【机器学习】机器学习中无意识偏见的分析与预防
关键要点
- 深度学习算法越来越多地被用于制定影响生命的决策,例如雇用和解雇员工以及刑事司法系统。
- 机器学习实际上可以放大偏见。研究人员发现,67%的人烹饪图像是女性,但该算法将84%的厨师称为女性。
- Pro Publica发现,对于白人被告(24%),黑人被告(错误率为45%)的误报率几乎是其两倍。
- Buolamwini和Gebru在他们的研究中发现ML分类器在男性上比在女性上更好,对于皮肤较浅的人而言比在深色皮肤上的人更好。
- 像1967年的“年龄歧视和就业法”和“平等信用机会法”这样的人工智能法规并不完美,但比没有任何保护要好。
本文基于Rachel Thomas在2018年QCon.ai上的主题演讲“分析和预防机器学习中的无意识偏见” 。Thomas在fast.ai工作,这是一家非盈利研究实验室,与旧金山大学数据研究所合作,为开发者社区提供深度学习培训。该实验室提供免费课程,称为“编码实用深度学习”。
托马斯讨论了关于机器学习偏差的三个案例研究,其来源以及如何避免它。
案例研究1:招聘,解雇和刑事司法系统软件
深度学习算法越来越多地被用于制定影响生命的决策,例如雇用和解雇员工以及刑事司法系统。编码偏差会给决策过程带来陷阱和风险。
Pro Publica在2016年 调查 了COMPAS 再犯算法 ,该 算法用于预测囚犯或被控犯罪者如果被释放可能会犯下更多罪行的可能性。该算法用于授予保释,判刑和确定假释。Pro Publica发现,对于白人被告(24%),误报率(标记为“高风险”但未重新犯罪)几乎是黑人被告(错误率45%)的两倍。
种族不是这个算法的明确变量,但种族和性别在很多其他变量中潜伏编码,比如我们居住的地方,我们的社交网络和我们的教育。即使是不注意种族或性别的有意识的努力并不能保证缺乏偏见 - 假设失明不起作用。尽管人们对COMPAS的准确性存有疑虑,但威斯康星州最高法院去年仍坚持使用它。托马斯认为它仍在使用中令人震惊。
有一个良好的基线来了解什么是良好的性能并帮助表明更简单的模型可能更有效,这一点很重要。仅仅因为某些事情很复杂,并不意味着它有效。人工智能(AI)用于预测性警务是一个值得关注的问题。
Taser去年收购了两家AI公司,并向警察部门推销预测软件。该公司拥有美国80%的警用摄像机市场,因此他们拥有大量的视频数据。此外,Verge 在2月份透露, 新奥尔良警方过去六年一直在使用Palantir的预测性警务软件进行绝密计划,即使是市议会成员也不知道。像这样的应用程序是值得关注的,因为没有透明度。因为这些是私营公司,所以它们不像警察部门那样受制于州/公共记录法。通常,他们在法庭上受到保护,不必透露他们正在做的事情。
此外,现有的警方数据存在很多种族偏见,因此这些算法将要从中学习的数据集从一开始就存在偏见。
最后,计算机视觉反复失败,无法对有色人种工作。托马斯说这是一个可怕的事情组合。
案例研究2:计算机视觉
计算机视觉往往不善于识别有色人种。其中一个最臭名昭着的例子来自2015年。谷歌照片,自动标记照片,有用地分类毕业照片和建筑物的图像。它还将黑人称为大猩猩。
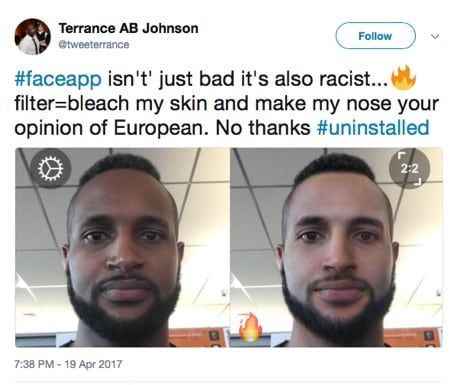
2016年, Beauty.AI 网站使用人工智能机器人作为选美比赛的评委。研究发现,皮肤较浅的人比黑皮肤的人更有吸引力。而在2017年, FaceApp使用神经网络为照片创建过滤器,创建了一个温度过滤器,可以减轻人们的皮肤并赋予它们更多的欧洲特色。Rachel展示了用户实际面部的推文和应用程序创建的更热门的版本。
