Hadoop-2.6.0完全分布式集群搭建和测试(一)
1.描述:
大数据平台环境搭建连载。
2.环境介绍
环境配置:
虚拟机:
vmware workstation 10.0.0
系统:
CentOS-6.5-x86_64
节点:
192.168.73.100 Master
192.168.73.101 Slave01
192.168.73.102 Slave02
JDK:
jdk-8u161-linux-x64.tar.gz
Hadoop:
hadoop-2.6.0.tar.gz3.Hadoop平台环境搭建步骤:
3.1安装虚拟机
第一步:点击“创建新的虚拟机”

第二步:点击“典型”
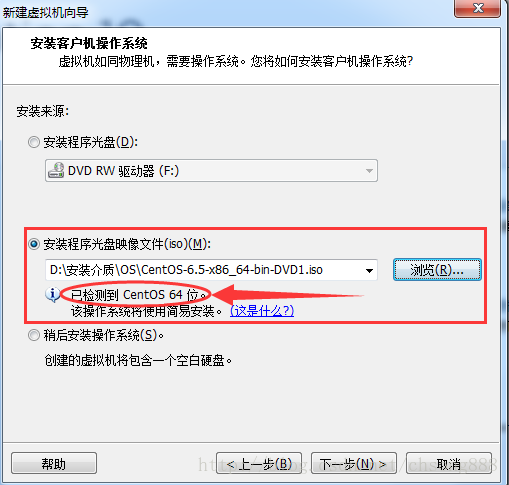
第三步:选择CentOS映像文件
注:安装的是64位操作系统,后面用到的Hadoop相关也要用64位。
第四步:输入要建的用户
第五步:输入虚拟机文件保存位置以及虚拟机名称
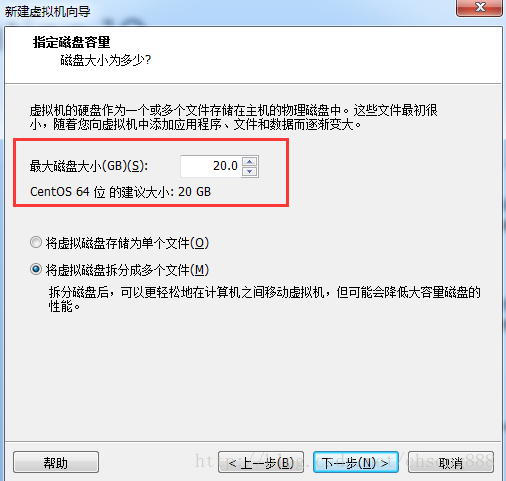
第六步:这里可以调整磁盘大小[我们保持默认]
第七步:按下一步完成开始安装
第八步:按第一步到第七步完成Slave01和Slave02安装
3.2系统调整
3.2.1登录系统
注:以下操作都是在下面的命令窗口执行:
3.2.2为hadoop用户加入sudo
按如下操作:
打开后按“i”键,按如图修改




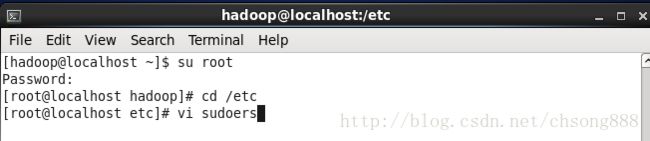

按“Esc”键,输入:wq! 保存退出
3.2.3修改启动项-改为不进入图形界面
输入如下命令:
[root@localhost etc]# vi inittab
如图修改:把5修改为3

3.2.4修改机器名
输入如下命令:
[root@localhost etc]# vi /etc/sysconfig/network
按如下修改:

