聚类算法
目录
1、k-means
2、密度聚类DBSCAN
3、使用高斯混合模型(GMM)的期望最大化(EM)聚类
3.1、EM算法
4、层次聚类
聚类指事先并不知道任何样本的类别标号,希望通过某种算法来把一组未知类别的样本划分成若干类别,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此 clustering 通常并不需要使用训练数据进行学习,这在机器学习中被称作 unsupervised learning (无监督学习)
通常,人们根据样本间的某种距离或者相似性来定义聚类,即把相似的(或距离近的)样本聚为同一类,而把不相似的(或距离远的)样本归在其他类。
聚类的目标:组内的对象相互之间时相似的(相关的),而不同组中的对象是不同的(不相关的)。组内的相似性越大,组间差别越大,聚类就越好。分组的原则是组内距离最小化而组间距离最大化。
1、k-means
典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的K类别,采用距离作为相似性的评级指标,即认为两个对象的距离越近,其相似性越大。
算法过程:
- 从N个样本中随机选取k个对象作为原始的聚类质心。
- 分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中。
- 所有对象分配完成后,重新计算k个聚类的质心。
- 与前一次的k个聚类中心比较,如果发生变化,重复过程(2),否则(5).
- 当质心不再发生变化时,停止聚类过程并输出结果。

聚类的结果可能依赖初始聚类中心的随机选择,可能使得结果严重偏离全局最优分类。实践中为了得到更好的结果,通常选择不同的初始聚类中心,多次运行KM算法,在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据,聚类中心取该簇的均值,当但样本的属性是分类变量时,可以使用K-众数方法。
K值的确定:
1.手肘法
手肘法的核心指标是SSE(sum of the squared errors,误差平方和):

其中,Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。
SSE = [] # 存放每次结果的误差平方和
for k in range(1,9):
estimator = KMeans(n_clusters=k) # 构造聚类器
estimator.fit(df_features[['R','F','M']])
SSE.append(estimator.inertia_)
X = range(1,9)
plt.xlabel('k')
plt.ylabel('SSE')
plt.plot(X,SSE,'o-')
plt.show()
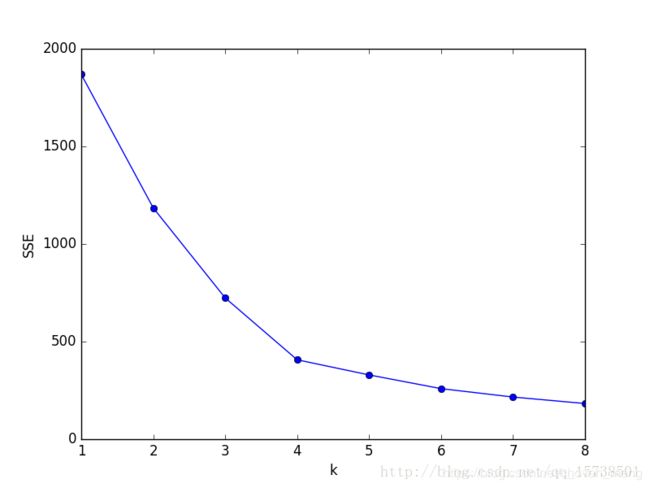
显然,肘部对于的k值为4,故对于这个数据集的聚类而言,最佳聚类数应该选4.