Thomas谈到了 Joy Buolamwini和Timnit Gebru撰写的一篇 研究论文,他评估了微软,IBM和Face ++(一家中国公司)的几款商用计算机视觉分类器。他们发现分类器在男性上比在女性上更好,对于皮肤较浅的人而言比在深色皮肤上的人更好。有一个相当明显的差距:浅肤色男性的错误率基本上为0%,但对于深色皮肤的女性,错误率在20%到35%之间。Buolamwini和Gebru也通过皮肤阴影分解了女性的错误率。随着皮肤的黑暗,错误增加。最黑暗皮肤的类别错误率分别为25%和47%。
案例研究3:词嵌入
托马斯的第三个案例研究是谷歌翻译等产品中的嵌入一词。
拿一对句子,比如“她是医生。他是一名护士。“使用Google Translate将其翻译成土耳其语,然后将其翻译成英语。性别变得翻倒,以至于句子现在说:“他是一名医生。她是一名护士。“土耳其语有一个性别中立的单数代词,在英语中被转化为刻板印象。这种情况发生在其他具有性别中立的单数代词的语言中。据记载,翻译刻板印象认为女性懒惰,女性不满意,以及更多的特征化。
托马斯解释了为什么会这样。计算机和机器学习将图片和文字视为数字。在语音识别和图像字幕中使用相同的方法。这些算法的工作方式是他们采用提供的图像和输出“黑衣男子正在弹吉他”或“橙色背心的建筑工人正在路上工作。”同样的机制自动建议对产品中的电子邮件的回应像谷歌智能回复 - 如果有人询问你的假期计划,智能回复建议您可能想说,“还没有计划,”或“我只是发送给你。”
托马斯谈到了fast.ai课程“编码实用深度学习”中的一个例子。在这个例子中,我们可以提供单词并取回图片。给它一个单词“tench”(一种鱼)和“net”并且它返回一张网络中的一张贴纸图片。这种方法经过一堆词语,并没有给我们任何关于词语相似的含义的概念。所以“cat”和“catastrophe”可能是序号聪明但它们之间没有任何语义关系。
更好的方法是将单词表示为向量。Word嵌入表示为高维向量。她举了一个“小猫”,“小狗”和“小鸭”的例子,它们可能在太空中彼此接近,因为它们都是小动物。但是“雪崩”的矢量可能很遥远,因为没有真正的联系。
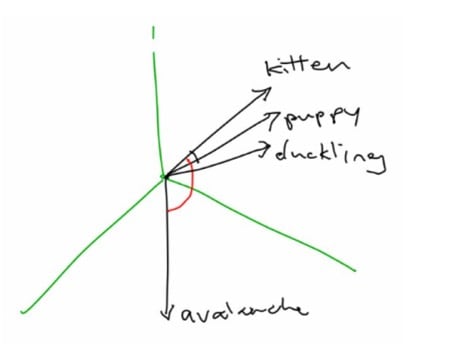
有关单词向量的更多信息,请参阅Adrian Colyer的“ 单词向量的惊人力量 ”。
Word2Vec
Word2Vec是Google发布的词汇嵌入库。还有其他类似的图书馆,如Facebook的fastText和来自斯坦福大学自然语言处理小组的GloVe。它需要大量的数据,时间和计算能力来训练这些库,因此这些团队已经完成了这项工作并将其库发布供公众使用,这很方便。它更容易使用,这是一个已经训练过的版本。所有三个项目的代码都可以在GitHub上获得,托马斯自己的 文字嵌入研讨会也是如此。您可以使用Jupyter Notebook运行她的程序并尝试不同的单词。
像“小狗”和“狗”或“女王”和“公主”这样的类似单词的单词向量距离更近。当然,像“名人”和“尘土飞扬”或“小猫”和“飞机”这样的无关词语更为遥远。该程序使用共同符号相似性,而不是欧几里德距离,因为您不希望在高维中使用欧几里德距离。
您可以使用此解决方案捕获有关语言的内容。您还可以找到特定目标词的10个最接近的单词。例如,如果你寻找最接近“游泳”的单词,你会得到“游泳”,“划船”,“潜水”,“排球”,“体操”和“游泳池”等词。单词类比也很有用。他们捕获的内容包括“西班牙是马德里,意大利是罗马”。但是,这里有很多偏见的机会。例如,“男人”和“天才”之间的距离远小于“女人”和“天才”之间的距离。
研究人员更系统地研究了一篮子文字。他们会拿一篮子或一组字像所有的花:三叶草,罂粟,万寿菊,鸢尾花等。另一个篮子是昆虫:蝗虫,蜘蛛,臭虫,蛆等。他们有一篮子愉快的话语(健康,爱,和平,欢呼等)和一篮子不愉快的话语(虐待,污秽,谋杀,死亡等)。研究人员研究了这些不同的单词篮之间的距离,发现花更接近令人愉快的单词,昆虫更接近不愉快的单词。