注:机器名称一定不要加下划线,不然HADOOP是启动不起来的。
3.2.5修改主机名和IP的映射关系
输入如下命令:
[root@localhost etc]# vi /etc/hosts
按如下修改:
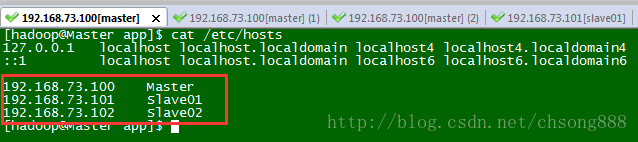
注:这里也把datanode节点的机器IP机器名对应关系配置上。
3.2.6关闭防火墙
输入如下命令:
查看防护墙状态
service iptables status
关闭
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭开机启动
chkconfig iptables off3.2.7修改网络设置
请参照:Vmware虚拟机设置静态IP地址[http://blog.csdn.net/chsong888/article/details/79358959]
注:以上系统设置请完成Slave01和Slave02设置
3.3安装JDK
3.3.1上传通过XFTP工具
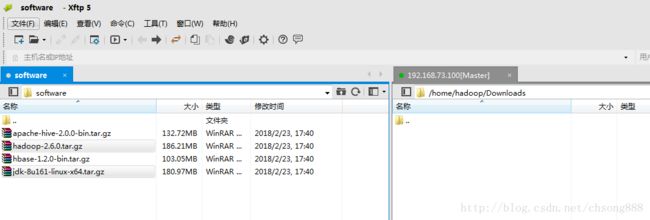
3.3.2解压
通过SecureCRT登录master节点机器,输入如下命令:
[hadoop@Master ~]$ cd Downloads/
[hadoop@Master Downloads]$ tar -zxvf jdk-8u161-linux-x64.tar.gz
[hadoop@Master Downloads]$ mv jdk1.8.0_161 /home/hadoop/app/
3.3.3配置环境变量
按如下操作执行:
[hadoop@Master Downloads]$ cd ..
[hadoop@Master ~]$ vi .bashrc
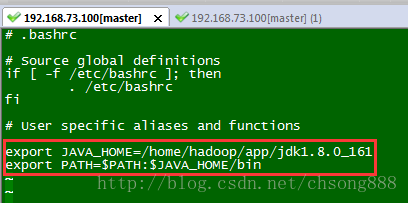
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
保存退出
使环境变量文件生效执行如下命令:
[hadoop@Master ~]$ source .bashrc
3.3.4验证
输入命令:[hadoop@Master ~]$ java -version
显示如下:
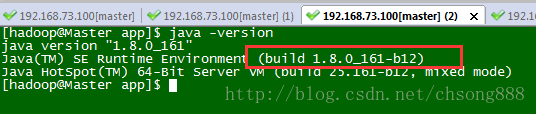
注:以上JDK设置请完成Slave01和Slave02设置
3.4安装HADOOP
3.4.1上传解压
第一步:上传
第二步:解压
通过SecureCRT登录master节点机器,输入如下命令:
[hadoop@Master ~]$ cd Downloads/
[hadoop@Master Downloads]$ tar -zxvf jdk-8u161-linux-x64.tar.gz
[hadoop@Master Downloads]$ mv jdk1.8.0_161 /home/hadoop/app/
第三步:新建目录
[hadoop@Master hadoop-2.6.0]$ mkdir dfs
[hadoop@Master hadoop-2.6.0]$ mkdir tmp
[hadoop@Master hadoop-2.6.0]$ cd dfs
[hadoop@Master dfs]$ mkdir name
[hadoop@Master dfs]$ mkdir data
3.4.2配置环境变量
按如下操作执行:
[hadoop@Master Downloads]$ cd ..
[hadoop@Master ~]$ vi .bashrc
在JAVA配置的环境变量的基础上修改如下:
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_161
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.4.3修改配置文件
如下操作:
[hadoop@Master ~]$ cd app/hadoop-2.6.0/etc/hadoop/
- 修改配置文件:hadoop-env.sh,指定JAVA_HOME
[hadoop@Master hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_161

- 修改配置文件:core-site.xml
[hadoop@Master hadoop]$ vi core-site.xml
如下修改:
fs.defaultFS
hdfs://Master:9000
io.file.buffer.size
8000
hadoop.tmp.dir
file:/home/hadoop/app/hadoop-2.6.0/tmp
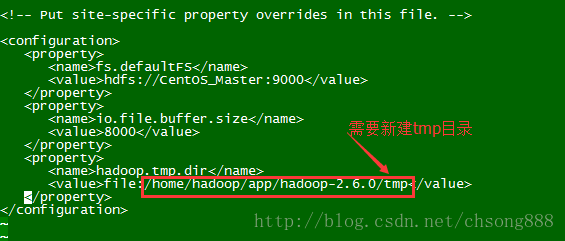
- 修改配置文件:hdfs-site.xml
[hadoop@Master hadoop]$ vi hdfs-site.xml
dfs.namenode.secondary.http-address
Master:9001
dfs.namenode.name.dir
file:/home/hadoop/app/hadoop-2.6.0/dfs/name
dfs.datanode.data.dir
file:/home/hadoop/app/hadoop-2.6.0/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
注:dfs.replication为保存副本数,建议最少设置为3

- 修改配置文件:slaves
[hadoop@Master hadoop]$ vi slaves
如下图
把datanode节点机器名写入
Slave01
Slave02

- 修改配置文件:yarn-env.sh
[hadoop@Master hadoop]$ vi yarn-env.sh
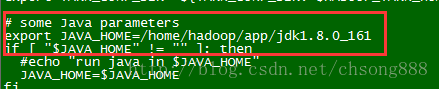
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_161
- 修改配置文件:yarn-site.xml
[hadoop@Master hadoop]$ vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
Master
yarn.resourcemanager.address
Master:8032
yarn.resourcemanager.scheduler.address
Master:8030
yarn.resourcemanager.resource-tracker.address
Master:8031
yarn.resourcemanager.admin.address
Master:8033
yarn.resourcemanager.webapp.address
Master:8088

