Python 网络爬虫学习(一)
最近在学习一些Python网络爬虫的东西,现将所学习内容整理如下,希望与大家相互交流,共同进步。
一、网络爬虫基本概念
1.网络爬虫(Web Spider)
是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。这样看来,网络爬虫就是一个爬行程序,一个抓取网页的程序。
2.浏览网页的过程
打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了 一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。
HTML是一种标记语言,用标签标记内容并加以解析和区分。浏览器的功能是将获取到的HTML代码进行解析,然后将原始的代码转变成我们直接看到的网站页面。
3.网络爬虫的基本工作流程
1) 首先选取一部分精心挑选的种子URL;
2) 将这些URL放入待抓取URL队列;
3) 从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.一个简单的例子
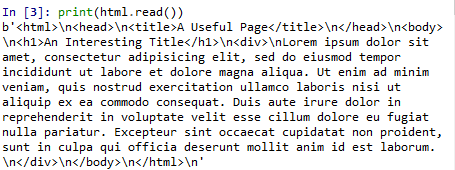
from urllib.request import urlopen
html = urlopen("http://pythonscraping.com/pages/page1.html")
print(html.read())
二、BeautifulSoup
1.BeautifulSoup通过定位HTML标签来格式化和组织复杂的网络信息,用简单易用的Python对象为我们展现XML结构信息。
简单使用实例如下:
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page1.html")
bsObj = BeautifulSoup(html)
print(bsObj.h1)
#Output: An Interesting Title
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
bsObj = BeautifulSoup(html)
nameList = bsObj.findAll("span",{"class":"green"})
# bsObj.findall(tagname,tagAttributes)获取页面中所有指定的标签
for name in nameList:
print(name.get_text()) #打印内容
#get_text()会将HTML文档中所有的标签都清除,剩下一串不带标签的文字
2.BeautifulSoup库中常用对象
- BeautifulSoup对象
- 标签Tag对象
- NabigableString对象(用来表示标签中的文字)
- Comment对象(用来查找HTML文档红的注释标签)
3.导航树
1)处理子标签与后代标签
子标签:父标签的下一级 .children
后代标签:一个父标签下面所有级别的标签
一般来说,BeautifulSoup函数总是处理当前标签的后代标签。 .descendent
2)处理兄弟标签
next_siblings
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)
print("===========")选择标签行,然后调用next_siblings,可以选择表格中除了标题行以外的所有行
4.正则表达式和BeautifulSoup
import re
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
images = bsObj.findAll("img",{"src":re.compile("\.\.\/img\/gifts\/img.*\.jpg")})
for image in images:
print(image["src"])
三、采集动态网站
1.遍历单个域名—获取wiki中词条链接
总结wiki词条链接的特点:
- 在id是bodyContent的div标签里
- URL链接不包含冒号
- URL链接都是以/wiki/开头
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html)
for link in bsObj.find("div",{"id":"bodyContent"}).findAll("a",href=re.compile("^(/wiki/)((?!:).)*$")):
if 'href' in link.attrs:
print(link.attrs['href'])
2.动态爬取wiki上词条链接
在wiki网站上随机地从一个链接跳到另一个链接
random.seed(datetime.datetime.now()) #伪随机数,伪随种子
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org"+articleUrl)
bsObj = BeautifulSoup(html,"lxml")
return bsObj.find("div",{"id":"bodyContent"}).findAll("a",
href=re.compile("^(/wiki/)((?!:).)*$"))
links = getLinks("/wiki/Kevin_Bacon")
while len(links) > 0:
newArticle = links[random.randint(0,len(links)-1)].attrs["href"]
print(newArticle)
links = getLinks(newArticle)3.获取wiki词条页面的标题,首段内容和链接
#获取wiki词条页面的标题,首段内容和链接
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("http://en.wikipedia.org"+pageUrl)
bsObj = BeautifulSoup(html)
try:
print(bsObj.h1.get_text())
print(bsObj.find(id="mw-content-text").findAll("p")[0].text)
print(bsObj.find(id="ca-edit").find("a").attrs['href'])
except AttributeError:
print("页面缺少一些属性!不过不用担心")
for link in bsObj.findAll("a",href=re.compile("^(/wiki/)")):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
#我们遇到了新的页面
newPage = link.attrs['href']
print("================\n" + newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")