《Revisiting Distillation and Incremental Classifier Learning》 论文笔记
原文链接:https://arxiv.org/abs/1807.02802
本文主要就是对于 iCaRL这篇论文的再研究,设置了一些研究型实验推翻了之前 iCaRL 论文中的一些说法,最终得出结论,iCaRL 之所以行之有效的主要原因是使用了知识蒸馏(Knowledge diatillation)。并对于知识蒸馏存在的分类器偏差(bias in classifiers)问题,提出了动态阈值移动(dynamic threshold moving)算法。
1.引言
首先给出一个例子来理解增量学习的概念。假设你现在正走在一个花园中,你看见一种之前从未见过的花,然后你用手机上网查阅了相关资料,知道了这个花的种类,然后你继续往前走,又碰到一株玫瑰,这个时候你还能认出那是株玫瑰吗? 如果是人类,答案是肯定可以的。但是如果是神经网络,答案就不一定了,就算原先模型可以 100% 识别玫瑰,但是在学习分类新花的时候不再提供玫瑰的样本,学习完新花后模型也可能不能识别出玫瑰了。这个现象就是常说的灾难性遗忘。上面的例子也反应了人类学习与神经网络学习之间存在的很大问题,而增量学习的目的就是减少两者之间的差距。
本文主要关注的也是类增量的问题(class-incremental learning)
1.1 本文主要贡献:
1) 深入分析了 iCaRL: 证明其中的 NEM 之所以在 iCaRL 中有效是因为在训练过程中会出现偏差,而这个偏差可以通过阈值移动或者是使用更高的蒸馏问题来消除,因此 NEM 在增量分类器中不是必须的。而 iCaRL 中提到的样本集选择算法,本文也没有复现出它的有效性,[25] 也没有证明它的有效性。
2) 动态阈值移动算法: 本文提出了一种算法来计算出一个 scale vector 来修正使用蒸馏损失函数训练的分类器的偏差。因为知识蒸馏引起的偏差在原论文中有所提到,当时原论文也说了存在一个向量 S 可以用来修正偏差,但是文中并没有给出如何去求这个向量,本文提供了方法。
3)为将来的工作搭了框架: 我们开源了一个类增量的应用,使用它可以快速的在多个数据集上与现有的方法做对比。
2. 相关工作
[17]提出固定表征并使用 NCM 分类器,这可能在增加新分类的情况下不增加额外的开销;[12]提出了 zero-shot 的学习系统,可以无额外开销的学习新类。但是它们在特征提取这步都步适应新的数据,只能修改分类算法去配合新的分类。其他的方法主要分成以下 2 类:
(1) Rehearsal Based Incremental Learning
这类方法类似于联合训练,它们会将之前学习过的任务的数据分布以某种形式存储,再从中采用来防止灾难性遗忘。其中最有名的就是 iCaRL 了,它存储了前 K 个前面已经学习过的任务的样本,并使用蒸馏损失函数,使用类似于 LwF 的方式来保持旧任务的知识。[15] 也是最近提出的基于 rehearsal 的方法,但是它们都需要在测试的时候任务描述子都是可得的,这就限制了它们只能在特定的场景使用。
GANs 变得越来越流行,它可以存储数据的分布,[23]和[25] 都提出了使用 GANs 来做增量学习,它们使用 GANs 来生成之前任务的图像加入到新任务图像中一起训练来防止灾难性遗忘,但是由于现在 GANs 在复杂数据集上生成的图像质量还不是很好,所以表现还不是很好。
(2) Knowledge Preserving Incremental learning
第二种分类则是想要在学习新类的时候保留网络已经学习的知识。[20] 使用自动编码器来保存对之前任务有益的知识。通过欠完备自动编码器把每个任务的特征映射到低位空间中。[18] 通过固定模型前面和中间层的参数来减轻遗忘,但是这样模型在新任务上的的表征能力有限。其他的方法都是想要保留一些对之前学习过的任务重要的权重,让它们在学习新任务时更难被改变[27][10] 。最后 蒸馏损失函数[8] 得到了广泛的应用。[9]提出一个类似于人脑工作原理的方法来解决增量学习,但是他们使用了在 ImageNet 上已经训练的预训练模型作为特征提取器,并没有解决增量学习表征学习的问题。[22]和[26]提出了当新任务加进来网络也随之变大来防止改变对之前任务重要的参数,但是这种方法是无限增加没有内存上线的。
3-5
主要是重新介绍 iCaRL ,并通过设计实验说明 iCaRL 中的样本集选择算法和 NEM 分类器没有那么有效,主要的原因还是知识蒸馏。
6 动态阈值移动算法
为什么知识蒸馏会产生偏置?
假如一个动物分类器中的一个分类是鲸,其余的都是陆地动物,新的分类任务仍然是陆生动物,那么旧模型参数很可能就会在新类别的图片分类结果中在鲸这一类别的概率接近0 。这就会在鲸这一分类上产生偏差,导致这个分类性能下降。
阈值移动
这个方法原先是用在样本不均衡的情况下的,[3] 证明阈值移动可以有效的消除偏差。但是如何衡量样本均衡还是不均衡呢? [3] 中单纯就是通过计算每一类训练样本的数量关系,但是这里没办法使用这种情况。通过蒸馏损失函数的启发,这里单纯以最后每个类别对最终结果中所占的比重来计算消除偏差的 scale vector。
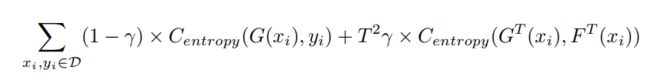
由[14] 可以得到下面的损失函数:
Centropy 是交叉熵损失函数,D是训练集,这里我们乘以温度 T2 。 这里我们使用一个尺度向量(scale vector)来移除 G(xi)的偏差:

这里的 S 实际上就是所有目标概率分布的和。
最后得到 G’(xi):

其中 o 表示点乘,因为 S 的计算公式和蒸馏函数形式很像,所以在训练时可能不需要额外的开销就可以快速计算出 S 。
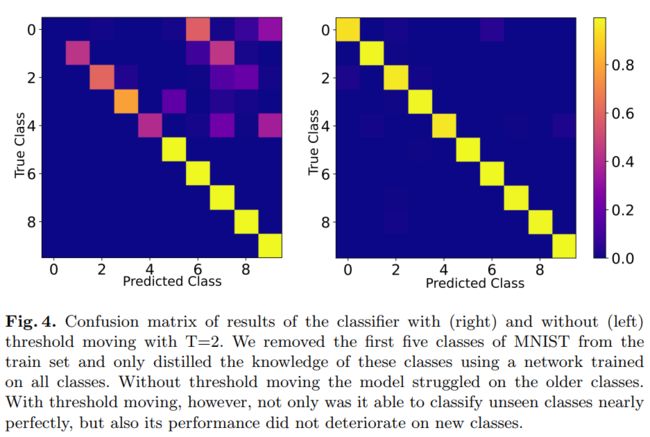
最后论文也给出了实验结果证明了阈值移动方法的有效性: