较快。打开之后,登录你的虚拟机,通过:
$ vagrant ssh
代码已经从主机中复制到了开发机,现在可以在book的目录中看到:
$ cd book
$ ls
$ ch03 ch04 ch05 ch07 ch08 ch09 ch10 ch11 ...
可以打开几个窗口输入vagrant ssh,这样就可以打开几个终端。输入vagrant halt可以关闭系统,vagrantstatus可以检查状态。vagrant halt不能关闭虚拟机。如果在VirtualBox中碰到问题,可以手动关闭,或是使用vagrant global-status查找id,用vagrant halt
安装好环境之后,就可以开始学习Scrapy了。
UR2IM——基础抓取过程
每个网站都是不同的,对每个网站进行额外的研究不可避免,碰到特别生僻的问题,也许还要用Scrapy的邮件列表咨询。寻求解答,去哪里找、怎么找,前提是要熟悉整个过程和相关术语。Scrapy的基本过程,可以写成字母缩略语UR2IM,见下图。
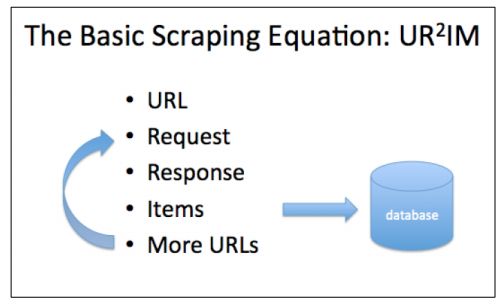
The URL
一切都从URL开始。你需要目标网站的URL。我的例子是https://www.gumtree.com/,Gumtree分类网站。
例如,访问伦敦房地产首页http://www.gumtree.com/flats-houses/london,你就可以找到许多房子的URL。右键复制链接地址,就可以复制URL。其中一个URL可能是这样的:https://www.gumtree.com/p/studios-bedsits-rent/split-level。但是,Gumtree的网站变动之后,URL的XPath表达式会失效。不添加用户头的话,Gumtree也不会响应。这个留给以后再说,现在如果你想加载一个网页,你可以使用Scrapy终端,如下所示:
scrapy shell -s USER_AGENT="Mozilla/5.0"
要进行调试,可以在Scrapy语句后面添加 –pdb,例如:
scrapy shell --pdb https://gumtree.com
我们不想让大家如此频繁的点击Gumtree网站,并且Gumtree网站上URL失效很快,不适合做例子。我们还希望大家能在离线的情况下,多多练习书中的例子。这就是为什么Vagrant开发环境内嵌了一个网络服务器,可以生成和Gumtree类似的网页。这些网页可能并不好看,但是从爬虫开发者的角度,是完全合格的。如果想在Vagrant上访问Gumtree,可以在Vagrant开发机上访问http://web:9312/,或是在浏览器中访问http://localhost:9312/。
让我们在这个网页上尝试一下Scrapy,在Vagrant开发机上输入:
$ scrapy shell http://web:9312/properties/property_000000.html
...
[s] Available Scrapy objects:
[s] crawler
[s] item {}
[s] request
[s] response <200 http://web:9312/.../property_000000.html>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local...
[s] view(response) View response in a browser
>>>
得到一些输出,加载页面之后,就进入了Python(可以使用Ctrl+D退出)。
请求和响应
在前面的输出日志中,Scrapy自动为我们做了一些工作。我们输入了一条地址,Scrapy做了一个GET请求,并得到一个成功响应值200。这说明网页信息已经成功加载,并可以使用了。如果要打印reponse.body的前50个字母,我们可以得到:
>>> response.body[:50]
'\n\n\n这就是这个Gumtree网页的HTML文档。有时请求和响应会很复杂,第5章会对其进行讲解,现在只讲最简单的情况。
抓取对象
下一步是从响应文件中提取信息,输入到Item。因为这是个HTML文档,我们用XPath来做。首先来看一下这个网页:

页面上的信息很多,但大多是关于版面的:logo、搜索框、按钮等等。从抓取的角度,它们不重要。我们关注的是,例如,列表的标题、地址、电话。它们都对应着HTML里的元素,我们要在HTML中定位,用上一章所学的提取出来。先从标题开始。
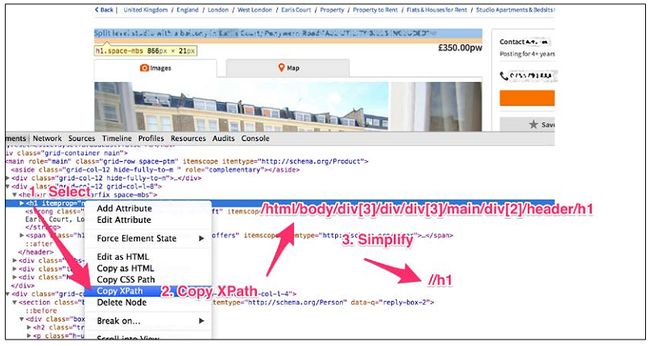
