爬虫实战:规范化流程爬取新浪新闻
一、基础知识
1.1 需要用到的框架
- Requests
- BeautifulSoup4
- Pandas
- Sqlite3
- json
- re
- jupyter
1.2 整个流程
- 踩点(通过Chorme的开发者工具中的Network选项卡去寻找自己需要的标签或者请求是哪一个),通常我们需要的往往是请求的DOC、JS这两个。
- 编写爬取各类信息的函数
- 整合成可复用的、可自定义一定爬取需求的类。
1.3 其他基础知识
- 我们在网站中看到的数据是非结构化数据:
- 只有将非结构化数据进行一定的处理才能变成结构化数据:
- 数据抽取(需要用到的框架:re、Requests、BeautifulSoup4)
- 转换(需要用到的框架:JSON)
- 存储(Pandas)
- Requests的简单用法示例:
import requests
res = requests.get('https://news.sina.com.cn/china/')
res.encoding = 'utf-8'
print res.text
- 返回的结果是HTML文档

- BeautifulSoup4的简单用法示例:
from bs4 import BeautifulSoup
html_sample = '\
<html> \
<body>\
<h1 id="title">Hello World</h1> \
<a href="#" class="link">This is link1</a> \
<a href="# link2" class="link">This is link2</a> \
</body> \
</html>'
soup = BeautifulSoup(html_sample,features="lxml")
print soup.text
result:
Hello World This is link1 This is link2
BeautifulSoup4的其他常见用法可以参考这几篇博文:
- beautifulsoup4教程(一)基础知识和第一个爬虫
- beautifulsoup4教程(二)bs4中四大对象
- beautifulsoup4教程(三)遍历和搜索文档树
- beautifulsoup4教程(四)css选择器
二、试探性爬取数据
2.1 试着进行一次简单的新闻抓取
#-*-coding:utf-8-*-
#查找带有href属性的a标签
import requests
from bs4 import BeautifulSoup
import re
res = requests.get('https://news.sina.com.cn/china/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,features="lxml")
def has_href(tag):
return tag.has_attr('href') and tag.name == 'a' and len(tag.text)>5 and len(tag.contents)<2 and tag.text.find('\n')==-1 and tag['href'].find('shtml')!=-1
for news in soup.find_all(has_href):
title = news.text
ahref = news['href']
time = re.match(r'.*([0-9]{4}-[0-9]{2}-[0-9]{2})',news['href']).group(1)
print time,title,ahref
- 通过观察发现,如果我们想直接在首页中抓取新闻,那么可以直接把关注点放在a标签上。
- 如果我们需要自定义筛选的方法,可以将筛选函数作为参数传递给bs4对象的find_all方法。
- 通过观察发现,a标签筛选出来之后有一些需要剔除的杂项,在这里我的过滤规则是:
标签名称是a、这个a标签需要有属性‘href’、这个a标签内部的文字长度需要大于5、且a标签内部的节点数只能为1(避免内部还包含其他标签的a标签对我们产生干扰)、a标签内部文字不包括换行、a标签的href属性中的连接要有shtml这个子串。这样筛选出来的条目就非常干净了。 - 可以通过正则表达式直接拿到文章的时间

2.2 整理文章的各类信息
文章的主要构成元素有:标题、时间、来源、文章内容、编辑、评论数,我们需要将这些信息都拿到,才能够去构建一个结构化的数据库。
- 获得文章的标题、时间、来源
#-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#上面分别是修改解释器和编译器的编码格式
import requests
from bs4 import BeautifulSoup
from datetime import datetime
res = requests.get("https://news.sina.com.cn/c/2019-01-31/doc-ihrfqzka2777216.shtml")
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,features='lxml')
print soup.select('.main-title')[0].contents[0]
dt = soup.select('.date')[0].contents[0]
print datetime.strptime(dt,'%Y年%m月%d日 %H:%M')
print soup.select('.source')[0].contents[0]
result:
玉兔二号睡觉不容易 为摆这个姿势花了十几个小时
2019-01-31 21:55:00
参考消息
- 在这里我们仅用一条数据来进行测试。
- datetime这个简易框架可以将任何形式的时间转换为规范化的时间格式。
- 在这里还有一个最重要的环节就是观察div元素,观察我们所需要的数据的类名是什么,处于哪个标签中的第几个结点。
- 获得文章的内容主体
#-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#上面分别是修改解释器和编译器的编码格式
import requests
from bs4 import BeautifulSoup
from datetime import datetime
res = requests.get("https://news.sina.com.cn/c/2019-01-31/doc-ihrfqzka2777216.shtml")
res.encoding = 'utf-8'
soup = BeautifulSoup(res.content,features='lxml')
article= []
print ' '.join(p.text.encode('utf-8').decode('utf-8').strip() for p in soup.select('#article p')[:-1])
- 在这里需要注意编码的问题,encode:将某字符串的编码格式转换为unicode编码。decode反之。
- 这里用到了列表解析式。
运行结果:

3.获得文章的责任编辑
print soup.select('.show_author')[0].text.lstrip('责任编辑:')
