【数据异常校验】T检验或T测试(T-test)
目录
历史
使用
假设
未配对和配对的双样本t-test
独立(未配对)样本
配对样本
计算
单样本t检验
回归线的斜率
独立的双样本t检验
替代t-测试位置问题
多变量测试
算法实现
例子
T测试是任何统计假设检验,在这个测试中,测试统计数据遵循一个学生在零假设下的t分布。
T测试最常施加当检验统计量将遵循正态分布如果a的值缩放术语在测试统计量是已知的。当缩放项未知且被基于数据的估计替换时,测试统计(在某些条件下)遵循t分布。该T测试可以使用,例如,以确定是否两组数据是显著彼此不同。
历史
统计是由在1908年推出威廉·西利·戈塞特,化学家的工作吉尼斯啤酒厂在都柏林,爱尔兰。“学生”是他的笔名。
由于Claude Guinness的政策是招聘牛津大学和剑桥大学最优秀的毕业生,将生物化学和统计学应用于吉尼斯的工业流程,因此聘请了Gosset 。Gosset设计了t检验作为监测粗壮品质的经济方法。这项T测试工作已提交给Biometrika期刊并于1908年发表。吉尼斯公司的政策禁止其化学家发表他们的研究结果,因此Gosset以化名“学生”发表了他的统计工作(有关此假名的详细历史记录,请参阅学生的t分布,不得与字面学生混淆)。
吉尼斯有一项政策允许技术人员离开学习(所谓的“学习休假”),戈斯特在1906-1907学年的前两个学期中使用了卡尔皮尔逊教授在伦敦大学学院的生物识别实验室。 Gosset的身份随后为统计学家和主编Karl Pearson所知。
使用
最常用的t- test中有:
- 单样本位置测试,检验群体的均值是否具有零假设中指定的值。
- 零假设的双样本位置检验,使得两个群体的均值相等。所有这些测试通常都被称为学生t测试,但严格来说,只有在假设两个种群的方差相等时才应使用该名称; 当这个假设被删除时使用的测试形式有时被称为Welch的t检验。这些测试通常被称为“不成对”或“独立样本” t-测试,因为它们通常在被比较的两个样本的基础统计单元不重叠时应用。[8]
- 零假设的检验,即在同一统计单位上测量的两个响应之间的差异具有零平均值。例如,假设我们在治疗前后测量癌症患者肿瘤的大小。如果治疗有效,我们预计治疗后许多患者的肿瘤大小会变小。这通常被称为“配对”或“重复测量” t-测试:[8] [9]见配对差异测试。
- 测量回归线的斜率是否与0 显着不同。
假设
大多数t -test统计数据的形式为![]() ,其中Z和s是数据的函数。通常,Z被设计为对备选假设敏感(即,当备选假设为真时其幅度趋于更大),而s是允许确定t的分布的缩放参数。
,其中Z和s是数据的函数。通常,Z被设计为对备选假设敏感(即,当备选假设为真时其幅度趋于更大),而s是允许确定t的分布的缩放参数。
公式:
其中![]() 是样本X 1,X 2,...,X n的样本均值,大小为n,s是均值的标准误差,σ是数据的总体标准差,μ是总体均值。
是样本X 1,X 2,...,X n的样本均值,大小为n,s是均值的标准误差,σ是数据的总体标准差,μ是总体均值。
t检验的假设是
- X遵循具有均值正态分布 μ和方差

 遵循
遵循 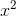 分布与 p 自由度的零假设,其中下 p是一个正的常数
分布与 p 自由度的零假设,其中下 p是一个正的常数- Z和 s是独立的。
在特定类型的t检验中,这些条件是所研究人群的后果,以及数据采样的方式。例如,在比较两个独立样本均值的t检验中,应满足以下假设:
- 被比较的两个群体中的每一个应遵循正态分布。这可以使用常态检验进行测试,例如Shapiro-Wilk或Kolmogorov-Smirnov检验,或者可以使用正态分位数图以图形方式评估。
- 如果使用学生对t检验的原始定义,则比较的两个群体应具有相同的方差(可使用F-test,Levene检验,Bartlett检验或Brown-Forsythe检验检验 ;或使用Q-Q图以图形方式评估)。如果被比较的两组中的样本大小相等,则学生的原始t检验对于存在不等方差非常稳健。无论样本大小是否相似,韦尔奇的t检验对方差的相等性都不敏感。
- 用于进行测试的数据应独立于两个被比较的群体进行抽样。这通常不能从数据中测试,但如果已知数据是依赖性采样的(即,如果它们是以簇的形式采样),那么这里讨论的经典t-测试可能会产生误导性的结果。
大多数双样本t-测试对所有假设都有很大的偏差。
未配对和配对的双样本t-test
双样本t-测试的平均值差异涉及独立样本(未配对样本)或配对样本。配对t-测试是一种阻塞形式,并且当配对单元与“噪声因子”相似时,其比未配对测试具有更大的功率,所述“噪声因子”独立于被比较的两个组中的成员资格。在不同的上下文中,配对t-test可以用来减少的影响混杂因素在观察研究。
独立(未配对)样本
当获得两组独立且相同分布的样本时,使用独立样本t -test ,其中一组来自被比较的两个群体中的每一个。例如,假设我们正在评估医学治疗的效果,我们将100名受试者纳入我们的研究,然后将50名受试者随机分配至治疗组,将50名受试者随机分配至对照组。在这种情况下,我们有两个独立的样本,并将使用未配对的t -test 形式。随机化在这里不是必要的 - 如果我们通过电话联系100个人并获得每个人的年龄和性别,然后使用双样本t检验来确定平均年龄是否因性别而异,这也将是一个独立的样本t- 测试,即使数据是观察性的。
配对样本
配对样本t-测试通常由匹配的相似单元对的样本或已经测试两次的一组单元(“重复测量” t-测试)组成。
重复测量的典型例子t-试验是在治疗前对受试者进行测试,例如高血压,并且在用降血压药物治疗后再次测试相同的受试者。通过比较治疗前后患者的相同数字,我们有效地将每位患者作为自己的对照。这样,对零假设的正确拒绝(这里:治疗没有差异)变得更有可能,统计功率增加仅仅因为现在已经消除了患者之间的随机变异。但请注意,统计功率的增加是有代价的:需要更多的测试,每个主题必须进行两次测试。因为现在一半的样本依赖于另一半,所以学生t -test 的配对版本只有n/2- 1自由度( n是观察总数)。成对成为单独的测试单元,并且样本必须加倍以实现相同数量的自由度。通常,有 n - 1个自由度( n是观察总数)。
基于“匹配对样本” 的配对样本t-测试结果来自未配对样本,其随后用于形成配对样本,通过使用与感兴趣变量一起测量的附加变量。所述的匹配是通过识别对由来自两个样品中的一个的观察,在该对中在其它测量变量方面相似的值的情况下进行。这种方法有时用于观察性研究,以减少或消除混杂因素的影响。
配对样本t-测试通常被称为“依赖样本t-测试”。
计算
下面给出了可用于执行各种t-测试的显式表达式。在每种情况下,给出了在零假设下精确遵循或非常接近t-分布的检验统计量的公式。而且,在每种情况下给出适当的自由度。这些统计数据中的每一个都可用于执行单尾或双尾测试。
一旦t值和自由度被确定,一个p值可以使用找到的值的表,从学生t分布。如果计算的p值低于为统计显着性选择的阈值(通常为0.10,0.05或0.01水平),则拒绝原假设以支持备选假设。
单样本t检验
在测试的零假设总体平均值为等于指定的值![]()
公式
是样本均值,s是样本的样本标准差,n是样本大小。该测试中使用的自由度为n - 1。
虽然父母群体不需要正态分布,但样本群体的分布意味着被认为是正常的。通过中心极限定理,如果父群体的样本是独立的并且父群体的第二矩存在,则样本平均值在大样本极限中将近似正常。(近似程度取决于父母群体与正态分布的接近程度和样本大小n。)
回归线的斜率
假设一个合适模型
其中X是已知的,α和β是未知的,并且ε是均值为0,方差未知正态分布的随机变量![]() ,和ÿ是感兴趣的结果。我们要测试的零假设的斜率β等于某一规定值
,和ÿ是感兴趣的结果。我们要测试的零假设的斜率β等于某一规定值![]() (通常取为0,在这种情况下,零假设是x和y是不相关的)。
(通常取为0,在这种情况下,零假设是x和y是不相关的)。
然后
有一个t分布如果零假设成立,则有n-2自由度的t分布。
斜率系数的标准误差:
可以用残差来写
然后![]() 由下式给出:
由下式给出:
确定![]() 的另一种方法是:
的另一种方法是:
其中r是Pearson相关系数。
所述![]() 可以从被确定
可以从被确定![]()
其中![]() 是样本方差
是样本方差
独立的双样本t检验
等样本大小,方差相等
给定两组(1,2),此测试仅适用于:
- 两个样本大小(即每组参与者的数量n)相等;
- 可以假设这两个分布具有相同的方差;
下面讨论违反这些假设的情况。
测试均值是否不同的t统计量可以计算如下:
其中
这里![]() 是n = n1 = n2和s 2的合并标准偏差
是n = n1 = n2和s 2的合并标准偏差![]() 和
和![]() 是两个样本的方差的无偏估计。 t的分母是两种方法之间差异的标准误差。
是两个样本的方差的无偏估计。 t的分母是两种方法之间差异的标准误差。
对于显着性测试,该测试的自由度为2n-2,其中n是每组中的参与者数量。
样本大小相等或不相等,方差相等
