【Pandas】Pandas实战
原文:https://www.datacamp.com/community/blog/python-pandas-cheat-sheet
参考文档:http://pandas.pydata.org/pandas-docs/stable/contributing.html
Python数据分析库Pandas基础知识快速指南,包括代码示例。
Pandas库是为数据科学家最喜欢的工具进行数据处理和分析。
快速,灵活和富有表现力的Pandas数据结构旨在使真实世界的数据分析变得更加容易,但对于刚开始使用它的人来说,这可能不会立即发生。正是因为这个软件包内置了如此多的功能,所以这些选项非常令人难以置信。这是Pandas基础知识的快速指南,您将需要开始使用Python来处理数据。
因此,如果您刚刚开始与Pandas一起开展数据科学旅程,或者对于那些尚未开始的人员,您可以将其作为指导使其更易于学习关于并使用它。
本文将指导您完成Pandas库的基础知识,从数据结构到I / O,选择,删除索引或列,排序和排序,检索您正在使用的数据结构的基本信息以应用功能和数据对齐。
使用以下导入Pandas库:
>>> import pandas as pd
Pandas数据结构
Series
一维标签阵列,可以保存任何数据类型>>> s = pd.Series([3, -5, 7, 4], index=['a', 'b', 'c', 'd'])
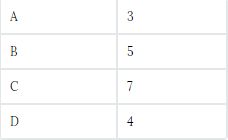
数据帧(DataFrame)
具有可能不同类型列的二维标签数据结构>>> data = {'Country': ['Belgium', 'India', 'Brazil'],
'Capital': ['Brussels', 'New Delhi', 'Brasilia'],
'Population': [11190846, 1303171035, 207847528]}
>>> df = pd.DataFrame(data,columns=['Country', 'Capital', 'Population'])

请注意,第一列1,2,3是索引和国家,首都,人口是列。
寻求帮助
>>> help(pd.Series.loc)
I / O
读取和写入CSV
>>> pd.read_csv('file.csv', header=None, nrows=5)>>> pd.to_csv('myDataFrame.csv')
从同一个文件中读取多张表
>>> xlsx = pd.ExcelFile('file.xls')>>> df = pd.read_excel(xlsx, 'Sheet1')
读取和写入Excel
>>> pd.read_excel('file.xlsx')>>> pd.to_excel('dir/myDataFrame.xlsx', sheet_name='Sheet1')
读取和写入SQL查询或数据库表
(read_sql()是read_sql_table()和read_sql_query()的便捷包装)>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///:memory:')
>>> pd.read_sql(SELECT * FROM my_table;, engine)
>>> pd.read_sql_table('my_table', engine)
>>> pd.read_sql_query(SELECT * FROM my_table;', engine)
>>> pd.to_sql('myDf', engine)
选择
获取
获取一个元素
>>> s['b']-5
获取DataFrame的子集
>>> df[1:]Country Capital Population
1 India New Delhi 1303171035
2 Brazil Brasilia 207847528
选择布尔索引和设置
按位置
按行和列选择单个值>>> df.iloc([0], [0])
'Belgium'
>>> df.iat([0], [0])
'Belgium'
按标签
按行和列标签选择单个值>>> df.loc([0], ['Country'])
'Belgium'
>>> df.at([0], ['Country'])
'Belgium'
按标签/位置
选择单行的子集>>> df.ix[2]
Country Brazil
Capital Brasilia
Population 207847528
选择一列列的子集
>>> df.ix[:, 'Capital']0 Brussels
1 New Delhi
2 Brasilia
选择行和列
>>> df.ix[1, 'Capital']'New Delhi'
布尔索引
系列s,其值不大于1>>> s[~(s > 1)]
s值在<-1或> 2时
>>> s[(s < -1) | (s > 2)]使用过滤器来调整DataFrame
>>> df[df['Population']>1200000000]设置
将系列s的索引a设置为6>>> s['a'] = 6
删除
从行中删除值(axis = 0)>>> s.drop(['a', 'c'])
从列中删除值(axis = 1)
>>> df.drop('Country', axis=1)排序和排名
按轴标签排序>>> df.sort_index()
按轴排序值
>>> df.sort_values(by='Country')将条目分配给条目
>>> df.rank()检索系列/数据帧信息
基本信息
(行,列)>>> df.shape
描述索引
>>> df.index描述DataFrame列
>>> df.columnsDataFrame上的信息
>>> df.info()非NA值的数量
>>> df.count()概要
值的总和>>> df.sum()
累积的价值总和
>>> df.cumsum()最小值/最大值
>>> df.min()/df.max()最小/最大索引值
>>> df.idxmin()/df.idxmax()汇总统计
>>> df.describe()价值的平均值
>>> df.mean()值的中间值
>>> df.median()应用功能
>>> f = lambda x: x*2应用功能
>>> df.apply(f)应用功能元素明智
>>> df.applymap(f)内部数据对齐
NA值在不重叠的指数中引入:>>> s3 = pd.Series([7, -2, 3], index=['a', 'c', 'd'])
>>> s + s3
a 10.0
b NaN
c 5.0
d 7.0
使用填充方法的算术运算
您也可以在填充方法的帮助下自行完成内部数据对齐操作:>>> s.add(s3, fill_value=0)
a 10.0
b -5.0
c 5.0
d 7.0
>>> s.sub(s3, fill_value=2)
>>> s.div(s3, fill_value=4)
>>> s.mul(s3, fill_value=3)数据结构