result:
张岩
4.获得文章的评论数
- 经过Chorme的开发者工具观察发现,存放评论数的div并没有直接提供这篇文章的评论数,那么极有可能是通过JS来获得评论数的。
- 检查发现,确实有一个请求返回的JS中包含了评论数

- 查看这个请求的请求头

Request URL:
https://comment.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=como>s-hrfqzka2777216&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t>size=3&h_size=3&thread=1&callback=jsonp_1549121868672&=1549121868672Request Method:
GETStatus Code:
200Remote Address:
121.14.32.154:443Referrer Policy:
unsafe-url
- 撰写python脚本
#-*-coding:utf-8
import requests
import json
#仔细看新闻id,并且去掉一些参数
res1 = requests.get('https://comment.sina.com.cn/page/info?versi\
on=1&format=json&channel=gn&newsid=comos-hrfqzka2777216&group=u\
ndefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=\
3&h_size=3')
commentjson = json.loads(res1.text)
print commentjson['result']['count']['total']
reslt:
51
三、规范化爬取数据
爬虫脚本是需要复用的,所以我们需要编写一个规范化的脚本。
3.1 构造获得新闻id的函数
- 新闻id是我们拿到诸多数据的关键点。
- 通过比对URL和上面获得评论的请求,我们可以总结出新闻id的格式。例如:
https://news.sina.com.cn/c/2019-01-31/doc-ihrfqzka2777216.shtml这条URL,它的新闻id部分是hrfqzka2777216。 - 那么我们就可以通过正则表达式或者字符串切片的操作根据URL拿到新闻id。
#-*-coding:utf-8-*-
import re
#使用字符串切片
newsurl = "https://news.sina.com.cn/c/2019-01-31/doc-ihrfqzka2777216.shtml"
newsid =newsurl.split('/')[-1].rstrip('.shtml').lstrip('doc-i')
print newsid
#或者用正则表达式
#group(0)是引用匹配到的字符串全文,group(1)是引用第一个分组内的部分
print re.search('doc-i(.+).shtml',newsurl).group(0)
print re.search('doc-i(.+).shtml',newsurl).group(1)
result:
hrfqzka2777216
doc-ihrfqzka2777216.shtml
hrfqzka2777216
- 了解匹配规则之后,我们将其写成函数
#-*-coding:utf-8-*-
import re
import json
import requests
def getCommentCounts(newsurl):
"""
根据newsurl来获取newsid
:param newsurl:
:return:newsid
"""
requestURL = "https://comment.sina.com.cn/page/info?version=1&format=json&\
channel=gn&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1\
&page_size=3&t_size=3&h_size=3" #注意这里传递参数的方法
getCountRequestUrl = requestURL.format(re.search('doc-i(.+).shtml',newsurl).group(1))
commentes = requests.get(getCountRequestUrl)
jd = json.loads(commentes.text)
return jd['result']['count']['total']
newsurl = "https://news.sina.com.cn/c/2019-01-31/doc-ihrfqzka2777216.shtml"
print getCommentCounts(newsurl)
result:
51
3.2 构造获得新闻所有信息的函数
- 获得文章标题、时间、来源、文章内容、编辑、评论数这些元素的方法我们在上面都已经总结完毕。将它们整理成函数即可
#-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#上面分别是修改解释器和编译器的编码格式
import re
import json
import requests
from bs4 import BeautifulSoup
def getCommentCounts(newsurl):
"""
根据newsurl来获取newsid
:param newsurl:
:return:newsid
"""
requestURL = "https://comment.sina.com.cn/page/info?version=1&format=json&\
channel=gn&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1\
&page_size=3&t_size=3&h_size=3" #注意这里传递参数的方法
getCountRequestUrl = requestURL.format(re.search('doc-i(.+).shtml',newsurl).group(1))
commentes = requests.get(getCountRequestUrl)
jd = json.loads(commentes.text)
return jd['result']['count']['total']
def getNewsDetail(newsurl):
res = requests.get(newsurl)
result = {}
res.encoding = 'utf-8'
soup = BeautifulSoup(res.content, features='lxml')
result['title'] = soup.select('.main-title')[0].contents[0]
dt = soup.select('.date')[0].contents[0]
# result['dt'] =datetime.strptime(dt, '%Y年%m月%d日 %H:%M')
result['newssource'] =soup.select('.source')[0].contents[0]