到目前为止,这一切似乎都是合理的,但随后研究人员研究了刻板的黑名字和刻板的白色名字。他们发现黑名字更接近不愉快的单词而白名更接近令人愉快的单词,这是一种偏见。他们在整组词语中发现了一些种族和性别偏见,产生了类似“父亲是医生就像母亲就是要护理”,“男人是计算机程序员,女人是家庭主妇”。这些都是在Word2Vec和中找到的所有类比 手套。
托马斯在餐厅评论系统中谈到另一个偏见的例子,墨西哥餐馆的排名较低,因为“墨西哥”的嵌入一词具有负面含义。这些单词嵌入是用巨大的文本语料库进行训练的。这些文本包含许多种族和性别偏见,这就是嵌入这个词在学习我们希望他们知道的语义含义的同时学习这种联想的方式。
机器学习可以放大偏见
机器学习实际上可以放大偏见。“ 男人也喜欢购物:使用语料库限制减少性别偏差放大 ”中讨论了这方面的一个例子,该文章研究了数据集中图像的视觉语义角色标记。研究人员发现67%的人烹饪图像是女性但该算法将84%的厨师称为女性。机器学习算法存在放大我们在现实世界中所看到的风险的风险。
托马斯提到了Zeynep Tufekci的研究,他提供了对技术与社会交叉的见解。Tufekci发推文说“有人告诉我,YouTube自动播放会以各种起点的白色至上主义视频结束,这是非常惊人的。”例如:
- “我正在看一个吹叶机视频和三个视频,这是白色的霸主。”
- “我正在观看有关种植园奴隶制起源的学术讨论,下一个视频来自大屠杀否认者。”
- “我和纳尔逊·曼德拉的女儿一起观看视频,下一段视频说南非的黑人是真正的种族主义者和罪犯。”
太可怕了。
RenéeDiResta,一个虚假信息专家和宣传如何传播,几年前注意到,如果你加入Facebook上的反疫苗组,该网站还会向你的团体推荐天然癌症治疗,化学疗法,扁平地球等等。各种各样的反科学团体。这些网络在促进这种宣传方面做了很多工作。
托马斯提到了一篇关于失控反馈循环如何对预测性警务起作用的研究论文。如果软件或分析预测一个地区会有更多的犯罪,警察可能会派遣更多的警察 - 但由于那里有更多的警察,他们可能会进行更多的逮捕,这可能会让我们认为那里有更多的犯罪,可能会导致我们派出更多的警察。我们可以轻松地进入这个失控的反馈循环。
Thomas建议我们真的需要考虑在模型中包含某些变量的伦理。虽然我们可以访问数据,即使这些数据提高了我们模型的性能,但使用它是否合乎道德?它是否符合我们作为一个社会的价值观?甚至工程师也需要询问有关他们所做工作的道德问题,并且应该能够回答有关它的道德问题。我们将会看到越来越少的社会容忍。
iRobot数据科学总监Angela Bassa说:“这并不是说数据有偏见。数据有偏见。如果你想使用数据,你需要了解它是如何生成的。“
解决字嵌入中的偏差问题
即使我们在模型开发的早期消除了偏见,也有很多偏见可以渗透的地方,我们需要继续关注它。
更具代表性的数据集可以是一种解决方案 Buolamwini和Gebru发现了上面提到的计算机视觉产品中的偏见失败,并将具有不同肤色的男性和女性的更具代表性的数据集组合在一起。性别阴影中提供了此数据集 。该网站还提供他们的学术论文和关于他们工作的简短视频。
Gebru与其他人最近发布了一篇名为“ Datasheets for Datasets ”的论文。本文提供了用于记录特征和元数据的原型数据表,揭示了如何创建数据集,如何编写数据集,执行何种预处理,维护数据集需要哪些工作以及任何法律或道德考虑因素。了解构建模型的数据集非常重要。
