编译和链接的那些故事
编译连接过程
从预编译->编译->汇编->连接
(1)预编译 gcc -E main.c -o main.i
内部处理:宏定义处理、头文件包含的指令、删除注释、特殊符号的处理
(2)编译 gcc -S main.i -o main.s
编译环节是对源代码进行语法分析,并优化产生对应的汇编代码
生成符号、产生汇编代码
(3)汇编 gcc -c main.s -o main.o
将汇编语言翻译成二进制代码 生成可重定位的二进制文件
(4) 连接 gcc -o mian main.o
连接分为静态连接和动态连接
内部处理:合并段表 调整偏移量 合并符号表 完成符号的重定位代码如下:
int data1 = 10;
int data2 = 0;
int data3;
static int data4 = 20;
static int data5 = 0;
static int data6;
int main()
{
int a = 30;
int b = 0;
int c;
static data7 = 40;
static data8 = 0;
static data9;
return 0;
}
预编译生成的 .i 文件如下:
# 1 "main.c"
# 1 ""
# 1 ""
# 1 "main.c"
int data1 = 10;
int data2 = 0;
int data3;
static int data4 = 20;
static int data5 = 0;
static int data6;
int main()
{
int a = 30;
int b = 0;
int c;
static data7 = 40;
static data8 = 0;
static data9;
return 0;
}
编译生成的 .s 文件如下:
.file "main.c"
.globl data1
.data
.align 4
.type data1, @object
.size data1, 4
data1:
.long 10
.globl data2
.bss
.align 4
.type data2, @object
.size data2, 4
data2:
.zero 4
.comm data3,4,4
.data
.align 4
.type data4, @object
.size data4, 4
data4:
.long 20
.local data5
.comm data5,4,4
.local data6
.comm data6,4,4
.text
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl $30, -12(%ebp)
movl $0, -8(%ebp)
movl $0, %eax
leave
ret
.size main, .-main
.local data9.1246
.comm data9.1246,4,4
.local data8.1245
.comm data8.1245,4,4
.data
.align 4
.type data7.1244, @object
.size data7.1244, 4
data7.1244:
.long 40
.ident "GCC: (GNU) 4.4.6 20120305 (Red Hat 4.4.6-4)"
.section .note.GNU-stack,"",@progbits
汇编生成的 .o 文件如下:
^?ELF^A^A^A^@^@^@^@^@^@^@^@^@^A^@^C^@^A^@^@^@^@^@^@^@^@^@^@^@Ð^@^@^@^@^@^@^@4^@^@^@^@^@(^@ ^@^F^@U<89>å<83>ì^PÇEô^^^@^@^@ÇEø^@^@^@^@¸^@^@^@^@ÉÃ^@
^@^@^@^T^@^@^@(^@^@^@^@GCC: (GNU) 4.4.6 20120305 (Red Hat 4.4.6-4)^@^@.symtab^@.strtab^@.shstrtab^@.text^@.data^@.bss^@.comment^@.note.GNU-stack^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^[^@^@^@^A^@^@^@^F^@^@^@^@^@^@^@4^@^@^@^[^@^@^@^@^@^@^@^@^@^@^@^D^@^@^@^@^@^@^@!