仅当可以假设两个分布具有相同的方差时才使用该测试。(当违反此假设时,请参见下文。)请注意,前面的公式是下面公式的特例,当两个样本的大小相等时,可以恢复它们:n = n 1 = n 2。
测试均值是否不同的t统计量可以计算如下:
其中
是两个样本的汇总标准差的估计量:它以这种方式定义,使得它的平方是公共方差的无偏估计,无论总体均值是否相同。在这些公式中,ni - 1是每组的自由度数,总样本大小减去2(即n1 + n2 - 2)是使用的自由度总数。在重要性测试中。
样本大小相等或不相等,方差不等
该测试也称为Welch t检验,仅在假设两个总体方差相等(两个样本大小可能相同或不相等)时使用,因此必须单独估算。用于测试总体均值是否不同的t统计量计算如下:
其中
这里,![]() 是两个样本中每一个的方差的无偏估计,其中ni = 组i中的参与者数量(1或2)。
是两个样本中每一个的方差的无偏估计,其中ni = 组i中的参与者数量(1或2)。
注意,在这种情况下,s2不是一个集合方差。为了在测试中使用,测试统计数据的分布近似为普通学生的t分布和使用的自由度
这被称为Welch-Satterthwaite方程。测试统计量的真实分布实际上(略微)取决于两个未知的人口差异(参见Behrens-Fisher问题)。
配对样本的相关t检验
当样品依赖时使用该测试; 也就是说,当只有一个样本经过两次测试(重复测量)或者有两个样本已经匹配或“配对”时。这是配对差异测试的一个例子。
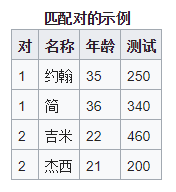
对于此等式,必须计算所有对之间的差异。这些对是一个人的测试前和测试后的分数,或者是一对匹配成有意义的组的人(例如,来自相同的家庭或年龄组:见表)。这些差异的平均值(![]() )和标准偏差(
)和标准偏差(![]() )用于等式中。恒定
)用于等式中。恒定![]() 是非零值,如果我们要测试的差的平均值是否是从显著不同
是非零值,如果我们要测试的差的平均值是否是从显著不同![]() 。使用的自由度是n -1,其中n表示对的数量。
。使用的自由度是n -1,其中n表示对的数量。
替代t-测试位置问题
所述吨 -test提供两个正态总体与未知的,但是相等时,方差的装置的一个平等精确检验。(对于数据正常但差异可能不同的情况,Welch的t检验几乎是一个非常精确的检验。)对于中等大样本和单尾检验,t检验对于适度违反正态假设是相对稳健的。
对于正确性,所述t -test和z -test要求样品的正常装置,并且t -test另外需要,对于样本方差如下缩放的χ 2分布,并且所述样本均值和样本方差是统计独立的。如果满足这些条件,则不需要单个数据值的正常性。通过中心极限定理,即使数据不是正态分布,中等大样本的样本均值通常也能通过正态分布很好地近似。对于非正常的数据,样本方差的分布可以从基本上偏离χ 2分配。但是,如果样本量很大,Slutsky定理意味着样本方差的分布对检验统计量的分布几乎没有影响。如果数据基本上不正常且样本量很小,则t检验可能会产生误导性结果。有关与一个特定非正态分布族相关的理论,请参阅高斯尺度混合分布的位置测试。
当常态假设不成立时,t检验的非参数替代通常可以具有更好的统计功效。类似地,在存在异常值的情况下,t检验不稳健。例如,对于两个独立的样本,当数据分布是不对称的(即,分布是偏斜的)或分布有大尾巴时,那么Wilcoxon秩和检验(也称为Mann-Whitney U检验)可以有三个功率比t测试高四倍。配对样本的非参数对应物t-test是配对样本的Wilcoxon符号秩检验。有关在t -test和非参数选择之间进行选择的讨论,请参见Sawilowsky(2005)。
单向方差分析(ANOVA)概括了两样本吨当数据属于两个以上的组-test。
多变量测试
Student's t统计量的推广,称为Hotelling的t-平方统计量,允许在同一样本中测试多个(通常是相关的)度量的假设。例如,研究人员可能会将一些科目提交给由多个人格量表组成的人格测验(例如明尼苏达多相人格量表)。由于这种类型的度量通常是正相关的,因此不建议单独进行单变量t检验以检验假设,因为这些会忽略度量之间的协方差,并且会增加错误拒绝至少一个假设的可能性(类型I错误))。在这种情况下,单个多变量检验对于假设检验更为可取。Fisher's方法将多个测试与α相结合,减少了测试之间的正相关性。另一个是Hotelling的![]() 统计量遵循
统计量遵循![]() 分布。但是,实际上很少使用分布,因为很难找到
分布。但是,实际上很少使用分布,因为很难找到![]() 的列表值。通常,
的列表值。通常,![]() 被转换为F统计量。
被转换为F统计量。
