机器学习算法 -- 集成学习
一、关于集成学习的概念
1.集成学习概念
集成学习是机器学习中一个非常重要且热门的分支,是用多个弱分类器构成一个强分类器,其哲学思想是“三个臭皮匠赛过诸葛亮”。一般的弱分类器可以由决策树,神经网络,贝叶斯分类器,K-近邻等构成。已经有学者理论上证明了集成学习的思想是可以提高分类器的性能的,比如说统计上的原因,计算上的原因以及表示上的原因。
2. 为什么要集成
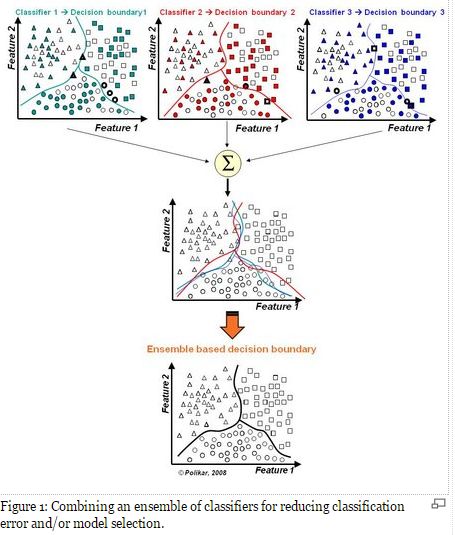
1)模型选择
假设各弱分类器间具有一定差异性(如不同的算法,或相同算法不同参数配置),这会导致生成的分类决策边界不同,也就是说它们在决策时会犯不同的错误。将它们结合后能得到更合理的边界,减少整体错误,实现更好的分类效果。
2) 数据集过大或过小
数据集较大时,可以分为不同的子集,分别进行训练,然后再合成分类器。
数据集过小时,可使用自举技术(bootstrapping),从原样本集有放回的抽取m个子集,训练m个分类器,进行集成。
3)分治
若决策边界过于复杂,则线性模型不能很好地描述真实情况。因此先训练多个线性分类器,再将它们集成。
4)数据融合(Data Fusion)
当有多个不同数据源,且每个数据源的特征集抽取方法都不同时(异构的特征集),需要分别训练分类器然后再集成
3 集成学习常用算法
1)boosting的弱分类器形成是同一种机器学习算法,只是其数据抽取时的权值在不断更新,每次都是提高前一次分错了的数据集的权值,最后得到T个弱分类器,且分类器的权值也跟其中间结果的数据有关。
2)Bagging算法也是用的同一种弱分类器,其数据的来源是用bootstrap算法得到的(有放回抽样,一个instance被前面分错的越厉害,它的概率就被设的越高)。
3)Stacking算法分为两个阶段,首先我们使用多个基础分类器来预测分类;然后,一个新的学习模块与它们的预测结果结合起来,来降低泛化误差。
4 集成学习有效的前提
1)每个弱分类器的错误率不能高于0.5
2)弱分类器之间的性能要有较大的差别,否则集成效果不是很好
5 集成学习分类
集成学习按照基本分类器之间的关系可以分为异态集成学习和同态集成学习。异态集成学习是指弱分类器之间本身不同,而同态集成学习是指弱分类器之间本身相同只是参数不同。
- 不同算法的集成
- 同一种算法在不同设置下的集成
- 数据集的不同部分分配给不同分类器之后的集成
6. 基本分类器之间的整合方式
简单投票,贝叶斯投票,基于D-S证据理论的整合,基于不同的特征子集的整合
二、Boosting中代表性算法Adaboost元算法/集成算法
1. AdaBoost元算法
基于数据集多重抽样的分类器
- Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)
- Adaboost算法本身是通过改变数据权值分布来实现的,它根据每次训练集中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据送给下层分类器进行训练,最后将每次得到的分类器最后融合起来,作为最后的决策分类器
- 关于弱分类器的组合,Adaboost算法采用加权多数表决的方法。具体来说,就是加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率较大的弱分类器的权值,使其在表决中起较小的作用
2.Adaboost算法思路
输入:
分类数据;弱算法数组
输出:
分类结果
流程:
- Step1 给训练数据集中的每一个样本赋予权重,权重初始化相等值,这些权重形成向量D。一般初始化所有训练样例的权重为1 / N,其中N是样例数
- Step2 在训练集上训练出弱分类器并计算该分类器的错误率
- Step3 同一数据集上再次训练分类器,调整样本的权重,将第一次分对的样本权重降低,第一次分错的样本权重提高
- Step4 最后给每一个分类器分配一个权重值alpha,alpha = 0.5*ln((1-错误率)/错误率)
- Step5 计算出alpha值后,可以对权重向量D进行更新,以使得正确分类的样本权重降低而错分样本的权重升高。

计算出D之后,AdaBoost又开始进入下一轮迭代。Adaboost算法会不断地重复训练和调整权重的过程,知道训练错误率为0或者弱分类器的数目达到用户指定的值为止

3. Adaboost算法核心思想
“关注”被错分的样本,“器重”性能好的弱分类器
- 不同的训练集调整样本权重
- “关注”增加错分样本权重
- “器重”好的分类器权重大
- 样本权重间接影响分类器权重
4. Adaboost 算法优缺点
优点:
1)Adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的,而弱分类器构造及其简单
4)简单,不用做特征筛选
5)不用担心overfitting(过拟合)问题
5. Adaboost算法应用场景
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline–无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正–只需要增加新的分类器,不需要变动原有分类器
6. Adaboost 算法Python实现
#Import Library
from sklearn.ensemble import GradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)三、Boosting算法中代表性算法GBDT
1.GBDT
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。
2. GBDT主要由三个概念组成:
- Regression Decision Tree(及DT 回归决策树)
- Gradient Boosting(即GB)
- Shrinkage(算法的一个重要演进分枝)
1) DT:回归树Regression Decision Tree
回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差–即(每个人的年龄-预测年龄)^2 的总和 / N,或者说是每个人的预测误差平方和 除以 N。
2) GB:梯度迭代 Gradient Boosting
Boosting,迭代,即通过迭代多棵树来共同决策。
GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义。