Convolutional Neural Networks for Visual Recognition——笔记1
该课程是计算机视觉大牛李菲菲等在2015年开设的关于deep learning在cv应用的课程,particularly 在image classification上。主要教授如何解决关于image recognition的问题,学习算法(例如back propagation),训练跟fine-tuning的trick等。课程网址:
http://vision.stanford.edu/teaching/cs231n/syllabus_winter2015.html
每节课都有slides、notes、assignment,其中notes解说的比较全面,可以配着slides一起看。
代码基于python编写的,网站中附带了python的学习教程,网页是:
http://cs231n.github.io/python-numpy-tutorial/
1,Image Classification
1)图像分类就是对给定的图片进行分类。对该图片分类的概率如图所示。

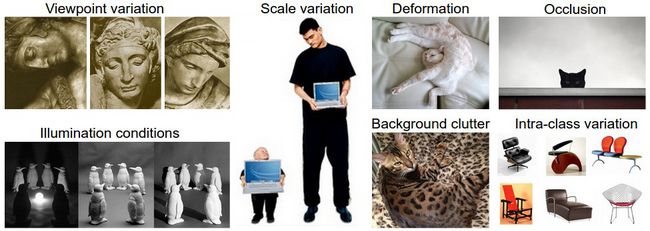
2)常见面临的挑战:
Viewpoint variation:拍摄角度不同引起的
Scale variation:尺度变化,真是世界中物体尺寸,而不是同一个物体由于拍摄距离造成在图片中呈现的尺寸变化,比如小猫咪,跟成年猫尺寸。
Deformation: 很多物体不是刚性物体,比如猫,跑的猫,蜷起来的猫等。
Occlusion:周围环境的遮挡。
Illumination conditions:光照变化引起的。
Background clutter:背景可能跟目标颜色纹理等接近,不容易在背景中判断出物体来
Intra-class variation:某一类物体有很多种类型的,图示为椅子,椅子有多种类型,但都为同一类——椅子。
3)数据驱动型方法
对每一类都收集一批数据提供给计算机去学习,依赖于事先收集的训练数据。
4)处理流水线
? Input :N张分别已经打标了的图,这些标签属于K个不同的类别,这样一组数据被称为训练集。
? Learning:从给定的训练集中学习出每一类的性质,可称为训练或学习阶段
? Evaluation:对一组从未见过的图进行分类,然后评估预测结果跟真实结果的差距,最终我们希望尽可能多的数据的预测结果与真实结果一致(数据的真实标签——ground truth)
2,Nearest Neighbor Classifier
最近邻分类器与CNN没有关系,在实际中也很少用到,但可以从这个方法了解图像分类的主要流程。
CIFAR10数据库:是一个比较流行的图像分类的数据库,包含10类图像,,图片大小都为32*32,数据总量为6w张,其中5w用于训练,1w用于测试,如下所示

现在给定了包含10类的5w张样本,其中每类5k张,我们希望预测剩余的1w张图。最近邻的方法是收到一张图后,将该图与训练集中的每一个样本进行比较,标记该图像的标签为离它最近的训练样本的类别。可以看上图,10个测试样本中只有3个预测正确。通过进行像素级的比较得到两张图像的距离。
每张图片都可视为一个高维 向量,两张图的距离可以用L1表示:
d1
(
I1
,
I2
)
=
∑p
|Ip1-Ip2|
还有一种距离:L2:
d2
(
I1
,
I2
)
=
∑p(Ip1-IP2 )2
L1跟L2的区别: L2更加平滑,L1更加鲁棒。
L2的距离在二维平面上看是两个点之间的距离,L2最小的时候是每一维的loss接近的时候,如果有个非点则L2的距离会变得很大,比如做跟踪中,物体被部分遮挡,被遮挡部分的loss则会变得很大,物体会逐步跟丢。
L1的距离在二维平面上是两个点之间的直线距离,鲁棒性更好,也是可以用物体被部分遮挡为例子,被遮挡部分可以视为非点,算出的距离要比L2小。
2,knn
knn是通过参考离测试样本最近的k个样本,根据投票结果给定当前样本的类别。当k= 1时,怎为nearest neighbor classifier
实际中K值如何选取?
1)Validation sets for Hyper parameter tuning
类似k的这里参数叫超参(hyper parameter),这些值的选取需要从数据中学习出来,但是we cannot use the test set for the purpose of tweaking hyperparameters。测试集只有在最后评估的时候用,不能将测试集用于调试最佳的hyper parameter,不然很容易过拟合。
Evaluate on the test set only a single time, at the very end.
通常可以将训练集分为两部分:一个少量训练样本用来选取最佳hyper parameter,这个集合叫Validation set;另外一个包含大量训练样本的集合叫training set。例如cifar10 用了4.9w张为traning set, 1k张做validation set。
当训练集比较小的时候,可以用cross-validation做参数选择。具体是:将训练样本分为5等份,采用1份做validation set,剩余为training set,多次迭代循环,评估性能。
实际应用中,由于cross-validation computationally expensive,会用一个固定的validation set。一般选取50%-90%作为training set,剩余的作为validation set,当然这个比例的选取要看看数据集的大小跟参数的个数。
2)Pros and Cons of Nearest Neighbor Classifier
▶简单,容易理解,不需要训练。
▶测试时间太长,对每个样本分类时需要与训练样本中的每个做比较。实际应用中,相对训练时间的效率,我们更关心测试时间的效率。
▶时间复杂度是nearest neighbor classifier的另一个研究点。Approximate nearest neighbor还有一些库比如flann都能对nearest neighbor的查找加速。这些方法在检索中会用准确率的降低换区时间空间的效率。一般是通过预处理,建立索引树的方法加速,例如建立kdtree, random kdtree。
▶还有一个缺点是,很少用于图片分类中,由于图像是高维对象,基于像素级的距离比较不直观,图像亮度变化,遮挡造成较大的l2的距离,但是这个距离不能对应直观或者语义上的距离。
关于给出的阅读链接的笔记,下次在写。