Python网络爬虫:利用pyquery进行‘豆瓣图书’中‘新书速递’条目爬取
前面学习了正则表达式、BeautifulSoup方法的网络爬取方式,本次学习使用pyquery方法的爬取,爬取内容同之前的博客(参考我之前的博客:https://blog.csdn.net/ChenXvYuan_001/article/details/82421955),这里不再赘述。
我的体会是pyquery有些类似之前的BeautifulSoup方法,同样是利用一些方法进行爬取,而且利用到了标签的关键字(li、p、ul等),不同的是,BS配合解析器(eg:lxml)使用,而pyquery则可以直接利用一些方法,直接进行爬取,貌似如果有jquery的基础(虽然我没有…),学习pyquery会很容易上手…
今天太晚了,实验室几乎没人了,不多说了,直接贴代码和爬取结果:
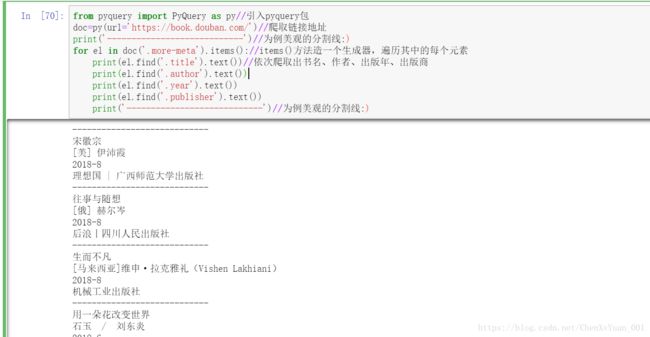
from pyquery import PyQuery as py//引入pyquery包
doc=py(url='https://book.douban.com/')//爬取链接地址
print('----------------------------')//为例美观的分割线:)
for el in doc('.more-meta').items()://items()方法造一个生成器,遍历其中的每个元素
print(el.find('.title').text())//依次爬取出书名、作者、出版年、出版商
print(el.find('.author').text())
print(el.find('.year').text())
print(el.find('.publisher').text())
print('----------------------------')//为例美观的分割线:)爬取结果:
先这样,之后再总结。。。。。