Java JDK1.8 核心特性详解------Stream进阶
在前面的章节(Java JDK1.8 核心特性详解------Stream(流)的使用),我对Stream流中的中间操作 筛选、映射、查找、匹配、归约等基本功能进行了介绍,在下面这篇文章里,我们会介绍流的终端操作,包括归约,汇总,分组,分区,以及如何自己定义Collector接口
用流收集数据
在前面的例子中,我们把数据通过流进行过滤,匹配,和映射,最后使用终端操作得到值,体验到流对我们处理数据在某种程度上有很大的帮助。但之间的学习的都是中间操作,在本章中,你将学习如何让使用collect对数据进行最后的处理。最后,你会发现collect是一个归约操作,通过接受不同的做法作为参数,对流进行处理。具体做法是接收不同实现的Collector接口来定义。下面举个例子感受一下流收集数据的好处:
List menu = Arrays.asList(
//参数分别为食物名称,是否是蔬菜,卡路里,食物类型
new Dish("猪肉", false, 800, "肉"),
new Dish("牛肉", false, 700, "肉"),
new Dish("鸡肉", false, 400, "肉"),
new Dish("虾", false, 300, "鱼"),
new Dish("三文鱼", false, 450, "鱼"),
new Dish("米饭", false, 350, "其他"),
new Dish("蔬菜", true, 530, "其他"),
new Dish("水果", true, 120, "其他"),
new Dish("披萨", true, 550, "其他"));
//根据食物type进行分组
//普通做法
Map> groupByType = new HashMap<>();
for (Dish dish : menu) {
String type = dish.getType();
List dishes = groupByType.get(type);
if (dishes == null) {
dishes = new ArrayList<>();
groupByType.put(type, dishes);
}
dishes.add(dish);
}
//使用流
Map> collect = menu.stream().collect(groupingBy(Dish::getType));
System.out.println(collect);
--------------------------------------------------------------------
{肉=[Dish(name=猪肉, vegetarian=false, calories=800, type=肉), Dish(name=牛肉, vegetarian=false, calories=700, type=肉), Dish(name=鸡肉, vegetarian=false, calories=400, type=肉)], 其他=[Dish(name=米饭, vegetarian=false, calories=350, type=其他), Dish(name=蔬菜, vegetarian=true, calories=530, type=其他), Dish(name=水果, vegetarian=true, calories=120, type=其他), Dish(name=披萨, vegetarian=true, calories=550, type=其他)], 鱼=[Dish(name=虾, vegetarian=false, calories=300, type=鱼), Dish(name=三文鱼, vegetarian=false, calories=450, type=鱼)]}
我们可以看到,使用流给我们提前定义好的 Collectors.groupingBy()方法,可以快速帮助我们对数据进行最后的处理。
流的收集器
前面的例子展示了函数式变成(流)对于指令式编程(JDK1.8以前的写法)的一个主要优势:你只需要指出希望的结果---“做什么”,而不用操心具体的步骤---“怎么做”。传给collect的参数是Collector的一个实现,就是给Stream中的元素做汇总的方法。
收集器可以通过简洁而又灵活定义的collect对流中的元素进行操作。在下面,我们会介绍JDK1.8给我们提供的收集器功能,也就是从Collectors类提供的工厂方法。它们主要提供了三大功能:
1、将元素进行归约和汇总为一个值
2、元素分组
3、元素分区
归约和汇总
归约
归约是最常用的方法之一,在以前的例子中我们经常使用 toList() 方法,将流中的元素归约为一个集合。除此之外,我们可以使用 counting() 统计流中元素的数量:
//统计mean菜单中有多少菜
Long howManyDishes = menu.stream().collect(counting());
//与上面的方法效果相同
Long howManyDishes2 = menu.stream().count();当我们想查询流中的最大值或最小值时,我们可以使用maxBy()或者minBy()方法,maxBy()和minBy()接收一个Comparator参数来比较流中的元素:
//查找卡路里最大的菜
Optional max = menu.stream().collect(maxBy(Comparator.comparingInt(Dish::getCalories)));
//查找卡路里最小的菜
Optional min = menu.stream().collect(minBy(Comparator.comparingInt(Dish::getCalories))); 汇总
Collectors专门为汇总提供了一系列的工厂方法。当我们要对流中的元素进行求和时,可以使用 summingInt()进行计算。需要求平均数时可以使用 averagingInt()进行计算。
//计算全部菜的卡路里总和
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
//计算全部菜的卡路里平均值
double averageCalories = menu.stream().collect(averagingInt(Dish::getCalories));如果你想一次性获得流中数据的max,min,sum,count和average,可以直接使用summarizingInt(),这个方法会返回一个IntSummaryStatistics类,这个类包含了max,min,sum,count和average的值,同时提供了get方法让我们获取这个值:
IntSummaryStatistics collect = menu.stream().collect(summarizingInt(Dish::getCalories));
System.out.println(collect);
---------------------------------------------------------------------
