AIOps 人工智能和IT运营支撑 Ops 之间的故事,愈演愈烈,已经成为当今运维圈的热门话题,我打算从2篇文档分享我们在 AIOps 上一些探索和实践。(上篇)主要介绍了为什么事件(告警)处理需要 AIOps;(本篇)主要分享OneAlert 事件处理平台在 AIOps 方面的探索。
上篇提到规模化的 IT 事件管理中,需要人工智能识别重要信息,去除噪音,甄别关键信息,减少人力工作量。
举个栗子:假设某企业的 IT 环境中的某个底层基础设施,如网络或存储设备出现异常,相关联的主机、中间件数据库、消息队列、缓存,应用程序,业务服务会受到影响。当监控和管理系统全面的探测发现这些问题的话,会瞬间(数十秒)产生大量的事件,而且这些事件随着时间的推移不断的发生(1-2分钟),假设都加入通知提醒的话,邮箱瞬间爆满。实际上,随着规模化和复杂度增加,这些现象经常性发生。
OneAlert 在事件(告警)处理方面经营多年,借助人工智能技术,在以下几个方面进行探索,尝试解决上述问题:
降噪,消除不重要的事件,识别重要关键信息,避免告警疲劳。
聚类,将相关的事件聚合起来,分门别类,特别是在告警风暴方面应用。
识别根因,在数千事件中识别出可能是根因的问题。
决策支持,相似问题推荐,实现知识复用。

基本核心思路是对数据进行处理,将成千上万的事件过滤、甄别、筛选,如漏斗般,多层过滤杂质,沉淀下金沙。
降噪
当大量的杂音事件频发骚扰我们工程师,会引发告警疲劳,就是所谓的无感。体现为事件太多,跟己相关的较少,重要的事情淹没在汪洋大海中。
降噪的目的,就是去除噪音,留下乐章。事件处理过程中,传统的做法是去重,将重复的事件去除掉,简单有效。OneAlert 早期版本就是这样,从时间维度上,相同的事件仅发生一次,之后再发生只会在事件的计数器上体现。基本上该方法能达到 80%-95% 左右的压缩率,刨去杂音,将数万数千事件缩减为数百和数十。
OneAlert 的新用户会有一个习惯过程,从 Zabbix 或者其他监控工具过来的相同事件,只会合并为一条,通过分发升级机制通知到位,提醒快速处理。习惯后,基本上通知到位的事件都需要关注下。
去重的做法简单有效,然而不能完全解决栗子中的很多不同类型事件发生问题,特别规模大的时候,几百主机、数十中间件、数百应用、数千微服务、数十业务服务的告警事件的过滤。所以我们引入了新的算法,借鉴信息论熵的概念。
什么是熵?
“说不清楚的事就叫伤(熵)!”。信息是一个很抽象的概念,信息多少很难说清楚。如一本小说有多少信息量?一个事件有多少信息量?
知道1948年,香农提出了“信息熵”的概念,才解决了信息的量化度量问题。热力学的热熵表示分子状态混乱程度,香农用信息熵来度量信源的不确定性。
再举个栗子~
小明不爱学习,小李爱学习,小明考试十有八九不及格,小李经常满分。
事件A:小明考试及格,对应的概率 P(xA)=0.1,信息量为 I(xA)=−log(0.1)=3.3219
事件B:小李考试及格,对应的概率 P(xB)=0.999,信息量为 I(xB)=−log(0.999)=0.0014
小明及格率低,如果有一次及格了,大家会很惊讶,小明居然及格了!!! 信息量好大呀!