result['article'] = ' '.join(p.text.encode('utf-8').decode('utf-8').strip() for p in soup.select('#article p')[:-1])
result['editor'] =soup.select('.show_author')[0].text.lstrip('责任编辑:')
result['commentsCount'] = getCommentCounts(newsurl)
return json.dumps(result, encoding="UTF-8", ensure_ascii=False)
print getNewsDetail("https://news.sina.com.cn/c/2019-01-31/doc-ihrfqzka2777216.shtml")
result:
{"article": "原标题:此时此刻,“兔子”有话说 四号和玉兔二号醒啦! …………们的小兔子~", "newssource": "参考消息", "editor": "张岩 ", "commentsCount": 51, "title": "玉兔二号睡觉不容易 为摆这个姿势花了十几个小时"}
3.3 获得首页的多篇文章的信息
- 我们可以发现,在新浪新闻的首页有一个文章列表。
- 我们可以先试着爬一下这一页的文章
#-*-coding:utf-8-*-
#查找带有href属性的a标签
import requests
from bs4 import BeautifulSoup
import re
res = requests.get('https://news.sina.com.cn/china/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,features="lxml")
def has_href(tag):
return tag.has_attr('href') and tag.name == 'a' and len(tag.text)>5 and len(tag.contents)<2 and tag.text.find('\n')==-1 and tag['href'].find('shtml')!=-1
for news in soup.find_all(has_href):
title = news.text
ahref = news['href']
time = re.match(r'.*([0-9]{4}-[0-9]{2}-[0-9]{2})',news['href']).group(1)
print time,title,ahref
运行结果:

3.4 获得自定义页数的多篇文章的信息
- 我们需要知道是哪一个请求返回了不同页码中包含的文章列表,初步推测,这个请求的Requests中会有page这个参数,而Response中会包含有许多文章的标题。
- 观察发现,确实有一个请求是这样的
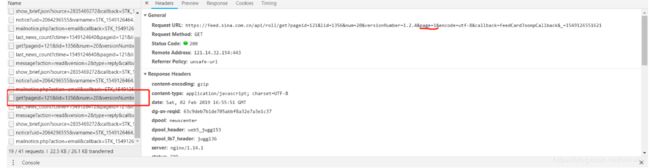
- 这个请求的地址是:
https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8&callback=feedCardJsonpCallback&_=1549161462841,那我们我们试着用Requests库来解析这个请求地址返回的数据。
import requests
import json
res = requests.get("https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8&callback=feedCardJsonpCallback&_=1549161462841")
res.encoding='utf-8'
print json.loads('{'+res.text.lstrip('try{feedCardJsonpCallback(').rstrip(');}catch(e){};')+'}}')
- 能够正确运行就表明已经成功解析这个json数据了。
- 我在这里遇到的问题:
- requests对象的text会自动去掉首尾的花括号便于显示,所以要获得标准的json格式需要通过JSON标准化校验工具来查看到底是哪里少了花括号
- http://www.bejson.com/
- 文件I/O中,write和writelines的区别要搞清楚
- 成功测试这个请求之后,我们就需要通过这个请求地址拿到一整页新闻的URL。
import requests
import json
res = requests.get("https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8&callback=feedCardJsonpCallback&_=1549161462841")
res.encoding='utf-8'
jd = json.loads('{'+res.text.lstrip('try{feedCardJsonpCallback(').rstrip(');}catch(e){};')+'}}',encoding="utf-8")
for ent in jd['result']['data']:
print ent['url']
result:
https://news.sina.com.cn/c/2019-02-03/doc-ihrfqzka3451003.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2854052.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2847095.shtml
https://news.sina.com.cn/o/2019-02-03/doc-ihqfskcp2844058.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihrfqzka3434798.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihrfqzka3435733.shtml
https://news.sina.com.cn/o/2019-02-03/doc-ihrfqzka3433346.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihrfqzka3425408.shtml
https://news.sina.com.cn/c/xl/2019-02-03/doc-ihrfqzka3424267.shtml
https://news.sina.com.cn/o/2019-02-03/doc-ihqfskcp2831343.shtml