- 修改配置文件:mapred-site.xml
[hadoop@Master hadoop]$ mv mapred-site.xml.template mapred-site.xml
[hadoop@Master hadoop]$ vi mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.webapp.address
Master:19888
mapred.job.tracker
Master:9001

3.4.4无密码登录配置
- 输入以下命令:
[hadoop@Master app]$ ssh-keygen -t rsa
一直回车
如下图
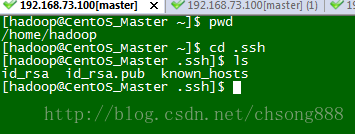
进入如下图目录
[hadoop@Master ~]$ pwd
/home/hadoop
[hadoop@Master ~]$ cd .ssh
[hadoop@Master .ssh]$ ls
id_rsa id_rsa.pub known_hosts
[hadoop@Master .ssh]$

- 输入如下命令:
[hadoop@Master .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 合并authorized_keys文件内容,把Master和Slave01以及Slave02此文件的内容合并,之后把此文件分别复制到各自的机器上
操作如下:
scp authorized_keys [email protected]:/home/hadoop/.ssh
scp authorized_keys [email protected]:/home/hadoop/.ssh
以上命令全在Master机器上执行
- 修改authorized_keys权限
分别进入到Slave01和Slave02执行以下命令
[hadoop@Slave01 .ssh]$ chmod 600 authorized_keys
- 检查是否可以无密码登录:

3.4.5同步HADOOP到DATANODE节点
在Master机器上执行以下命令:
[hadoop@Master ~]$ cd app
[hadoop@Master app]$ scp -r hadoop-2.6.0 hadoop@Slave01:/home/hadoop/app
[hadoop@Master app]$ scp -r hadoop-2.6.0 hadoop@Slave02:/home/hadoop/app
分配进入到Slave01和Slave02对HADOOP环境变量进行配置,请参照3.4.2配置环境变量
3.4.5文件系统格式化
执行以下命令:
[hadoop@Master bin]$ hdfs namenode -format

显示成功
3.4.6启动服务验证
在Master机器上执行:
[hadoop@Master sbin]$ start-all.sh

Master 机器如下显示:

Slave机器如下显示:

如上显示则启动成功
可以登录web界面查看地址:http://192.168.73.100:50070
显示如下:
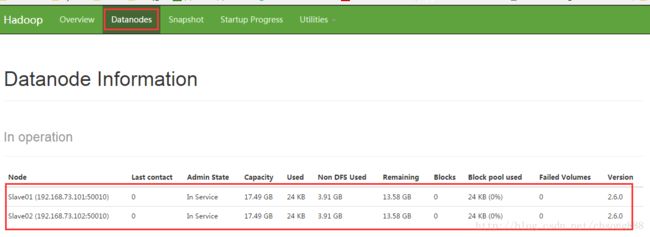
3.5测试HADOOP
这里以HADOOP自带的wordcount为例!
3.5.1新建测试目录
1.执行以下命令:
[hadoop@Master hadoop-2.6.0]$ hadoop fs -mkdir -p /data/input
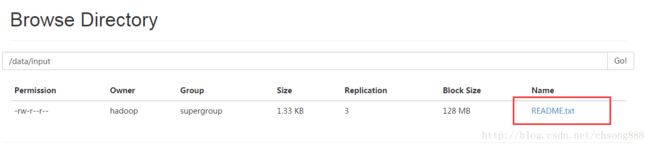
2.把HADOOP下面的README.txt上传到HDFS刚建的input目录中执行命令如下:
[hadoop@Master hadoop-2.6.0]$ hadoop fs -put README.txt /data/input
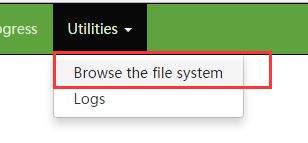
可以通过WEB页面查看
地址:http://192.168.73.100:50070
显示如下:
进入如下目录执行命令:
cd /home/hadoop/app/hadoop-2.6.0/share/hadoop/mapreduce
开始运行mapreduce例子执行如下命令:
[hadoop@Master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount /data/input /data/output/result
显示如下:

查看运行结果:
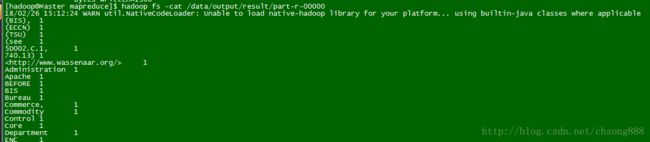
如图前面显示单词,后面是个数。
安装成功!!
3.5总结
本次安装遇到两个坑:
1、机器名称不能有下划线
2、hosts配置问题,在里面不要加入固定IP地址和机器名称对应关系。如下
node1节点:
192.168.73.101 localhost
192.168.73.101 Slave01
node2节点:
192.168.73.102 localhost
192.168.73.102 Slave02
如果上面按这样配置的话在Datanode Information中就会只显示一个节点。