从熵的角度看:
小明的熵:HA(x)=−[p(xA)log(p(xA))+(1−p(xA))log(1−p(xA))]=0.4690
小李的熵:HB(x)=−[p(xB)log(p(xB))+(1−p(xB))log(1−p(xB))]=0.0114
小明结果不确定,毕竟10次有9次不及格,小李比较确定(1000次考试只有一次可能不及格,结果相当确定)
熵越大,信息的不确定性高,利用熵的特性,我们尝试来解决告警事件信息的过滤问题。
熵和自然语言处理 NLP
由于 OneAlert 接收的事件是非结构化的文本数据,通过人工智能算法,结合自然语言处理 NLP 技术。使用 NLP 文本的分词、命名实体识别等特性,实现数据处理。
从内容信息上的信息量(熵)。例如 CPU 使用率超过阈值,和存储设备宕机是完全不同的,后者明显重要和信息量更大。做到这一点需要解决两个问题:
1. 需要从自然语言内容的角度去理解信息。特别要指出的是 IT 运营支撑专业术语和电商语言、新闻类语言是有差异的。例如电商里面,面膜和护肤词语有很大关联,而监控里面交换机 Switch 和端口 Port 有很大关联,通用的自然语言处理技术应用到专业领域里面有一定的难度。
2. 某个用户的告警事件有可能从来没有发生过,意味着第一次发生的时候这些数据(内容)需要在识别出来。如新上的存储设备3月来运行良好,结果今天刚好故障。
解决这两个问题,依赖于 OneAlert 多年来 SaaS 运营积累了各行各业的告警事件数据,通过对这些数据进行处理,建立起专业的监控告警自然语言文本语料库,这个库可以说是当今中国少见的。
1. 覆盖各行各业,感谢金融(招行、借贷宝、盛开金融),出行(马蜂窝、ofo、摩拜),电信运营商,云服务商(网宿、七牛、云牛)、制造业( TCL、美的)、游戏(壳木、灵刃、闲来胡娱)、以及用友、良品铺子、德电、铜板街、供销大数据、趋势科技、华大基因等各行业优秀公司。
2. 覆盖层次多,基础设施、中间件、应用、大数据、业务以及微服务,生产制造过程中各类信息。
通过建立专业的告警事件自然语言语料库,帮助我们深入的从内容的角度去告警事件信息。A 用户首次发生的存储故障,其实在 B 用户已经发生过了,我们能够识别该信息的内容熵,比 CPU 使用率告警更重要(每家每户都发生)。
除了信息内容的理解,建立内容熵,我们还考虑时间维度,我们称为时间熵。例如同样是 MySQL Slave Down 进程故障,天天发生和几个月发生一次的信息量也不同,所以我们还要考虑时间维度的发生频率问题。
结合内容熵和时间熵,我们标识事件(告警)的重要度,帮助工程聚焦问题,实现降噪处理。
信息熵的应用还很广,在事件处理上,应该还要考虑上下文、IT 环境等一系列因素,我们也在探索。例如存储设备/网络故障会比主机故障更为重要,拓扑依赖关系、层次结构等上下文因素会对信息的识别有更大影响。
利用人工智能、信息论等技术,我们在成千上万的事件,挑选和甄别出重要事件,让工程师更聚焦,从而更快处理。但是事件本身还是零散的,还是需要工程师去挨个查看,所以我们引入了聚类技术。
聚类
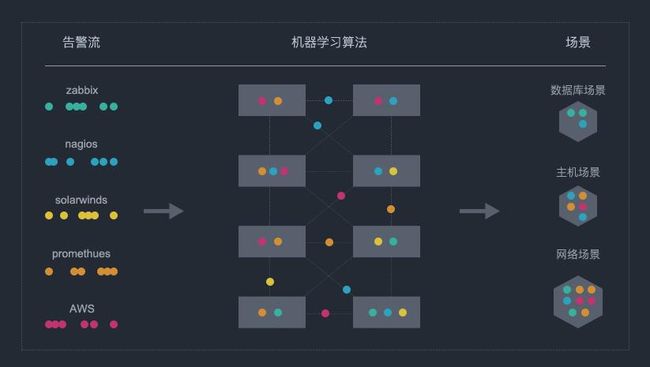
