Python网络爬虫与信息提取-Day6-Beautiful Soup库
安装Beautiful Soup库:
pip install beautifulsoup4
Beautiful Soup库的安装小测
演示HTML页面地址:http://python123.io/ws/demo.html
1.手工获得HTML源代码
打开浏览器,右键点击“查看源文件”
2.利用requests库
import requests
r = requests.get(“http://python123.io/ws/demo.html”)
r.text
demo = r.text
Beautiful Soup库安装小测
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,“html.parser”)
print(soup.prettify())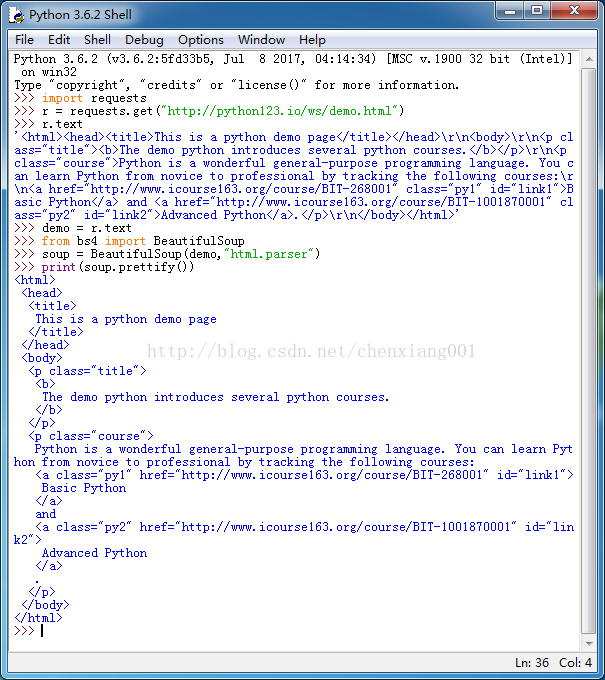
from bs4 import BeautifulSoup
soup = BeautifulSoup(‘data
’,“html.parser”)Beautiful Soup库的基本元素
HTML文件<==>标签树
…
Beautiful Soup库是解析、遍历、维护“标签树”的功能库
…
…
名称Name,成对出现
属性Attributes,0个或多个
Beautiful Soup库,也叫beautifulsoup4或bs4
约定引用方式如下,即主要是用BeautifulSoup类
from bs4 import BeautifulSoup
import bs4HTML文件<==>标签树<==>BeautifulSoup类
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("data","html.parser")
>>> soup2 = BeautifulSoup(open("D://demo.html"),"html.parser")
Beautiful Soup库解析器
soup = BeautifulSoup("data","html.parser")
| 解析器 |
使用方法 |
条件 |
| bs4的HTML解析器 |
BeautifulSoup(mk,'html.parser') |
安装bs4库 |
| lxml的HTML解析器 |
BeautifulSoup(mk,'lxml') |
pip install lxml |
| lxml的XML解析器 |
BeautifulSoup(mk,'xml') |
pip install lxml |
| html5lib的解析器 |
BeautifulSoup(mk,'html5lib') |
pip install html5lib |
BeautifulSoup类的基本元素
(1)Tag 标签
最基本的信息组织单元,分别用<>和标明开头和结尾
任何存在于HTML语法中的标签都可以用soup.
当HTML文档中存在多个相同
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.title
>>> tag = soup.a
>>> tag
(2)Tag的name(名字)
…
每个
>>> soup.a.name
'a'
>>> soup.a.parent.name
'p'
>>> soup.a.parent.parent.name
'body'
(3)Tag的attrs(属性)
字典形式组织,格式:
一个
>>> tag = soup.a
>>> tag.attrs
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
>>> tag.attrs['class']
['py1']
>>> tag.attrs['href']
'http://www.icourse163.org/course/BIT-268001'
>>> type(tag.attrs)
>>> type(tag)
(4)Tag的NavigableString
标签内非属性字符串,<>…中字符串,格式:
>>> soup.a
>>> soup.a.string
'Basic Python'
>>> soup.p
The demo python introduces several python courses.
>>> soup.p.string
'The demo python introduces several python courses.'
>>> type(soup.p.string)
NavigableString可以跨越多个层次
(5)Tag的Comment
标签内字符串的注释部分,一种特殊的Comment类型
>>> newsoup = BeautifulSoup(" This is not a comment
>>> newsoup.b.string
'This is a comment'
>>> type(newsoup.b.string)
>>> newsoup.p.string
'This is not a comment'
>>> type(newsoup.p.string)