以拼音输入法(自然语言处理)为例,简单理解隐含马尔可夫模型
最近在学习 语音&搜索 方面的知识,属于从门外汉起步,很多这方面的书在讲解的时候都是要求有相关知识背景或者是一堆公式让像我这样不是学计算机出身而且数学也学得不好的菜鸟看得头晕眼花的,因此特地写下这篇文章讲讲自己对隐含马尔可夫模型的理解,尽量把它写得通俗易懂,让小白也能读懂隐含马尔可夫模型。
所需知识背景:概率论
马尔可夫模型
首先我们来了解一下 马尔可夫模型
百度百科给出的定义:马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。
好吧。一说到模型可能就让人觉得有懵,在这里我们可以简单理解为一个模具或者一条公式,我们知道,公式可以当工具使用,把数字填进去,就能获得你想要的结果,当然这里不止能填数字,还能填一些实际的东西。
它的公式是长这样的:
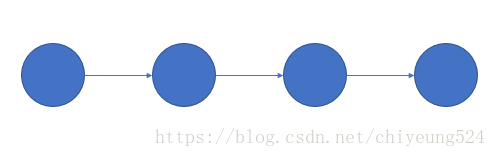
该图也称为 马尔可夫链 。圆圈就像是平常数学公式里的 x 一样,当然在这里我们称之为 状态 ,而箭头我们可以理解为 转移 ,看起来还是有点难理解,下面我们举个小小的关于天气例子。
假设第一个圆圈代表第一天的天气,第二个圆圈代表第二天的天气,以此类推,我们得到下图。

那么这幅图就表明了,第一天天气 状态 是晴天,第二天天气 状态 还是转移到了晴天,第三天天气 状态 转移到雨天,第四天天气 状态 转移到了阴天。而马尔可夫模型中,转移一般是带有概率的,比如第一天是晴天,那么假定第二天是晴天的概率是80%,第三天是雨天的概率是30%,第四天是阴天的概率是50%
那么上图就可以变成如下:
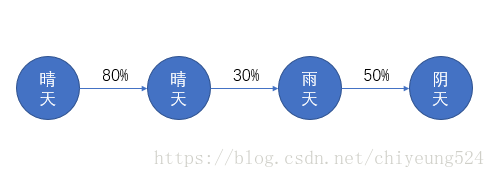
这就是一个完整的 马尔可夫链。
我们再更换为一个自然语言处理的例子,用一句话里的每个字表示状态,而转移概率则是说出这个字后面跟的下一个字的概率。下面举个例子:“我不想你”
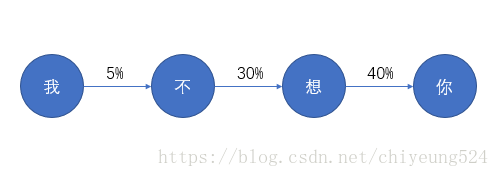
假设每一个字的概率只与前面一个字有关,而与前面其他字无关(“想”字的30%概率只与“不”字有关,而不考虑前面的“我”字,即为二元模型,如果与前面2个字有关,则为三元模型),那么这条马尔可夫链就表示一个人说出“我”字后面跟上“不”字的概率是5%(当然这个数据是编的),后面同理。所以我们先假设一个人说出“我”的概率是P(我)=10%,那么他在任意想说话的一刻想表达句子“我不想你”的概率是:
\(P(我不想你)=P(我,不,想,你)=P(我)*P(不|我)*P(想|不)*P(你|想)=0.1*0.5*0.3*0.4=0.0006\)
推广到更一般的字句,我们可以假定S为有意义的句子,由字 \(w_1,w_2,w_3,\ldots,w_n\) 组成,
则\(P(S)=P(w_1, w_2, \ldots, w_n)=P(w_1)*P(w_2|w_1)*\ldots*P(w_n|w_{n-1})\)
以上就是二元马尔可夫模型。
隐含马尔可夫模型