2、轮廓系数法:
该方法的核心指标是轮廓系数(Silhouette Coefficient),某个样本点Xi的轮廓系数定义如下:
![]()
其中,a是Xi与同簇的其他样本的平均距离,称为凝聚度,b是Xi与最近簇(用Xi到某个簇所有样本平均距离作为衡量该点到该簇的距离后,选择离Xi最近的一个簇作为最近簇。)中所有样本的平均距离,称为分离度。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],且簇内样本的距离越近,簇间样本距离越远,平均轮廓系数越大,聚类效果越好。那么,很自然地,平均轮廓系数最大的k便是最佳聚类数。
Scores = [] # 存放轮廓系数
for k in range(2,9):
estimator = KMeans(n_clusters=k) # 构造聚类器
estimator.fit(df_features[['R','F','M']])
Scores.append(silhouette_score(df_features[['R','F','M']],estimator.labels_,metric='euclidean'))
X = range(2,9)
plt.xlabel('k')
plt.ylabel('轮廓系数')
plt.plot(X,Scores,'o-')
plt.show()
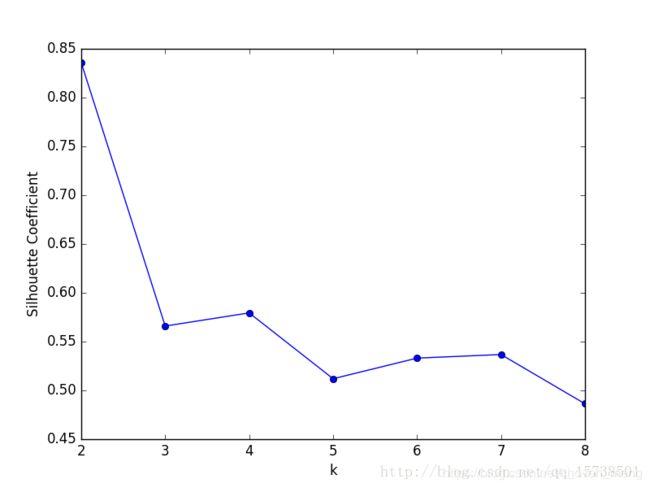
可以看到,轮廓系数最大的k值是2,这表示我们的最佳聚类数为2。但是,值得注意的是,从k和SSE的手肘图可以看出,当k取2时,SSE还非常大,所以这是一个不太合理的聚类数,我们退而求其次,考虑轮廓系数第二大的k值4,这时候SSE已经处于一个较低的水平,因此最佳聚类系数应该取4而不是2。
但是,讲道理,k=2时轮廓系数最大,聚类效果应该非常好,那为什么SSE会这么大呢?在我看来,原因在于轮廓系数考虑了分离度b,也就是样本与最近簇中所有样本的平均距离。为什么这么说,因为从定义上看,轮廓系数大,不一定是凝聚度a(样本与同簇的其他样本的平均距离)小,而可能是b和a都很大的情况下b相对a大得多,这么一来,a是有可能取得比较大的。a一大,样本与同簇的其他样本的平均距离就大,簇的紧凑程度就弱,那么簇内样本离质心的距离也大,从而导致SSE较大。所以,虽然轮廓系数引入了分离度b而限制了聚类划分的程度,但是同样会引来最优结果的SSE比较大的问题,这一点也是值得注意的。
初始点的选择:
K-means算法是初始值敏感的,选择不同的初始值可能导致不同的簇划分规则。
方法一:kmeans++:
1)从输入的数据点集合中随机选择一个点作为第一个聚类中心
2)对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3)选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4)重复2和3直到k个聚类中心被选出来