托马斯强调,我们的工作是提前考虑意想不到的后果。想想巨魔或骚扰者或专制政府如何使用我们构建的平台。我们的平台如何用于宣传或虚假信息?当Facebook宣布它将开始构建威胁时,很多人都会问为什么在过去的14年里它没有这样做。
还有一个论点是不存储我们不需要的数据,以至于没有人能够获取这些数据。
我们的工作是考虑我们的软件如何在它发生之前被滥用。信息安全领域的文化就是基于此。我们需要开始更多地考虑事情可能出错的方式。
有关AI的问题
托马斯列出了一些有关人工智能的问题:
- 数据有什么偏差?所有数据都有一些偏差,我们需要了解它是什么以及如何创建数据。
- 可以审核代码和数据吗?他们是开源的吗?当使用闭源专有算法来决定医疗保健和刑事司法中的事情以及谁被雇用或被解雇时,存在风险。
- 不同子组的错误率是多少?如果我们没有代表性数据集,我们可能不会注意到我们的算法在某个子组上表现不佳。我们的样本量是否足够大,适用于数据集中的所有子组?重要的是要检查这一点,就像Pro Publica对看过种族的累犯算法所做的那样。
- 简单的基于规则的替代方案的准确性是多少?拥有一个良好的基线非常重要,这应该是我们处理问题时的第一步,因为如果有人询问95%的准确度是否良好,我们需要得到一个答案。正确的答案取决于具体情况。这提出了recidivism算法,它不比两个变量的线性分类器更有效。很高兴知道这个简单的选择是什么。
- 处理上诉或错误的流程是什么?对于影响人们生活的事物,我们需要一个人类诉求程序。作为工程师,我们在公司内部提出这些问题的能力相对较强。
- 建造它的团队有多么多样?构建我们技术的团队应该代表将受其影响的人,这些人越来越多地成为我们所有人。
研究表明,不同的团队表现更好,并且相信我们的精英就会增加偏见。一贯地采访需要时间和精力。对此的一个很好的参考是Julia Evans撰写的题为“ 让小文化发生变化 ” 的博客文章。
先进技术不能替代良好的政策。托马斯谈到了世界各地的快速学生,他们正在深入学习社会问题,如拯救雨林或改善帕金森病患者的护理。
有人工智能法规,如1967年的“年龄歧视和就业法”和相关的“平等信用机会法”。这些并不完美,但比没有任何保护更好,因为我们真的需要考虑我们作为一个社会想要保护的权利。
托马斯在结束她的讲话时说,你永远无法检查偏见。我们可以采取一些步骤来解决问题,但偏见可能会从很多地方渗透。没有清单可以向我们保证偏见已经消失,我们不再需要担心。这是我们一直需要继续关注的事情。
原文:https://www.infoq.com/articles/machine-learning-unconscious-bias
关于作者
 Srini Penchikala目前在德克萨斯州奥斯汀担任高级软件架构师.Penchikala在软件架构,设计和开发方面拥有超过22年的经验。他还是InfoQ的人工智能,ML和数据工程社区的主编,该社区最近发布了他的迷你书籍 - 大数据处理与Apache Spark。他曾在InfoQ,TheServerSide,O'Reilly Network(OnJava),DevX的Java Zone,Java.net和JavaWorld等网站上发表过有关软件架构,安全性,风险管理,NoSQL和大数据的文章。
Srini Penchikala目前在德克萨斯州奥斯汀担任高级软件架构师.Penchikala在软件架构,设计和开发方面拥有超过22年的经验。他还是InfoQ的人工智能,ML和数据工程社区的主编,该社区最近发布了他的迷你书籍 - 大数据处理与Apache Spark。他曾在InfoQ,TheServerSide,O'Reilly Network(OnJava),DevX的Java Zone,Java.net和JavaWorld等网站上发表过有关软件架构,安全性,风险管理,NoSQL和大数据的文章。