TensorFlow之Keras, TensorLayer, Tflearn库比较【转】
来自:http://blog.csdn.net/dhsig552/article/details/52319541
TensorFlow 是非常强大的分布式跨平台深度学习框架;
因此,我们有必要比较一下基于 TensorFlow 开发的三个库 :Keras, TensorLayer, Tflearn
Keras:是这三个库中最早发布的,最开始只支持 Theano,16年初开始同时支持 Theano 和 TensorFlow 。它的优点是提供傻瓜式编程风格,一分钟可以上手。
有中英文文档。
缺点是框架封闭太死,难以自定义,比如 Activation 的设置是输入string来实现的,而TensorLayer是直接输入function,这样自定义 function 时非常方便。
model = Sequential()
model.add(Dropout(0.2, input_shape=(784,)))
model.add(Dense(800))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(800))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))TensorLayer:是16年中发布的,相对较晚但也较为先进。它的优点是速度最快,速度和完全用 TensorFlow 写的代码一样。
同时提供傻瓜式编程方法,和专业级编程方法。参考:tutorial_mnist_simple.py tutorial_mnist.py
提供很多高级功能,适合分布式和嵌入式应用,如:variable reuse ,same model to npz file,GPU manager 等等。
提供大量官方教程,包含了 TensorFlow 官方所有深度学习教程的模块化实现,集合教学和编程于一体。
有中英文文档。
缺点是发布较晚,16年6月前只限作者的学校内部使用,所以现在才开始积累用户。
network = tl.layers.InputLayer(x, name='input_layer')
network = tl.layers.DropoutLayer(network, keep=0.8, name='drop1')
network = tl.layers.DenseLayer(network, n_units=800,
act = tf.nn.relu, name='relu1')
network = tl.layers.DropoutLayer(network, keep=0.5, name='drop2')
network = tl.layers.DenseLayer(network, n_units=800,
act = tf.nn.relu, name='relu2')
network = tl.layers.DropoutLayer(network, keep=0.5, name='drop3')
network = tl.layers.DenseLayer(network, n_units=10,
act = tl.activation.identity,
name='output_layer')Tflearn:的作者在陌陌工作,亮点和keras一样,都提供傻瓜式编程方法,但由相比Keras透明,所以运行速度比Keras快。
缺点是不支持 Seq2seq,高级应用没法做。。这个bug比较大,希望尽快修复。
input_layer = tflearn.input_data(shape=[None, 784])
dropout1 = tflearn.dropout(input_layer, 0.8)
dense1 = tflearn.fully_connected(input_layer, 800, activation='relu',
regularizer='L2', weight_decay=0.0)
dropout2 = tflearn.dropout(dense1, 0.5)
dense2 = tflearn.fully_connected(dropout1, 800, activation='relu',
regularizer='L2', weight_decay=0.0)
dropout3 = tflearn.dropout(dense2, 0.5)
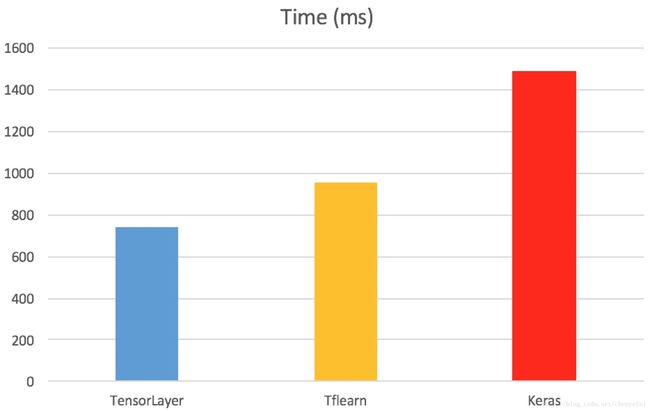
softmax = tflearn.fully_connected(dropout3, 10, activation='softmax')最后列出这三个库,分别用上面同样的多层神经网络训练MNIST时,每个epoch的耗时,可见 TensorLayer 的速度快了不少,比Keras差不多快了一倍,这可能是因为Keras需要同时支持 Theano 和 TensorFlow 导致的。
设置:单个 GTX 980 GPU, CUDA 7.5 , cuDNN 5,batch_size = 500