5)利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述上可以看到,算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下:
1)先从我们的数据库随机挑个随机点当“种子点”
2)对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
3)然后,再取一个随机值,用权重的方式来计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
4)重复2和3直到k个聚类中心被选出来
5)利用这k个初始的聚类中心来运行标准的k-means算法
kmeans++改进:K-means II算法:
K-means II算法为解决Kmeans++算法缺点而产生的一种算法:主要思路是改变每次遍历时候的取样规则,并非按照K-means++算法每次遍历只取一个样本,而是每次取K个样本,重复该取样O(logn)次,然后再将这些抽样出来的样本聚类出K个点,最后使用这K个点作为K-means算法的初始聚类中心点。实践证明:一般5次重复采用就可以保证一个比较好的聚类中心点。
方法二:选用层次聚类或Canopy算法进行初始聚类,然后从k个类别中分别随机选取k个点,来作为kmeans的初始聚类中心点
优缺点:
优点:
K-Means算法的优势在于它的速度非常快,因为我们所做的只是计算点和簇中心之间的距离; 这已经是非常少的计算了!因此它具有线性的复杂度O(n)。算法简单,容易解释,聚类效果中上,适用于高维。
缺点:
1)必须手动选择K值,
2)从随机选择的簇中心点开始运行,这导致每一次运行该算法可能产生不同的聚类结果。因此,该算法结果可能具有不可重复,缺乏一致性等性质。
3)对离群点敏感,对噪声点和孤立点很敏感(通过k中值算法可以解决)
思考:
1、K-means算法在迭代过程中选择所有点的均值作为新的质心,如果簇中存在异常点,将导致均值偏差比较严重。比如一个簇中有2,4,6,8,100五个数据,计算平均值,新的质点为24,显然这个质点离绝大多数点都比较远;在当前情况下,使用中位数6可能比使用均值的方法更好,使用中位数的聚类算法叫K中值聚类K-Medians。
K-medians的优点是对数据中的异常值不太敏感,但是在较大的数据集时进行聚类时,速度要慢得多,造成这种现象的原因是这种方法每次迭代时,都需要对数据进行排序。
2、在传统的k-means算法中,要计算所有的样本点到所有的质心的距离,如果样本量非常大,如达到10万以上,特征100以上,此时使用传统的k-means非常耗时。在大数据时代,这样的情形越来越多,此时Mini Batch K-means应运而生。
顾名思义,Mini Batch,也就是用样本集中的一部分样本来做传统的K-means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是聚类的精度会有所下降,一般来说降低的幅度在可以接受的范围内。
算法步骤:
1)首先抽取部分数据集,使用K-means算法构建出K个聚簇点的模型。
2)继续抽取训练集中的部分数据集样本数据(吴放回的随机抽样),并将其添加到模型中,分配给最近的聚簇中心点。
3)更新聚簇的中心点值。
循环迭代2)和3),直到中心点稳定或者达到迭代次数。
2、密度聚类DBSCAN
DBSCAN算法是一种基于密度的聚类算法:
- 聚类的时候不需要预先指定簇的个数
- 最终的簇的个数不定
DBSCAN算法将数据点分为三类:
- 核心点:在半径Eps内含有超过MinPts数目的点
- 边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
- 噪音点:既不是核心点也不是边界点的点
举例说明算法流程:

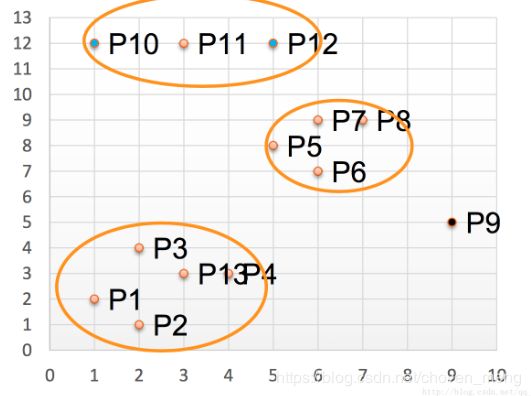
1)取Eps = 3,MinPts = 3,依据DBSCAN对所有点进行聚类(曼哈顿距离)
2)对每个点计算其邻域Eps = 3内的点的集合;集合内点的个数超过MinPts个的点为核心点;查看剩余点是否在核心点的邻域内,若在,则为边界点,否则为噪声点;
3)将距离不超过Eps的点相互连接,构成一个簇,核心点邻域内的点也会被加到这个簇中,则上图形成3个簇。
优缺点:
优点:
1)不需要输入要划分的聚类个数;
2)聚类的形状没有偏倚,可以发现任意形状的聚类空间。(K-means基于距离的度量聚类空间通常为圆形)
3)能够有效的处理噪声点。
缺点:
1)由于该算法直接对整个数据库操作,当数据量很大时,要求较大的内存支持,i/o消耗也很大;
2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差(有些簇内距离较小,有些簇内距离很大,但是Eps是确定的,所以,大的点可能被误判断为离群点或者边界点,如果Eps太大,那么小距离的簇内,可能会包含一些离群点或者边界点,KNN的k也存在同样的问题)。
3、使用高斯混合模型(GMM)的期望最大化(EM)聚类
高斯混合模型是聚类算法的一种。k−means算法是确切给出每个样本被分配到某一个簇,称为硬分配;而高斯混合模型则是给出每个样本被分配到每个簇的概率,最后从中选取一个最大的概率对应的簇作为该样本被分配到的簇,称为软分配。
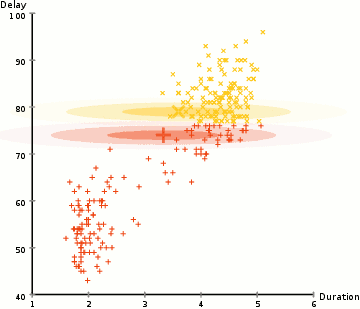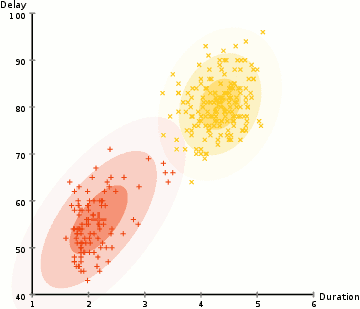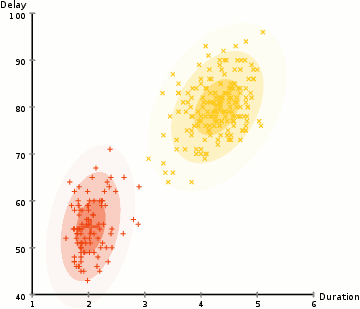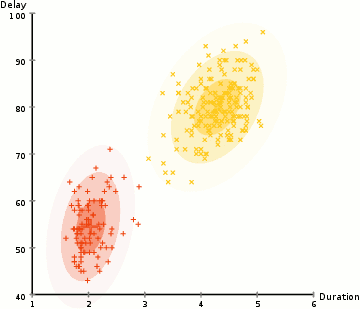
高斯混合(Mixture-of-Gaussian)聚类采用概率模型来表达聚类原型。
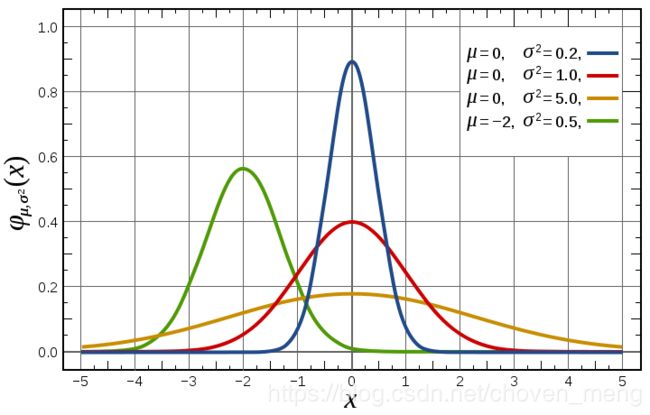
不一样参数下,高斯分布如下:
对于多元高斯分布,n维样本空间![]() 中的随机向量x,概率密度函数为
中的随机向量x,概率密度函数为
![]()
其中μ是n维均值向量,Σ是n×m的协方差矩阵。高斯概率密度函数由μ和Σ两个参数决定.