在标题上右键点击,选择检查元素。在自动定位的HTML上再次右键点击,选择复制XPath。Chrome给的XPath总是很复杂,并且容易失效。我们要对其进行简化。我们只取最后面的h1。这是因为从SEO的角度,每页HTML只有一个h1最好,事实上大多是网页只有一个h1,所以不用担心重复。
提示:SEO是搜索引擎优化的意思:通过对网页代码、内容、链接的优化,提升对搜索引擎的支持。
让我们看看h1标签行不行:
>>> response.xpath('//h1/text()').extract()
[u'set unique family well']
很好,完全行得通。我在h1后面加上了text(),表示只提取h1标签里的文字。没有添加text()的话,就会这样:
>>> response.xpath('//h1').extract()
[u'set unique family well
']
我们已经成功得到了title,但是再仔细看看,还能发现更简便的方法。
Gumtree为标签添加了属性,就是itemprop=name。所以XPath可以简化为//*[@itemprop="name"][1]/text()。在XPath中,切记数组是从1开始的,所以这里[]里面是1。
选择itemprop="name"这个属性,是因为Gumtree用这个属性命名了许多其他的内容,比如“You may also like”,用数组序号提取会很方便。
接下来看价格。价格在HTML中的位置如下:
£334.39pw
我们又看到了itemprop="name"这个属性,XPath表达式为//*[@itemprop="price"][1]/text()。验证一下:
>>> response.xpath('//*[@itemprop="price"][1]/text()').extract()
[u'\xa3334.39pw']
注意Unicode字符(£符号)和价格350.00pw。这说明要对数据进行清理。在这个例子中,我们用正则表达式提取数字和小数点。使用正则方法如下:
>>> response.xpath('//*[@itemprop="price"][1]/text()').re('[.0-9]+')
[u'334.39']
提取房屋描述的文字、房屋的地址也很类似,如下:
//*[@itemprop="description"][1]/text()
//*[@itemtype="http://schema.org/Place"][1]/text()
相似的,抓取图片可以用//img[@itemprop="image"][1]/@src。注意这里没使用text(),因为我们只想要图片的URL。
假如这就是我们要提取的所有信息,整理如下:
| 目标 | XPath表达式 |
|---|---|
| title | //*[@itemprop="name"][1]/text() Example value: [u'set unique family well'] |
| Price | //*[@itemprop="price"][1]/text() Example value (using re()):[u'334.39'] |
| description | //*[@itemprop="description"][1]/text() Example value: [u'website court warehouse\r\npool...'] |
| Address | //*[@itemtype="http://schema.org/Place"][1]/text() Example value: [u'Angel, London'] |
| Image_URL | //*[@itemprop="image"][1]/@src Example value: [u'../images/i01.jpg'] |
这张表很重要,因为也许只要稍加改变表达式,就可以抓取其他页面。另外,如果要爬取数十个网站时,使用这样的表可以进行区分。
目前为止,使用的还只是HTML和XPath,接下来用Python来做一个项目。
一个Scrapy项目
目前为止,我们只是在Scrapy shell中进行操作。学过前面的知识,现在开始一个Scrapy项目,Ctrl+D退出Scrapy shell。Scrapy shell只是操作网页、XPath表达式和Scrapy对象的工具,不要在上面浪费太多,因为只要一退出,写过的代码就会消失。我们创建一个名字是properties的项目:
$ scrapy startproject properties
$ cd properties
$ tree
.
├── properties
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
2 directories, 6 files
先看看这个Scrapy项目的文件目录。文件夹内包含一个同名的文件夹,里面有三个文件items.py, pipelines.py, 和settings.py。还有一个子文件夹spiders,里面现在是空的。后面的章节会详谈settings、pipelines和scrapy.cfg文件。
定义items
用编辑器打开items.py。里面已经有代码,我们要对其修改下。用之前的表里的内容重新定义class PropertiesItem。
还要添加些后面会用到的内容。后面会深入讲解。这里要注意的是,声明一个字段,并不要求一定要填充。所以放心添加你认为需要的字段,后面还可以修改。
| 字段 | Python表达式 |
|---|---|
| images | pipeline根据image_URL会自动填充这里。后面详解。 |
| Location | 地理编码会填充这里。后面详解。 |
我们还会加入一些杂务字段,也许和现在的项目关系不大,但是我个人很感兴趣,以后或许能用到。你可以选择添加或不添加。观察一下这些项目,你就会明白,这些项目是怎么帮助我找到何地(server,url),何时(date),还有(爬虫)如何进行抓取的。它们可以帮助我取消项目,制定新的重复抓取,或忽略爬虫的错误。这里看不明白不要紧,后面会细讲。
| 杂务字段 | Python表达式 |
|---|---|
| url | response.url Example value: ‘http://web.../property_000000.html' |
| project | self.settings.get('BOT_NAME') Example value: 'properties' |
| spider | self.name Example value: 'basic' |
| server | server socket.gethostname() Example value: 'scrapyserver1' |
| date | datetime.datetime.now() Example value: datetime.datetime(2015, 6, 25...) |
利用这个表修改PropertiesItem这个类。修改文件properties/items.py如下:
from scrapy.item import Item, Field
class PropertiesItem(Item):
# Primary fields
title = Field()
price = Field()
description = Field()
address = Field()
image_URL = Field()
# Calculated fields
images = Field()
location = Field()
# Housekeeping fields
url = Field()
project = Field()
spider = Field()
server = Field()
date = Field()
这是我们的第一段代码,要注意Python中是使用空格缩进的。每个字段名之前都有四个空格或是一个tab。如果一行有四个空格,另一行有三个空格,就会报语法错误。如果一行是四个空格,另一行是一个tab,也会报错。空格符指定了这些项目是在PropertiesItem下面的。其他语言有的用花括号{},有的用begin – end,Python则使用空格。
编写爬虫
已经完成了一半。现在来写爬虫。一般的,每个网站,或一个大网站的一部分,只有一个爬虫。爬虫代码来成UR2IM流程。
当然,你可以用文本编辑器一句一句写爬虫,但更便捷的方法是用scrapy genspider命令,如下所示:
$ scrapy genspider basic web
使用模块中的模板“basic”创建了一个爬虫“basic”:
properties.spiders.basic
一个爬虫文件basic.py就出现在目录properties/spiders中。刚才的命令是,生成一个名字是basic的默认文件,它的限制是在web上爬取URL。我们可以取消这个限制。这个爬虫使用的是basic这个模板。你可以用scrapy genspider –l查看所有的模板,然后用参数–t利用模板生成想要的爬虫,后面会介绍一个例子。
查看properties/spiders/basic.py file文件, 它的代码如下:
import scrapy
class BasicSpider(scrapy.Spider):
name = "basic"
allowed_domains = ["web"]
start_URL = (
'http://www.web/',
)
def parse(self, response):
pass
import命令可以让我们使用Scrapy框架。然后定义了一个类BasicSpider,继承自scrapy.Spider。继承的意思是,虽然我们没写任何代码,这个类已经继承了Scrapy框架中的类Spider的许多特性。这允许我们只需写几行代码,就可以有一个功能完整的爬虫。然后我们看到了一些爬虫的参数,比如名字和抓取域字段名。最后,我们定义了一个空函数parse(),它有两个参数self和response。通过self,可以使用爬虫一些有趣的功能。response看起来很熟悉,它就是我们在Scrapy shell中见到的响应。
下面来开始编辑这个爬虫。start_URL更改为在Scrapy命令行中使用过的URL。然后用爬虫事先准备的log()方法输出内容。修改后的properties/spiders/basic.py文件为:
import scrapy
class BasicSpider(scrapy.Spider):
name = "basic"
allowed_domains = ["web"]
start_URL = (
'http://web:9312/properties/property_000000.html',
)
def parse(self, response):
self.log("title: %s" % response.xpath(
'//*[@itemprop="name"][1]/text()').extract())
self.log("price: %s" % response.xpath(
'//*[@itemprop="price"][1]/text()').re('[.0-9]+'))
self.log("description: %s" % response.xpath(
'//*[@itemprop="description"][1]/text()').extract())
self.log("address: %s" % response.xpath(
'//*[@itemtype="http://schema.org/'
'Place"][1]/text()').extract())
self.log("image_URL: %s" % response.xpath(
'//*[@itemprop="image"][1]/@src').extract())
总算到了运行爬虫的时间!让爬虫运行的命令是scrapy crawl接上爬虫的名字:
$ scrapy crawl basic
INFO: Scrapy 1.0.3 started (bot: properties)
...
INFO: Spider opened
DEBUG: Crawled (200)
DEBUG: title: [u'set unique family well']
DEBUG: price: [u'334.39']
DEBUG: description: [u'website...']
DEBUG: address: [u'Angel, London']
DEBUG: image_URL: [u'../images/i01.jpg']
INFO: Closing spider (finished)
...
成功了!不要被这么多行的命令吓到,后面我们再仔细说明。现在,我们可以看到使用这个简单的爬虫,所有的数据都用XPath得到了。
来看另一个命令,scrapy parse。它可以让我们选择最合适的爬虫来解析URL。用—spider命令可以设定爬虫:
$ scrapy parse --spider=basic http://web:9312/properties/property_000001.html
你可以看到输出的结果和前面的很像,但却是关于另一个房产的。
填充一个项目
接下来稍稍修改一下前面的代码。你会看到,尽管改动很小,却可以解锁许多新的功能。
首先,引入类PropertiesItem。它位于properties目录中的item.py文件,因此在模块properties.items中。它的导入命令是:
from properties.items import PropertiesItem
然后我们要实例化,并进行返回。这很简单。在parse()方法中,我们加入声明item = PropertiesItem(),它产生了一个新项目,然后为它分配表达式:
item['title'] = response.xpath('//*[@itemprop="name"][1]/text()').extract()
最后,我们用return item返回项目。更新后的properties/spiders/basic.py文件如下:
import scrapy
from properties.items import PropertiesItem
class BasicSpider(scrapy.Spider):
name = "basic"
allowed_domains = ["web"]
start_URL = (
'http://web:9312/properties/property_000000.html',
)
def parse(self, response):
item = PropertiesItem()
item['title'] = response.xpath(
'//*[@itemprop="name"][1]/text()').extract()
item['price'] = response.xpath(
'//*[@itemprop="price"][1]/text()').re('[.0-9]+')
item['description'] = response.xpath(
'//*[@itemprop="description"][1]/text()').extract()
item['address'] = response.xpath(
'//*[@itemtype="http://schema.org/'
'Place"][1]/text()').extract()
item['image_URL'] = response.xpath(
'//*[@itemprop="image"][1]/@src').extract()
return item
现在如果再次运行爬虫,你会注意到一个不大但很重要的改动。被抓取的值不再打印出来,没有“DEBUG:被抓取的值”了。你会看到:
DEBUG: Scraped from <200
http://...000.html>
{'address': [u'Angel, London'],
'description': [u'website ... offered'],
'image_URL': [u'../images/i01.jpg'],
'price': [u'334.39'],
'title': [u'set unique family well']}
这是从这个页面抓取的PropertiesItem。这很好,因为Scrapy就是围绕Items的概念构建的,这意味着我们可以用pipelines填充丰富项目,或是用“Feed export”导出保存到不同的格式和位置。
保存到文件
试运行下面:
$ scrapy crawl basic -o items.json
$ cat items.json
[{"price": ["334.39"], "address": ["Angel, London"], "description":
["website court ... offered"], "image_URL": ["../images/i01.jpg"],
"title": ["set unique family well"]}]
$ scrapy crawl basic -o items.jl
$ cat items.jl
{"price": ["334.39"], "address": ["Angel, London"], "description":
["website court ... offered"], "image_URL": ["../images/i01.jpg"],
"title": ["set unique family well"]}
$ scrapy crawl basic -o items.csv
$ cat items.csv
description,title,url,price,spider,image_URL...
"...offered",set unique family well,,334.39,,../images/i01.jpg
$ scrapy crawl basic -o items.xml
$ cat items.xml
334.39 不用我们写任何代码,我们就可以用这些格式进行存储。Scrapy可以自动识别输出文件的后缀名,并进行输出。这段代码中涵盖了一些常用的格式。CSV和XML文件很流行,因为可以被Excel直接打开。JSON文件很流行是因为它的开放性和与JavaScript的密切关系。JSON和JSON Line格式的区别是.json文件是在一个大数组中存储JSON对象。这意味着如果你有一个1GB的文件,你可能必须现在内存中存储,然后才能传给解析器。相对的,.jl文件每行都有一个JSON对象,所以读取效率更高。
不在文件系统中存储生成的文件也很麻烦。利用下面例子的代码,你可以让Scrapy自动上传文件到FTP或亚马逊的S3 bucket。
$ scrapy crawl basic -o "ftp://user:[email protected]/items.json "
$ scrapy crawl basic -o "s3://aws_key:aws_secret@scrapybook/items.json"
注意,证书和URL必须按照主机和S3更新,才能顺利运行。
另一个要注意的是,如果你现在使用scrapy parse,它会向你显示被抓取的项目和抓取中新的请求:
$ scrapy parse --spider=basic http://web:9312/properties/property_000001.html
INFO: Scrapy 1.0.3 started (bot: properties)
...
INFO: Spider closed (finished)
>>> STATUS DEPTH LEVEL 1 <<<
# Scraped Items ------------------------------------------------
[{'address': [u'Plaistow, London'],
'description': [u'features'],
'image_URL': [u'../images/i02.jpg'],
'price': [u'388.03'],
'title': [u'belsize marylebone...deal']}]
# Requests ------------------------------------------------
[]
当出现意外结果时,scrapy parse可以帮你进行debug,你会更感叹它的强大。
清洗——项目加载器和杂务字段
恭喜你,你已经创建成功一个简单爬虫了!让我们让它看起来更专业些。
我们使用一个功能类,ItemLoader,以取代看起来杂乱的extract()和xpath()。我们的parse()进行如下变化:
def parse(self, response):
l = ItemLoader(item=PropertiesItem(), response=response)
l.add_xpath('title', '//*[@itemprop="name"][1]/text()')
l.add_xpath('price', './/*[@itemprop="price"]'
'[1]/text()', re='[,.0-9]+')
l.add_xpath('description', '//*[@itemprop="description"]'
'[1]/text()')
l.add_xpath('address', '//*[@itemtype='
'"http://schema.org/Place"][1]/text()')
l.add_xpath('image_URL', '//*[@itemprop="image"][1]/@src')
return l.load_item()
是不是看起来好多了?事实上,它可不是看起来漂亮那么简单。它指出了我们现在要干什么,并且后面的加载项很清晰。这提高了代码的可维护性和自文档化。(自文档化,self-documenting,是说代码的可读性高,可以像文档文件一样阅读)
ItemLoaders提供了许多有趣的方式整合数据、格式化数据、清理数据。它的更新很快,查阅文档可以更好的使用它,http://doc.scrapy.org/en/latest/topics/loaders。通过不同的类处理器,ItemLoaders从XPath/CSS表达式传参。处理器函数快速小巧。举一个Join()的例子。//p表达式会选取所有段落,这个处理函数可以在一个入口中将所有内容整合起来。另一个函数MapCompose(),可以与Python函数或Python函数链结合,实现复杂的功能。例如,MapCompose(float)可以将字符串转化为数字,MapCompose(unicode.strip, unicode.title)可以去除多余的空格,并将单词首字母大写。让我们看几个处理函数的例子:
| 处理函数 | 功能 |
|---|---|
| Join() | 合并多个结果。 |
| MapCompose(unicode.strip) | 除去空格。 |
| MapCompose(unicode.strip, unicode.title) | 除去空格,单词首字母大写。 |
| MapCompose(float) | 将字符串转化为数字。 |
| MapCompose(lambda i: i.replace(',', ''), float) | 将字符串转化为数字,逗号替换为空格。 |
| MapCompose(lambda i: urlparse.urljoin(response.url, i)) | 使用response.url为开头,将相对URL转化为绝对URL。 |
你可以使用Python编写处理函数,或是将它们串联起来。unicode.strip()和unicode.title()分别用单一参数实现了单一功能。其它函数,如replace()和urljoin()需要多个参数,我们可以使用Lambda函数。这是一个匿名函数,可以不声明函数就调用参数:
myFunction = lambda i: i.replace(',', '')
可以取代下面的函数:
def myFunction(i):
return i.replace(',', '')
使用Lambda函数,打包replace()和urljoin(),生成一个结果,只需一个参数即可。为了更清楚前面的表,来看几个实例。在scrapy命令行打开任何URL,并尝试:
>>> from scrapy.loader.processors import MapCompose, Join
>>> Join()(['hi','John'])
u'hi John'
>>> MapCompose(unicode.strip)([u' I',u' am\n'])
[u'I', u'am']
>>> MapCompose(unicode.strip, unicode.title)([u'nIce cODe'])
[u'Nice Code']
>>> MapCompose(float)(['3.14'])
[3.14]
>>> MapCompose(lambda i: i.replace(',', ''), float)(['1,400.23'])
[1400.23]
>>> import urlparse
>>> mc = MapCompose(lambda i: urlparse.urljoin('http://my.com/test/abc', i))
>>> mc(['example.html#check'])
['http://my.com/test/example.html#check']
>>> mc(['http://absolute/url#help'])
['http://absolute/url#help']
要记住,处理函数是对XPath/CSS结果进行后处理的的小巧函数。让我们来看几个我们爬虫中的处理函数是如何清洗结果的:
def parse(self, response):
l.add_xpath('title', '//*[@itemprop="name"][1]/text()',
MapCompose(unicode.strip, unicode.title))
l.add_xpath('price', './/*[@itemprop="price"][1]/text()',
MapCompose(lambda i: i.replace(',', ''), float),
re='[,.0-9]+')
l.add_xpath('description', '//*[@itemprop="description"]'
'[1]/text()', MapCompose(unicode.strip), Join())
l.add_xpath('address',
'//*[@itemtype="http://schema.org/Place"][1]/text()',
MapCompose(unicode.strip))
l.add_xpath('image_URL', '//*[@itemprop="image"][1]/@src',
MapCompose(
lambda i: urlparse.urljoin(response.url, i)))
完整的列表在本章后面给出。如果你用scrapy crawl basic再运行的话,你可以得到干净的结果如下:
'price': [334.39],
'title': [u'Set Unique Family Well']
最后,我们可以用add_value()方法添加用Python(不用XPath/CSS表达式)计算得到的值。我们用它设置我们的“杂务字段”,例如URL、爬虫名、时间戳等等。我们直接使用前面杂务字段表里总结的表达式,如下:
l.add_value('url', response.url)
l.add_value('project', self.settings.get('BOT_NAME'))
l.add_value('spider', self.name)
l.add_value('server', socket.gethostname())
l.add_value('date', datetime.datetime.now())
记得import datetime和socket,以使用这些功能。
现在,我们的Items看起来就完美了。我知道你的第一感觉是,这可能太复杂了,值得吗?回答是肯定的,这是因为或多或少,想抓取网页信息并存到items里,这就是你要知道的全部。这段代码如果用其他语言来写,会非常难看,很快就不能维护了。用Scrapy,只要25行简洁的代码,它明确指明了意图,你可以看清每行的意义,可以清晰的进行修改、再利用和维护。
你的另一个感觉可能是处理函数和ItemLoaders太花费精力。如果你是一名经验丰富的Python开发者,你已经会使用字符串操作、lambda表达构造列表,再学习新的知识会觉得不舒服。然而,这只是对ItemLoader和其功能的简单介绍,如果你再深入学习一点,你就不会这么想了。ItemLoaders和处理函数是专为有抓取需求的爬虫编写者、维护者开发的工具集。如果你想深入学习爬虫的话,它们是绝对值得学习的。
创建协议
协议有点像爬虫的单元测试。它们能让你快速知道错误。例如,假设你几周以前写了一个抓取器,它包含几个爬虫。你想快速检测今天是否还是正确的。协议位于评论中,就在函数名后面,协议的开头是@。看下面这个协议:
def parse(self, response):
""" This function parses a property page.