https://news.sina.com.cn/o/2019-02-03/doc-ihrfqzka3427420.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2827676.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2828120.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2827295.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2826439.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2821815.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihrfqzka3418201.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2819203.shtml
https://news.sina.com.cn/c/2019-02-03/doc-ihqfskcp2802005.shtml
https://news.sina.com.cn/o/2019-02-03/doc-ihqfskcp2802999.shtml
- 拿到这一页的URL还不够,我们还要拿到URL对应的新闻的所有信息
#-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#上面分别是修改解释器和编译器的编码格式
from bs4 import BeautifulSoup
from datetime import datetime
import re
import json
import requests
def getCommentCounts(newsurl):
"""
根据newsurl来获取newsid
:param newsurl:
:return:newsid
"""
requestURL = "https://comment.sina.com.cn/page/info?version=1&format=json&\
channel=gn&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1\
&page_size=3&t_size=3&h_size=3" #注意这里传递参数的方法
getCountRequestUrl = requestURL.format(re.search('doc-i(.+).shtml',newsurl).group(1))
commentes = requests.get(getCountRequestUrl)
jd = json.loads(commentes.text)
return jd['result']['count']['total']
def getNewsDetail(newsurl):
res = requests.get(newsurl)
result = {}
res.encoding = 'utf-8'
soup = BeautifulSoup(res.content, features='lxml')
result['title'] = soup.select('.main-title')[0].contents[0]
dt = soup.select('.date')[0].contents[0]
# result['dt'] =datetime.strptime(dt, '%Y年%m月%d日 %H:%M')
result['newssource'] =soup.select('.source')[0].contents[0]
result['article'] = ' '.join(p.text.encode('utf-8').decode('utf-8').strip() for p in soup.select('#article p')[:-1])
result['editor'] =soup.select('.show_author')[0].text.lstrip('责任编辑:')
result['commentsCount'] = getCommentCounts(newsurl)
return json.dumps(result, encoding="UTF-8", ensure_ascii=False)
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
res.encoding='utf-8'
jd = json.loads('{'+res.text.lstrip('try{feedCardJsonpCallback(').rstrip(');}catch(e){};')+'}}',encoding="utf-8")
for ent in jd['result']['data']:
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
url = "https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8&callback=feedCardJsonpCallback&_=1549161462841"
for line in parseListLinks(url):
print line
运行结果:

- 但是一页肯定是不够的,所以我们需要通过刚才找到的获取不同页码的文章列表的请求来实现获取任意页数的文章的信息获取。
#-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#上面分别是修改解释器和编译器的编码格式
from bs4 import BeautifulSoup
from datetime import datetime
import re
import json
import requests
def getCommentCounts(newsurl):
"""
根据newsurl来获取newsid
:param newsurl:
:return:newsid
"""
requestURL = "https://comment.sina.com.cn/page/info?version=1&format=json&\
channel=gn&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1\
&page_size=3&t_size=3&h_size=3" #注意这里传递参数的方法
getCountRequestUrl = requestURL.format(re.search('doc-i(.+).shtml',newsurl).group(1))
commentes = requests.get(getCountRequestUrl)
jd = json.loads(commentes.text)
return jd['result']['count']['total']
def getNewsDetail(newsurl):
res = requests.get(newsurl)
result = {}
res.encoding = 'utf-8'
soup = BeautifulSoup(res.content, features='lxml')
result['title'] = soup.select('.main-title')[0].contents[0]
dt = soup.select('.date')[0].contents[0]
# result['dt'] =datetime.strptime(dt, '%Y年%m月%d日 %H:%M')
result['newssource'] =soup.select('.source')[0].contents[0]