在日常生活中,我们一般利用拼音进行打字,从而使我们的想法能够在计算机中得到表达。例如,我想要在计算机中表达“我不想你”,那么我们就需要往键盘敲入“wo bu xiang ni”这四串英文字符,我们从计算机的角度出发,假如我们现在是计算机,我们观测到的只有英文字符,并不能直接从键盘中得到汉字“我不想你”,因此把我们观测到的信息,称作观测。
那么我们可以将这个过程用下图进行表示。
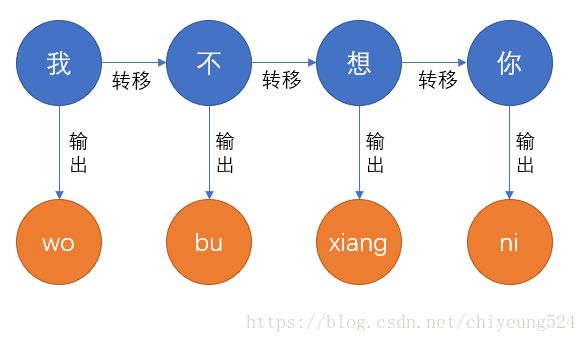
图中蓝色圆圈表示 隐含的状态 ,橙色圆圈表示 观测到的状态 ,同样地,连接蓝色圆圈之间的箭头称作 转移 ,连接蓝色圆圈与橙色圆圈之间的箭头我们称作 输出 。我们可以看到,蓝色圆圈是输入者心里所想的字,计算机是无法看到的,这就等于状态被隐藏起来了,这就是为什么叫隐含马尔可夫模型的原因;而橙色圆圈是计算机能接收到的观测信息,那么现在计算机要做的就是怎样去“猜测”输入者所输入的橙色圆圈链信息,就是想要表达的蓝色圆圈链信息。
当然,如果我是计算机的话,我当然会选择猜人们输入得最多的那一句“wo bu xiang ni”,那么这下又变成了概率的问题了。
首先由于没有手头数据,我们就随便编一下 转移概率(后一个字会跟前一个字的概率)和 输出概率(这个拼音是想表达这个字的)吧
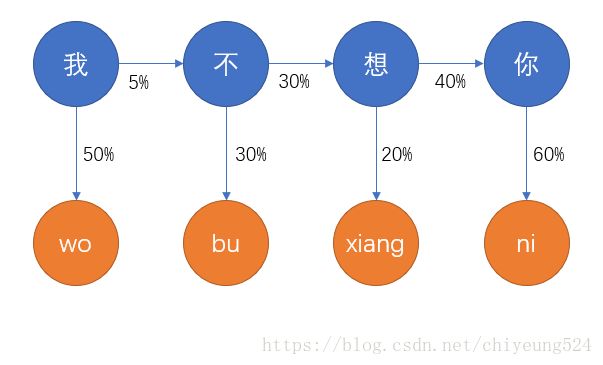
转移概率前面讲过了,就不再多作解释;而蓝色圆圈到橙色圆圈之间的概率,表示的是,计算机接收到“wo”,然后猜测这串字母是想表达“我”的概率是50%,其他同理。
那么我们就可以去算“wo bu xiang ni ”是想要表达“我不想你”的概率:
$$P=P(我)*P(我|wo)*P(不|我)*P(不|bu)*P(想|不)*P(想|xiang)*P(你|想)*P(想|xiang)=0.1*0.5*0.05*0.3*0.3*0.2*0.4*0.6=0.0000108$$
希望这一大串计算没有把你看懵,其实仔细慢慢看就能很清晰地看出来是怎么算的了。虽然这个概率看起来有点小,但是它在“wo bu xiang ni ”的各种猜测中已经是最高的了,所以它应该是被排到候选句的第一位去。
再假设“wo bu xiang ni ”代表的是其他的候选句,如下图。
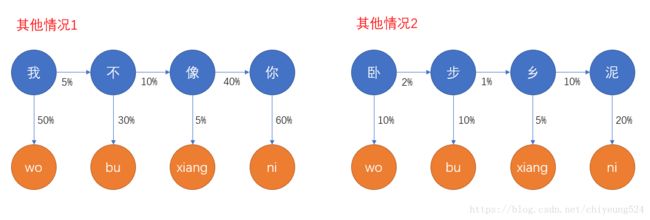
通过计算可以算出,其他情况都没有“我不想你”的概率高,因此,“我不想你”理应放在候选句首位。
实际情况:

这跟我们刚刚算出来的结果是一样的。
当然,实际应用中,拼音输入法不仅仅是像上面仅仅运用隐含马尔可夫模型那样简单,还涉及到其他模型,具体我自己也没有太多去了解,我只是把它简化了便于讲解隐含马尔可夫模型,在其他方面的运用例如语音识别,中文分词,输入预测等等都是大同小异的,自己类比一下就差不多啦。
关于转移概率和输出概率的设定,属于参数设定,在本文中是我自己瞎编的,但是在实际应用当中需要用到大数据进行统计得出,这就是为什么各大厂商热衷于收集用户的使用数据的原因了,收集更多更全面的有用数据,就能使参数更加准确,就能给用户提供更准确、更人性化的体验(广告),想想以前还在用智能ABC,一个一个字敲那叫一个鸡肋。
以上均为个人浅略学习后的总结,不保证完全正确,如果有哪位大大发现哪些部分解释有误,欢迎并感谢你的指出。