@url http://web:9312/properties/property_000000.html
@returns items 1
@scrapes title price description address image_URL
@scrapes url project spider server date
"""
这段代码是说,检查这个URL,你可以在找到一个项目,它在那些字段有值。现在如果你运行scrapy check,它会检查协议是否被满足:
$ scrapy check basic
----------------------------------------------------------------
Ran 3 contracts in 1.640s
OK
如果url的字段是空的(被注释掉),你会得到一个描述性错误:
FAIL: [basic] parse (@scrapes post-hook)
------------------------------------------------------------------
ContractFail: 'url' field is missing
当爬虫代码有错,或是XPath表达式过期,协议就可能失效。当然,协议不会特别详细,但是可以清楚的指出代码的错误所在。
综上所述,我们的第一个爬虫如下所示:
from scrapy.loader.processors import MapCompose, Join
from scrapy.loader import ItemLoader
from properties.items import PropertiesItem
import datetime
import urlparse
import socket
import scrapy
class BasicSpider(scrapy.Spider):
name = "basic"
allowed_domains = ["web"]
# Start on a property page
start_URL = (
'http://web:9312/properties/property_000000.html',
)
def parse(self, response):
""" This function parses a property page.
@url http://web:9312/properties/property_000000.html
@returns items 1
@scrapes title price description address image_URL
@scrapes url project spider server date
"""
# Create the loader using the response
l = ItemLoader(item=PropertiesItem(), response=response)
# Load fields using XPath expressions
l.add_xpath('title', '//*[@itemprop="name"][1]/text()',
MapCompose(unicode.strip, unicode.title))
l.add_xpath('price', './/*[@itemprop="price"][1]/text()',
MapCompose(lambda i: i.replace(',', ''),
float),
re='[,.0-9]+')
l.add_xpath('description', '//*[@itemprop="description"]'
'[1]/text()',
MapCompose(unicode.strip), Join())
l.add_xpath('address',
'//*[@itemtype="http://schema.org/Place"]'
'[1]/text()',
MapCompose(unicode.strip))
l.add_xpath('image_URL', '//*[@itemprop="image"]'
'[1]/@src', MapCompose(
lambda i: urlparse.urljoin(response.url, i)))
# Housekeeping fields
l.add_value('url', response.url)
l.add_value('project', self.settings.get('BOT_NAME'))
l.add_value('spider', self.name)
l.add_value('server', socket.gethostname())
l.add_value('date', datetime.datetime.now())
return l.load_item()
提取更多的URL
到目前为止,在爬虫的start_URL中我们还是只加入了一条URL。因为这是一个元组,我们可以向里面加入多个URL,例如:
start_URL = (
'http://web:9312/properties/property_000000.html',
'http://web:9312/properties/property_000001.html',
'http://web:9312/properties/property_000002.html',
)
不够好。我们可以用一个文件当做URL源文件:
start_URL = [i.strip() for i in
open('todo.URL.txt').readlines()]
还是不够好,但行得通。更常见的,网站可能既有索引页也有列表页。例如,Gumtree有索引页:http://www.gumtree.com/flats-houses/london:
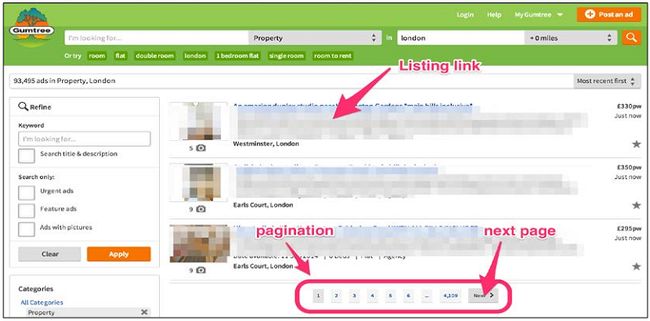
一个典型的索引页包含许多列表页、一个分页系统,让你可以跳转到其它页面。

因此,一个典型的爬虫在两个方向移动:
- 水平——从索引页到另一个索引页
- 垂直——从索引页面到列表页面提取项目