result['article'] = ' '.join(p.text.encode('utf-8').decode('utf-8').strip() for p in soup.select('#article p')[:-1])
result['editor'] =soup.select('.show_author')[0].text.lstrip('责任编辑:')
result['commentsCount'] = getCommentCounts(newsurl)
return json.dumps(result, encoding="UTF-8", ensure_ascii=False)
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
res.encoding='utf-8'
jd = json.loads('{'+res.text.lstrip('try{feedCardJsonpCallback(').rstrip(');}catch(e){};')+'}}',encoding="utf-8")
for ent in jd['result']['data']:
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
url = "https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8&callback=feedCardJsonpCallback&_=1549161462841"
news_total = []
for i in range(1,5):
newsurl = url.format(i)
#parseListLinks返回的是包含每个分页的新闻的信息的列表,列表中是字典
newsary = parseListLinks(newsurl)
#用列表的extend方法加入新的部分,而不是用append
news_total.extend(newsary)
for line in news_total:
print line
运行结果:成功拿到了五页共四十多条的数据

四、将数据存放到数据库
- 在这里我们需要用到的是Pandas框架
- 用Pandas去解析列表对象后,能将数据转换为多种格式
 - 在这里我们需要将数据导出到数据库
- 在这里我们需要将数据导出到数据库
#-*-coding:utf-8-*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#上面分别是修改解释器和编译器的编码格式
from bs4 import BeautifulSoup
from datetime import datetime
import re
import json
import requests
import pandas
import sqlite3
def getCommentCounts(newsurl):
"""
根据newsurl来获取newsid
:param newsurl:
:return:newsid
"""
requestURL = "https://comment.sina.com.cn/page/info?version=1&format=json&\
channel=gn&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1\
&page_size=3&t_size=3&h_size=3" #注意这里传递参数的方法
getCountRequestUrl = requestURL.format(re.search('doc-i(.+).shtml',newsurl).group(1))
commentes = requests.get(getCountRequestUrl)
jd = json.loads(commentes.text)
return jd['result']['count']['total']
def getNewsDetail(newsurl):
res = requests.get(newsurl)
result = {}
res.encoding = 'utf-8'
soup = BeautifulSoup(res.content, features='lxml')
result['title'] = soup.select('.main-title')[0].contents[0]
dt = soup.select('.date')[0].contents[0]
# result['dt'] =datetime.strptime(dt, '%Y年%m月%d日 %H:%M')
result['newssource'] =soup.select('.source')[0].contents[0]
result['article'] = ' '.join(p.text.encode('utf-8').decode('utf-8').strip() for p in soup.select('#article p')[:-1])
result['editor'] =soup.select('.show_author')[0].text.lstrip('责任编辑:')
result['commentsCount'] = getCommentCounts(newsurl)
return json.dumps(result, encoding="UTF-8", ensure_ascii=False)
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
res.encoding='utf-8'
jd = json.loads('{'+res.text.lstrip('try{feedCardJsonpCallback(').rstrip(');}catch(e){};')+'}}',encoding="utf-8")
for ent in jd['result']['data']:
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
url = "https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8&callback=feedCardJsonpCallback&_=1549161462841"
news_total = []
for i in range(1,2):
newsurl = url.format(i)
#parseListLinks返回的是包含每个分页的新闻的信息的列表,列表中是字典
newsary = parseListLinks(newsurl)
#用列表的extend方法加入新的部分,而不是用append
news_total.extend(newsary)
# for line in news_total:
# print line
df = pandas.DataFrame(news_total)
with sqlite3.connect('news.sqlite') as db:
df.to_sql('news',con=db)
 ### 四、GITHUB
### 四、GITHUB
https://github.com/chinaltx/get_sina_news