回到文中第一个栗子,降噪将告警事件处理后,还有数十数百个事件,很多是类似的,例如存储类 Lun1、Lun2故障,主机 A\B\C… 故障,数据库 Master1、Master2、Slave1… 应用 Order_1_8080,order_2_8080…,业务 支付、门户等。
其实就是有几类事情,存储类、主机类(支付类主机、门户类主机)、数据库集群、支付类应用、门户类应用等几大类。从职责划分和管理流程方面,也是不同团队负责。如果能够将这些零散的事件分门别类,就更清晰和有助于处理(职责划分)。
常用做法一般是定义大量的规则,建立起专家系统(规则库),这种模式在IT系统规模或者是复杂度相对较小时,比较适用。例如同一个网络设备上的端口故障合并在一起。随着时间的推移,配套的知识规则需要不断的完善,对人力的要求和管理要求更高。当IT环境变化和调整后,如果配套的规则没有更新,或者是规则不够全面和完善,则有可能逐渐荒废,沦落为无用。
也有不少用户提出使用 CMDB,构建完善的拓扑依赖关系的模式,去从根源上进行追溯实现聚类合并,然而CMDB和拓扑关系的维护,也面临着动态化实时准确性问题。而且在 CMDB 建设过程中往往会出现过大过重,萝卜青菜一起管的情况,实现管理职责清晰、边界明确的可能性很低,特别是在业务和服务驱动的情况下,后端和底层IT支撑往往迫于形势,CMDB 被迫纳管更多内容。
以上两类做法其实都是依赖于管理制度,并辅助工具的做法。特点是需要依赖人工大量干预。历经多年建设,有些优秀互联网企业做的很极致,管理也很到位,效果明显。
我们希望通过轻量级的方式和重量级相结合来实现聚类的准确性。轻量级的意思是,通过算法和简化的策略规则,无需过多的前提条件,快速实现告警事件的聚合。将上述栗子的大量事件,划分为存储、数据库、应用和不同业务。普适性更强,见效更快~
告警事件之间是存在一定的关联性的,将一组类似的有关系的事件聚合在一起就是一个场景。以场景为单位去实现团队的分派/协作,最终解决问题,而不是单一事件的逐条解决。在移动化今天,有什么事,临时拉个讨论组/微信群,一起讨论和解决问题;场景与此类似。
利用人工智能无监督学习技术,结合自然语言处理 NLP,我们从内容相似性、相关性进行数据挖掘和学习。
内容相似性,一名普通工程师一眼就能看清楚 MySQL Slave1 和 Slave2 的相似性,然而程序和计算机能够理解这事就有点困难了。幸运的是,我们利用在降噪过程中我们建立的专业语料库,能够识别出当下相似告警,将符合相似度(如80%)的事件聚合在一起。
时间相关性,这个可能会好理解一些,就是根据事件发生的时间差,在一瞬间爆发的大量事件是存在一定关联性的,特别是开篇的那个栗子。然而由于监控工具的数据采集问题,现实的事件并不是严格的按照时间序列过来的,例如业务故障和存储故障,从直觉角度上看,应该是存储故障先发生,之后才影响业务。实际上,两者的事件时间有可能是相反的。
通过算法,在没有过多的前提条件下,实现将相似相关事件聚合称为一个场景。
与降噪一样,算法应该跟上下文和环境相关,所以未来在聚类的方面可以做的更深入,更重量级。
识别根源