在本书中,我们称前者为水平抓取,因为它在同一层次(例如索引)上抓取页面;后者为垂直抓取,因为它从更高层次(例如索引)移动到一个较低的层次(例如列表)。
做起来要容易许多。我们只需要两个XPath表达式。第一个,我们右键点击Next page按钮,URL位于li中,li的类名含有next。因此XPath表达式为//*[contains(@class,"next")]//@href。

对于第二个表达式,我们在列表的标题上右键点击,选择检查元素:
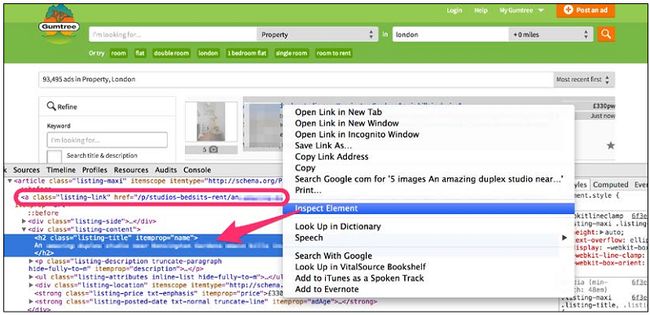
这个URL有一个属性是itemprop="url。因此,表达式确定为//*[@itemprop="url"]/@href。打开scrapy命令行进行确认:
$ scrapy shell http://web:9312/properties/index_00000.html
>>> URL = response.xpath('//*[contains(@class,"next")]//@href').extract()
>>> URL
[u'index_00001.html']
>>> import urlparse
>>> [urlparse.urljoin(response.url, i) for i in URL]
[u'http://web:9312/scrapybook/properties/index_00001.html']
>>> URL = response.xpath('//*[@itemprop="url"]/@href').extract()
>>> URL
[u'property_000000.html', ... u'property_000029.html']
>>> len(URL)
30
>>> [urlparse.urljoin(response.url, i) for i in URL]
[u'http://..._000000.html', ... /property_000029.html']
很好,我们看到有了这两个表达式,就可以进行水平和垂直抓取URL了。
使用爬虫进行二维抓取
将前一个爬虫代码复制到新的爬虫manual.py中:
$ ls
properties scrapy.cfg
$ cp properties/spiders/basic.py properties/spiders/manual.py
在properties/spiders/manual.py中,我们通过添加from scrapy.http import Request引入Request,将爬虫的名字改为manual,将start_URL改为索引首页,将parse()重命名为parse_item()。接下来写心得parse()方法进行水平和垂直的抓取:
def parse(self, response):
# Get the next index URL and yield Requests
next_selector = response.xpath('//*[contains(@class,'
'"next")]//@href')
for url in next_selector.extract():
yield Request(urlparse.urljoin(response.url, url))
# Get item URL and yield Requests
item_selector = response.xpath('//*[@itemprop="url"]/@href')
for url in item_selector.extract():
yield Request(urlparse.urljoin(response.url, url),
callback=self.parse_item)
提示:你可能注意到了yield声明。它和return很像,不同之处是return会退出循环,而yield不会。从功能上讲,前面的例子与下面很像
next_requests = [] for url in... next_requests.append(Request(...)) for url in... next_requests.append(Request(...)) return next_requestsyield可以大大提高Python编程的效率。
做好爬虫了。但如果让它运行起来的话,它将抓取5万张页面。为了避免时间太长,我们可以通过命令-s CLOSESPIDER_ITEMCOUNT=90(更多的设定见第7章),设定爬虫在一定数量(例如,90)之后停止运行。开始运行:
$ scrapy crawl manual -s CLOSESPIDER_ITEMCOUNT=90
INFO: Scrapy 1.0.3 started (bot: properties)
...
DEBUG: Crawled (200) <...index_00000.html> (referer: None)
DEBUG: Crawled (200) <...property_000029.html> (referer: ...index_00000.html)
DEBUG: Scraped from <200 ...property_000029.html>
{'address': [u'Clapham, London'],
'date': [datetime.datetime(2015, 10, 4, 21, 25, 22, 801098)],
'description': [u'situated camden facilities corner'],
'image_URL': [u'http://web:9312/images/i10.jpg'],
'price': [223.88],
'project': ['properties'],
'server': ['scrapyserver1'],
'spider': ['manual'],
'title': [u'Portered Mile'],
'url': ['http://.../property_000029.html']}
DEBUG: Crawled (200) <...property_000028.html> (referer: ...index_00000.
html)
...
DEBUG: Crawled (200) <...index_00001.html> (referer: ...)
DEBUG: Crawled (200) <...property_000059.html> (referer: ...)
...
INFO: Dumping Scrapy stats: ...
'downloader/request_count': 94, ...
'item_scraped_count': 90,
查看输出,你可以看到我们得到了水平和垂直两个方向的结果。首先读取了index_00000.html, 然后产生了许多请求。执行请求的过程中,debug信息指明了谁用URL发起了请求。例如,我们看到,property_000029.html, property_000028.html ... 和 index_00001.html都有相同的referer(即index_00000.html)。然后,property_000059.html和其它网页的referer是index_00001,过程以此类推。
这个例子中,Scrapy处理请求的机制是后进先出(LIFO),深度优先抓取。最后提交的请求先被执行。这个机制适用于大多数情况。例如,我们想先抓取完列表页再取下一个索引页。不然的话,我们必须消耗内存存储列表页的URL。另外,许多时候你想用一个辅助的Requests执行一个请求,下一章有例子。你需要Requests越早完成越好,以便爬虫继续下面的工作。
我们可以通过设定Request()参数修改默认的顺序,大于0时是高于默认的优先级,小于0时是低于默认的优先级。通常,Scrapy会先执行高优先级的请求,但不会花费太多时间思考到底先执行哪一个具体的请求。在你的大多数爬虫中,你不会有超过一个或两个的请求等级。因为URL会被多重过滤,如果我们想向一个URL多次请求,我们可以设定参数dont_filter Request()为True。
用CrawlSpider二维抓取
如果你觉得这个二维抓取单调的话,说明你入门了。Scrapy试图简化这些琐事,让编程更容易。完成之前结果的更好方法是使用CrawlSpider,一个简化抓取的类。我们用genspider命令,设定一个-t参数,用爬虫模板创建一个爬虫:
$ scrapy genspider -t crawl easy web
Created spider 'crawl' using template 'crawl' in module:
properties.spiders.easy
现在properties/spiders/easy.py文件包含如下所示:
...
class EasySpider(CrawlSpider):
name = 'easy'
allowed_domains = ['web']
start_URL = ['http://www.web/']
rules = (
Rule(LinkExtractor(allow=r'Items/'),
callback='parse_item', follow=True),
)
def parse_item(self, response):
...
这段自动生成的代码和之前的很像,但是在类的定义中,这个爬虫从CrawlSpider定义的,而不是Spider。CrawlSpider提供了一个包含变量rules的parse()方法,以完成之前我们手写的内容。
现在将start_URL设定为索引首页,并将parse_item()方法替换。这次不再使用parse()方法,而是将rules变成两个rules,一个负责水平抓取,一个负责垂直抓取:
rules = (
Rule(LinkExtractor(restrict_xpaths='//*[contains(@class,"next")]')),
Rule(LinkExtractor(restrict_xpaths='//*[@itemprop="url"]'),
callback='parse_item')
)
两个XPath表达式与之前相同,但没有了a与href的限制。正如它们的名字,LinkExtractor专门抽取链接,默认就是寻找a、href属性。你可以设定tags和attrs自定义LinkExtractor()。对比前面的请求方法Requests(self.parse_item),回调的字符串中含有回调方法的名字(例如,parse_item)。最后,除非设定callback,一个Rule就会沿着抽取的URL扫描外链。设定callback之后,Rule才能返回。如果你想让Rule跟随外链,你应该从callback方法return/yield,或设定Rule()的follow参数为True。当你的列表页既有Items又有其它有用的导航链接时非常有用。
你现在可以运行这个爬虫,它的结果与之前相同,但简洁多了:
$ scrapy crawl easy -s CLOSESPIDER_ITEMCOUNT=90
总结
对所有学习Scrapy的人,本章也许是最重要的。你学习了爬虫的基本流程UR2IM、如何自定义Items、使用ItemLoaders,XPath表达式、利用处理函数加载Items、如何yield请求。我们使用Requests水平抓取多个索引页、垂直抓取列表页。最后,我们学习了如何使用CrawlSpider和Rules简化代码。多度几遍本章以加深理解、创建自己的爬虫。
我们刚刚从一个网站提取了信息。它的重要性在哪呢?答案在下一章,我们只用几页就能制作一个移动app,并用Scrapy填充数据。
序言
第1章 Scrapy介绍
第2章 理解HTML和XPath
第3章 爬虫基础
第4章 从Scrapy到移动应用
第5章 快速构建爬虫
第6章 Scrapinghub部署
第7章 配置和管理
第8章 Scrapy编程
第9章 使用Pipeline
第10章 理解Scrapy的性能
第11章(完) Scrapyd分布式抓取和实时分析