高斯混合分布为:
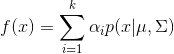
该分布由k个高斯分布混合而成,![]() 为混合系数,
为混合系数,![]() ≥0且
≥0且 .(权重和为1)
.(权重和为1)
下面是一个高斯模型学习过程简图,先有个感性的认识:
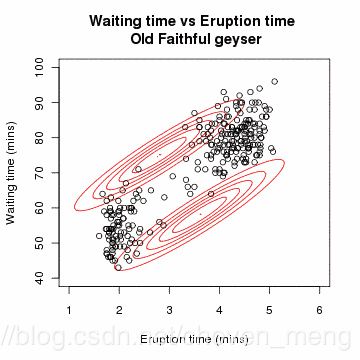
那么该怎么求解各个权重系数,常用的方法是EM(期望最大)算法。
3.1、EM算法
初识EM算法
硬币问题
先看一个抛硬币问题,如果我们有A和B两个不均匀硬币,选择任意一个硬币抛10次(这里我们知道选择是的哪一个硬币),共计选择5次。正面记为H,背面记为T。记录实验结果,求A和B再抛正面向上的概率?

使用极大似然估计(Maximum likelihood)来算:
- 统计出每次实验,正反面的次数
- 多次实验结果相加
-
相除得到结果,P(A)=0.8,P(B)=0.45
但是在实际过程中,很有可能我们只知道有两个硬币,不知道每次选择的哪一个硬币,问是否能求出每个硬币抛出正面的概率?
这里使用的是EM算法:

使用期望最大值(Expectation maximization,EM)算法来算:
- 假设
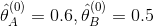 ;
; - 统计每次的实验结果,记录正反面
- 通过贝叶斯公式,估计每次实验选择的A硬币或是B硬币的概率
- 依据计算出的选择硬币概率得到该概率下的正反面结果
- 相加,相除得到
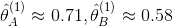
- 重复上面的过程,例如迭代10次后,得到
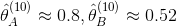
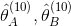 就是使用EM算法计算出的概率值
就是使用EM算法计算出的概率值
这里比较难理解的是:如何利用贝叶斯公式计算每次实验选择的A硬币或是B硬币的概率?
那么先看下面这个例子:
假如现在有射击运动员甲和乙,甲乙射击靶心的概率为![]() 如果现在有一组实验结果为
如果现在有一组实验结果为
中,不中,中,中,中,
问这次是谁射击的?
直观上的来看,非常大的概率是甲射击的,但是也有可能是乙走狗屎运了。那么该如何从概率的角度计算是谁射击的?
首先我们知道选择甲和乙的概率为P(甲)=P(乙)=0.5(先验概率),本次实验记为E。通过贝叶斯公式:

故本次实验有98%的可能是A射击的,2%的可能是B射击的。

上面我们计算出每次实验中是抛A或抛B的概率值就是隐变量.这个过程就是EM算法的简单案例。
形式化EM算法
未观测变量的学名是“隐变量”(latent variable).令X表示已观测变量集,Z表示隐变量集,Θ表示模型参数,欲对Θ做极大似然估计,则应最大化对数似然:
![]()
因为Z是隐变量,无法直接求解。我们可通过对Z计算期望,来最大化已观测数据的对数“边际似然”:
![]()
EM算法是常用的估计参数隐变量的利器,基本思想是:
若参数Θ已知,则可根据训练数据推断出最优隐变量Z的值(E步);再由推断出的最优隐变量Z对参数Θ做极大似然估计(M步)。
以初始值![]() 为起点,对上式迭代执行以下步骤直到收敛:
为起点,对上式迭代执行以下步骤直到收敛:
- 基于
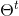 推测隐变量Z的期望,记为
推测隐变量Z的期望,记为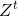 ;
; - 基于已观测变量X和对参数Θ做极大似然估计,记为
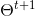
这就是EM算法的原型。
高斯混合模型聚类算法参考链接
4、层次聚类
分层聚类算法实际上分为两类:自上而下或自下而上。自下而上的算法首先将每个数据点视为一个单一的簇,然后连续地合并(或聚合)成对的簇,直到所有的簇都合并成一个包含所有数据点的簇。因此,自下而上的分层聚类被称为合成聚类或HAC。这个簇的层次可以用树(或树状图)表示。树的根是收集所有样本的唯一簇,叶是仅具有一个样本的簇。在进入算法步骤之前,请查看下面的图解。
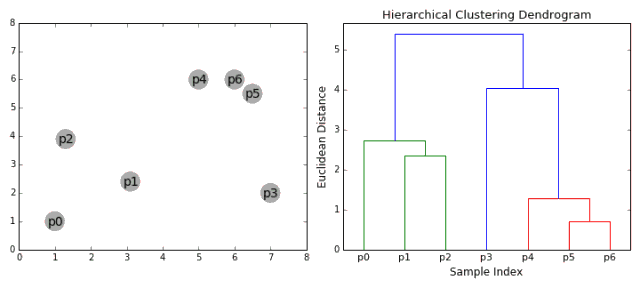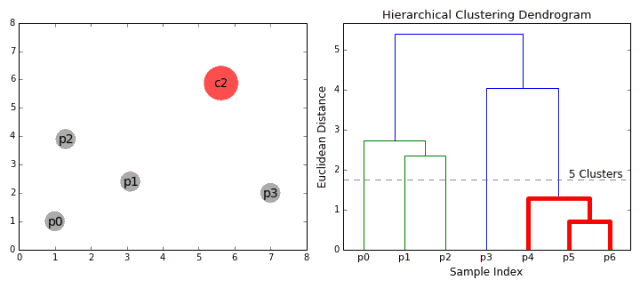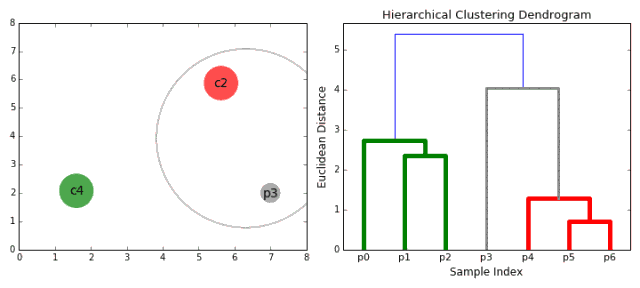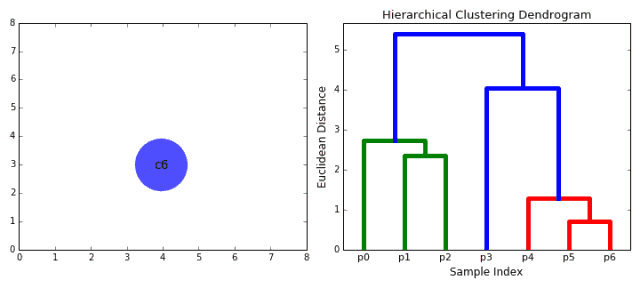
1、我们首先将每个数据点视为一个单一的簇,即如果我们的数据集中有X个数据点,那么我们就有X个簇。然后,我们选择一个距离度量,来度量两个簇之间距离。作为一个例子,我们将使用平均关联度量,它将两个簇之间的距离定义为第一个簇中的数据点与第二个簇中的数据点之间的平均距离。
2、在每次迭代中,我们将两个簇合并成一个簇。选择平均关联值最小的两个簇进行合并。根据我们选择的距离度量,这两个簇之间的距离最小,因此是最相似的,所有应该合并。
3、重复步骤2直到我们到达树的根,即我们只有一个包含所有数据点的簇。通过这种方式,我们可以选择最终需要多少个簇。方法就是选择何时停止合并簇,即停止构建树时!
分层次聚类不需要我们指定簇的数量,我们甚至可以在构建树的同时,选择一个看起来效果最好的簇的数量。另外,该算法对距离度量的选择并不敏感;与其他距离度量选择很重要的聚类算法相比,该算法下的所有距离度量方法都表现得很好。当基础数据具有层次结构,并且想要恢复层次结构时,层次聚类算法能实现这一目标;而其他聚类算法则不能做到这一点。与K-Means和GMM的线性复杂性不同,层次聚类的这些优点是以较低的效率为代价,即它具有O(n3)的时间复杂度。