Python网络爬虫与信息提取-Day8-基于bs4库的HTML格式输出
能否让HTML内容更加“友好”的显示?
bs4库的prettify()方法
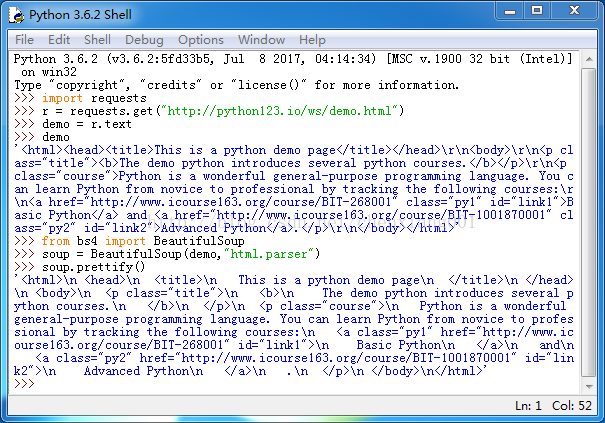
它在每个后面增加了换行符,将其打印出来

.prettify()为HTML文本<>及其内容增加更加'\n'
.prettify()可用于标签,方法:
>>> print(soup.a.prettify())
Basic Python
>>>
bs4库的编码
bs4库将任何HTML输入都变成utf‐8编码
Python 3.x默认支持编码是utf‐8,解析无障碍
>>> soup = BeautifulSoup("
中文
","html.parser")>>> soup.p.string
'中文'
>>> print(soup.p.prettify())
中文