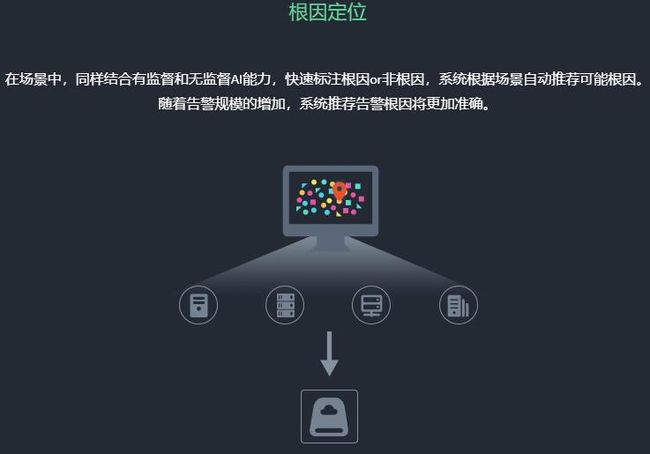
在现在为止,我们通过降噪将事件从数千数万降低为数百数十,聚类降低为数类数十。到此为止基本上能够更高效的处理问题,然而,我们总是期望能够定位到根源,甄别是那些异常引发的,快速识别根因是所有IT支撑工程师的追求。找到标靶,拉弓射箭,中靶,一气呵成。
现实是很困难,如果想100%的确定根因,必须对 IT 环境的每个环节和设施进行管理,并建立数据模型。在当今的规模化、虚拟化、微服务化情况下,这是很困难的事情。
所以往往依赖于有经验的工程师进行分析和判断,如果在跨职责、跨业务、跨团队的时候,就需要多个不同领域的专家工程师去诊断和分析了。
借助人工智能算法,通过有监督的训练方式,通过历史和人为标注的数据。工程师每一次的根源识别,都可以作为机器学习训练的素材。随着时间的推移,诊断标注的根源数据积累越多,机器就能够准确的识别出因果关系,根源识别也越来越准确。
前文的栗子中,如果有类似历史数据,并且完成人工标注,那么再次发生的时候,我们就可以判断存储或者是网络故障是根因,可能性85%。
通过人工智能方式,逐渐的摆脱严重依赖专家工程师的模式,让运营支撑系统成为一个能够自我学习和进化的智能系统。
决策支持
识别场景,甄选根因后,我们基本上就可以着手解决问题。在处理问题的过程中,会出现一个知识传递的问题。例如有经验的工程师和新入职的工程师的差异,其实这就是一个集体知识共享的问题。
以往大多团队会使用 Wiki 或者是别的工具建立知识库,人工编辑文章和处理预案。以方便工程师参考借鉴,但是也有很多团队没有建立起共享知识库。
我们通过人工智能的方式做了一些尝试,让整个事件(告警)处理更流畅起来。场景历史推荐,对于新发生的场景,如果以前有类似的场景,系统会推荐出来,如在上个月有一个类似的故障,相似度80%,也是一个存储类故障。通过查看历史场景的解决方案/过程,帮助我们做决策,可以快速的复用历史知识。整个过程中,人工智能自动学习和推荐,告别人工手动编辑知识文档的方式。
随着时间的推移,系统越发智能,信息积累越多,也会持续反复使用。
小结
AIOps 的应用和实践会越来越多,我们有理由相信人工智能技术,会对 IT 运营支撑产生极大的影响力。
OneAlert 在该领域的探索还属于入门级,然而我们也迫不及待和大家分享。我们将发布 OneAlert AI 版,这应该是国内鲜见、SaaS 模式的人工智能事件处理平台。现在开始对新老用户开放内测 www.onealert.com,欢迎大家一起探索。
随着更多的用户对人工智能的了解应用,相信不久的将来,正如 Gartner 说的,未来将有50%的企业使用 AIOps 方式运营支撑,人工智能对企业 IT 运营效率的提升和变革,也将促进这些企业的商业发展提速。
未来已来。
OneAlert 是北京蓝海讯通科技股份有限公司旗下产品,是国内首个 SaaS 模式的云告警平台,集成国内外主流监控/支撑系统,实现一个平台上集中处理所有 IT 事件,提升 IT 可靠性。想了解更多信息,请访问 OneAlert 官网 ,欢迎免费注册体验 。
来源:http://blog.oneapm.com/apm-tech/824.html