IntSummaryStatistics{count=9, sum=4200, min=120, average=466.666667, max=800}广义的归约汇总
事实上,我们刚刚讨论的所有收集器,都可以用reducing工厂方法的特殊实现。可以说,Collectors.reducing是归约的一般化。例如:
//计算全部菜的卡路里总和
int totalCalories = menu.stream().collect(summingInt(Dish::getCalories));
//与上面方法是等效的
int totalCalories2 = menu.stream().collect(reducing(0, Dish::getCalories, (i, j) -> i + j));
//第二种方法的简写
int totalCalories3 = menu.stream().collect(reducing(0, Dish::getCalories, Integer::sum));
reducing工厂方法的归约流程:
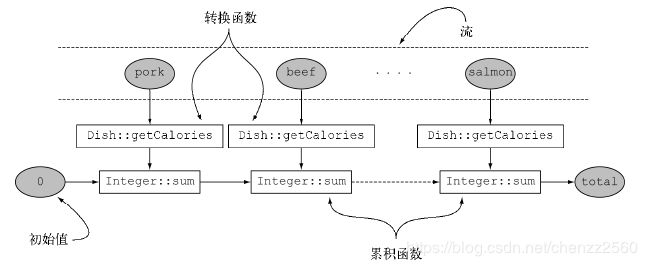
一般来说,函数式编程提供了多种方法来执行同一个操作,例如上面的统计卡路里,还有其他的方式实现。我们应该尽可能的发现不同的解决方法,然后选择最合适的方法(可读性和性能):
//方法四
int totalCalories3 = menu.stream().map(Dish::getCalories).reduce(0, Integer::sum);
//方法五
int totalCalories4 = menu.stream().map(Dish::getCalories).reduce( Integer::sum).get();
//方法六-推荐方法,因为减少了拆装箱的成本
int totalCalories5 = menu.stream().mapToInt(Dish::getCalories).sum();分组
正如前面的例子描述,将菜单中的菜根据类型进行分组,如果使用指令式方法,会很麻烦,同时也容易出错。但是使用Colltctors.groupingBy()工厂方法,很方便的就完成这个任务。在这里,你给grouping方法通过方法引用的方式,传递了一个Function(分类函数)。Function提取了流中每个Dish的type,并将流中元素分组。
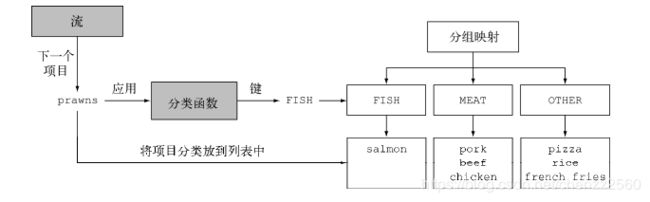
除了方法引用,还可以用更加复杂的条件对数据进行分类。例如,我们要通过卡路里的含量将食物分成低热量(diet),普通(normal),高热量(fat),虽然我们无法使用方法引用,但是可以把这个逻辑写成Lambda表达式:
Map> collect = menu.stream().collect(groupingBy(dish -> {
if (dish.getCalories() <= 400) {
return "DIET";
} else if (dish.getCalories() <= 700) {
return "NORMAL";
} else {
return "FAT";
}
})); 多级分组
上面只是显示一次分组,往往我们需要多次分组,例如先对食物的类型进行分组,然后再在类型分组的基础上,根据食物的卡路里进行分组,依然可以通过groupingBy完成,groupingBy存在一个重载的版本,接受Function和collector类型参数。例子如下:
Map>> collect = menu.stream().collect(
//根据type进行一级分类
groupingBy(Dish::getType,
//根据卡路里进行二级分类
groupingBy(dish -> {
if (dish.getCalories() <= 400) {
return "DIET";
} else if (dish.getCalories() <= 700) {
return "NORMAL";
} else {
return "FAT";
}
})));
System.out.println(collect);
---------------------------------------------------------------------------
分类后结果:
{肉={DIET=[Dish(name=鸡肉, vegetarian=false, calories=400, type=肉)],
FAT=[Dish(name=猪肉, vegetarian=false, calories=800, type=肉)],
NORMAL=[Dish(name=牛肉, vegetarian=false, calories=700, type=肉)
]},
其他={
DIET=[Dish(name=米饭, vegetarian=false, calories=350, type=其他), Dish(name=水果, vegetarian=true, calories=120, type=其他)],
NORMAL=[Dish(name=蔬菜, vegetarian=true, calories=530, type=其他), Dish(name=披萨, vegetarian=true, calories=550, type=其他)
]},
鱼={
DIET=[Dish(name=虾, vegetarian=false, calories=300, type=鱼)],
NORMAL=[Dish(name=三文鱼, vegetarian=false, calories=450, type=鱼)]}}
如果你想进行更多级的分类,可以按照上面的方式,在groupingBy中进行多层的嵌套。
按子组收集数据
上面的例子是如何将数据分组,但是对数据本身是没有影响的。有时候,我们需要将数据分组以后对数据进行处理,例如求和,求平均等。groupingBy依然提供了方法让我们完成需求。例如,我们要计算每类菜有多少个:
Map collect = menu.stream().collect(groupingBy(Dish::getType, counting()));
System.out.println(collect);
-----------------------------------------------------
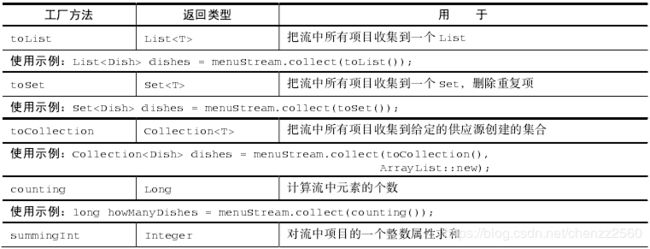
{肉=3, 其他=4, 鱼=2} 在groupingBy()的第二个参数中,我们基本上可以使用Collectors中提供的所有方法。例如summingInt(),counting()等。事实上,groupingBy(f)是groupingBy(f,toList())的简便写法。下面提供Collectors类的静态工厂方法:

Collector接口
JDK1.8提供了Collector接口,我们可以通过实现这个接口,自定义需要的收集器。这样有两个好处。第一:在需要时实现自己的收集器。第二:自己定义的收集器可以自行优化,得到性能上的提升。具体如何编写由于自己水平有限,建议参考《Java 8 实战》6.5节以及6.6节相关内容。