^@^@^@^A^@^@^@^C^@^@^@^@^@^@^@P^@^@^@^L^@^@^@^@^@^@^@^@^@^@^@^D^@^@^@^@^@^@^@'^@^@^@^H^@^@^@^C^@^@^@^@^@^@^@\^@^@^@^T^@^@^@^@^@^@^@^@^@^@^@^D^@^@^@^@^@^@^@,^@^@^@^A^@^@^@0^@^@^@^@^@^@^@\^@^@^@-^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^A^@^@^@5^@^@^@^A^@^@^@^@^@^@^@^@^@^@^@<89>^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^Q^@^@^@^C^@^@^@^@^@^@^@^@^@^@^@<89>^@^@^@E^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^A^@^@^@^B^@^@^@^@^@^@^@^@^@^@^@8^B^@^@^P^A^@^@^H^@^@^@^M^@^@^@^D^@^@^@^P^@^@^@ ^@^@^@^C^@^@^@^@^@^@^@^@^@^@^@H^C^@^@R^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^@^@^@^@^D^@ñÿ^@^@^@^@^@^@^@^@^@^@^@^@^C^@^A^@^@^@^@^@^@^@^@^@^@^@^@^@^C^@^B^@^@^@^@^@^@^@^@^@^@^@^@^@^C^@^C^@^H^@^@^@^D^@^@^@^D^@^@^@^A^@^B^@^N^@^@^@^D^@^@^@^D^@^@^@^A^@^C^@^T^@^@^@^H^@^@^@^D^@^@^@^A^@^C^@^Z^@^@^@^L^@^@^@^D^@^@^@^A^@^C^@%^@^@^@^P^@^@^@^D^@^@^@^A^@^C^@0^@^@^@^H^@^@^@^D^@^@^@^A^@^B^@^@^@^@^@^@^@^@^@^@^@^@^@^C^@^E^@^@^@^@^@^@^@^@^@^@^@^@^@^C^@^D^@;^@^@^@^@^@^@^@^D^@^@^@^Q^@^B^@A^@^@^@^@^@^@^@^D^@^@^@^Q^@^C^@G^@^@^@^D^@^@^@^D^@^@^@^Q^@òÿM^@^@^@^@^@^@^@^[^@^@^@^R^@^A^@^@main.c^@data4^@data5^@data6^@data9.1246^@data8.1245^@data7.1244^@data1^@data2^@data3^@main^@
~ ELF文件
ELF文件:在计算机科学中,是一种用二进制文件,可执行文件,目标代码,共享库和核心转储格式文件。它由四部分构成分别是ELF头(ELF header)、程序头表(Program header table)、节(section)和节头表(section header table)。
file命令:查看文件头部信息
ll命令:和ls -l一样

readelf命令:读取ELF文件中信息
readelf -h:读取ELF文件头信息
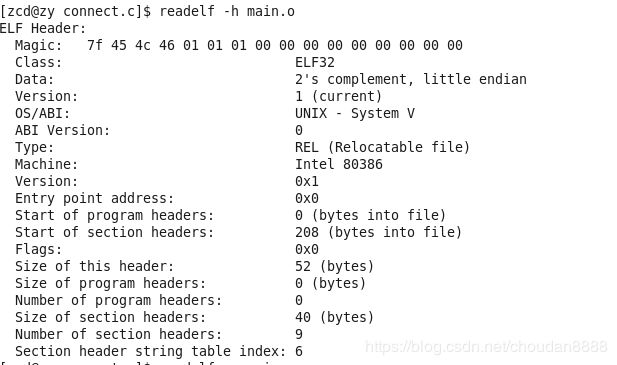
readelf -s main.o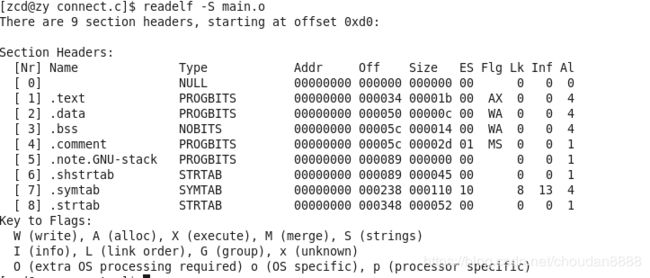
从图中可以看出:data.size = 000c 那么c / 4 = 3;.data段存储了3个数据
bss.size = 0014 那么 14 / 4 = 5; .bss段存储了5个数据
但是:代码中有6个未初始化或者初始化为0的的数据,为何只有五个?
那么来了解一下c语言中的强符号和弱符号
强符号:初始化了的非静态变量
弱符号:未初始化的非静态变量
所以说代码中的int data3是一个未初始化的非静态变量 它是一个弱符号,它在存储中不占有.bss内存,会被强符号替代注意上图中.bss 和.comment 段起始地址重合,这是因为.bss 在文件中不占内存,这时候
数据如何存储呢?
注意上图中的[7].symtab,这是数据生成的符号表,.bss 不占据实际的磁盘空间,只在
段表中记录大小,从而节约了磁盘的空间。在符号表中记录符号。当文件加载运行时,才分
配空间以及初始化。
在 elf 文件结构中,有一个字符串表.strtab,里面存放的是 elf 文件中各个段的名字以及
变量名等字符串,字符串表中记录了这些字符串以及对应的下标,需要用到这些字符串时,
直接用偏移下标去取就行了。段表中存放的段的名字这一项,就是存的.strtab 中对应字符串
的偏移。链接有以下几个部分要做
1、 合并段表:将多个二进制可重定位文件中的段信息整合放到一个文件中
2、 调整段偏移:段表经过合并之后大小发生了变化,所以地址需要适当的偏移
3、 合并符号表:将多个二进制可重定位文件中的符号整合到一个文件中
4、 完成符号的重定位:连接器把每个符号定义与一个虚拟地址联系起来,然后
修改所有对这些符号的引用,使得它们指向这个存储位置,从而重定位这些
节
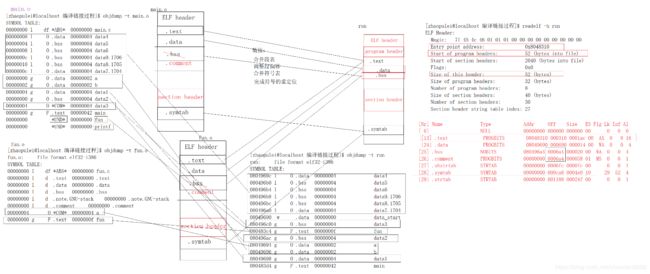
按照属性划分不同的段放在同一页,运行时按照 LOAD 页信息将段按照页读入到虚拟地址空间
以上就是编译链接的大体内容,希望能对你们有所帮助!