对于一示例多变量测试中,假设是平均向量(μ)是等于给定的矢量(![]() )。测试统计数据是Hotelling的t 2:
)。测试统计数据是Hotelling的t 2:
其中n是样本大小,![]() 是列均值的向量,S是m × m 样本协方差矩阵。
是列均值的向量,S是m × m 样本协方差矩阵。
对于两样品多元测试中,假设是均值向量(![]() ,
,![]() )的两个样品是相等的。测试统计数据是Hotelling的双样本t 2:
)的两个样品是相等的。测试统计数据是Hotelling的双样本t 2:
算法实现
python的科学计算库scipy中的函数
scipy.stats.ttest_ind(a, b, axis=0, equal_var=True)
计算两个独立分数样本均值的T检验。
这是零假设的双侧检验,即2个独立样本具有相同的平均(预期)值。该测试假设群体默认具有相同的方差。
| 参数: | a,b : array_like 除了与轴对应的维度(默认情况下为第一个)外,数组必须具有相同的形状。 axis : int或None,可选 用于计算测试的轴。如果为None,则计算整个数组a和b。 equal_var : bool,可选 如果为True(默认值),则执行标准的独立2样本检验,该检验假设人口差异相等[1]。如果为False,则执行Welch的t检验,该检验不假设人口方差相等[2]。 版本0.11.0中的新功能。 nan_policy : {'propagate','raise','omit'},可选 定义输入包含nan时的处理方式。'propagate'返回nan,'raise'抛出错误,'省略'执行忽略nan值的计算。默认为'传播'。 |
|---|---|
| 返回: | statistic : 浮点数或数组 计算出的t统计量。 pvalue : float或array 双尾p值。 |
例子
from scipy import stats
np.random.seed(12345678)用相同的方法测试样品:
rvs1 = stats.norm.rvs(loc=5,scale=10,size=500)
rvs2 = stats.norm.rvs(loc=5,scale=10,size=500)
stats.ttest_ind(rvs1,rvs2)
#(0.26833823296239279, 0.78849443369564776)
stats.ttest_ind(rvs1,rvs2, equal_var = False)
#(0.26833823296239279, 0.78849452749500748)ttest_ind 低估了不等方差的p:
rvs3 = stats.norm.rvs(loc=5, scale=20, size=500)
stats.ttest_ind(rvs1, rvs3)
#(-0.46580283298287162, 0.64145827413436174)
stats.ttest_ind(rvs1, rvs3, equal_var = False)
#(-0.46580283298287162, 0.64149646246569292)当n1!= n2时,等方差t-统计量不再等于不等方差t-统计量:
rvs4 = stats.norm.rvs(loc=5, scale=20, size=100)
stats.ttest_ind(rvs1, rvs4)
#(-0.99882539442782481, 0.3182832709103896)
stats.ttest_ind(rvs1, rvs4, equal_var = False)
#(-0.69712570584654099, 0.48716927725402048)使用不同均值,方差和n进行T检验:
rvs5 = stats.norm.rvs(loc=8, scale=20, size=100)
stats.ttest_ind(rvs1, rvs5)
#(-1.4679669854490653, 0.14263895620529152)
stats.ttest_ind(rvs1, rvs5, equal_var = False)
#(-0.94365973617132992, 0.34744170334794122)
参考:
https://en.wikipedia.org/wiki/Student%27s_t-test
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html#scipy.stats.ttest_ind