Python网络爬虫:利用正则表达式爬取豆瓣电影top250排行前10页电影信息
在学习了几个常用的爬取包方法后,转入爬取实战。
爬取豆瓣电影早已是练习爬取的常用方式了,网上各种代码也已经很多了,我可能现在还在做这个都太土了,不过没事,毕竟我也才刚入门……
这次我还是利用正则表达式进行爬取,怎么说呢,有人说写正则表达式很麻烦,很多人都不愿意用正则表达式了,不过正则表达式是我第一个学习的爬取方式,也是我最有感觉的一种方法了,我也喜爱用这种方法,当然我现在的正则表达式写的肯定还不是很漂亮、精简,这个以后再去精益求精吧,当然,这里的正则表达式也是我自己写的,可能会有点丑,大家可以再去完善吧
言归正传,我这次爬取了豆瓣电影排行top250,共爬取了10页电影信息,并将这些爬取信息进行简单的数据清洗,最后写入一个本地的txt文件中。
其实我的这段代码可以爬取任意页数的电影信息,换句话说这里的10可以随心所欲的改,想爬多少是多少(我想这也是爬虫的魅力所在啊),当然当然肯定不能超过上限啦~
话不多说啦,上我的码,这个码可真的是原创啊,自己写的,尤其是正则表达式,改了很多次才有这个结果哦~坚决不做代码搬运工哦~
import requests
import re
p=0//打印页码
with open('mov.txt','w',encoding='utf-8') as f://写入名为mov的txt文件,由于我的文件默认是GBK,所以这里转为utf-8
for i in range(10)://这里抓取前10页
url='https://movie.douban.com/top250?start='+str(i*25)//翻页循环设置:通过对start赋值以25的倍数
html=requests.get(url).text
pattern=re.compile('(.*?) .*?(.*?); (.*?)
(.*?) / (.*?) / (.*?).*?average">(.*?).*?inq">(.*?).*?',re.S)//正则表达式的书写
results=re.findall(pattern,html)
print(results)//打印了一下
list=str(results)
for st in results://由于结果为以元组为元素的列表,每个元组又包含6个元素,分别进行打印,同时运用strip()进行数据清洗,再加上换行符进行格式化存储
f.write(st[0]+'\n'+st[1].strip()+'\n'+st[2]+'\n'+st[3].strip()+'\n'+st[4]+'\n'+st[5].strip()+'\n'+'评分:'+st[6]+'\n--*---*---*---\n')
f.close() 打开txt:
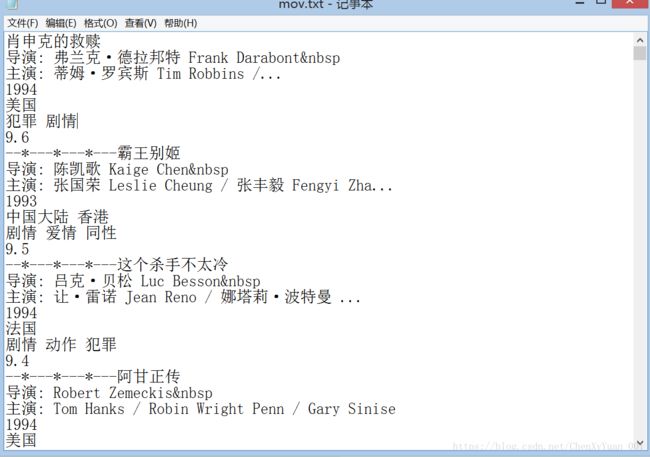
最后还要附一个知识点:
我把爬取结果写入txt文件里,由于新文件的默认编码是gbk,这样的话,python解释器会用gbk编码去解析我们的网络数据流txt,然而txt此时已经是decode过的unicode编码,这样的话就会导致解析不了,出现上述问题。 解决的办法就是,改变目标文件的编码:
复制代码代码如下:
f = open(“out.html”,”w”,encoding=’utf-8’)
注:参考自博客园https://www.cnblogs.com/themost/p/6603409.html
谢谢这篇对我们学习很有用的博客,希望我的博客也能在之后,哪怕是某个深夜,对某颗求学的心,起到一点点帮助……….加油↖(^ω^)↗