java实现敏感词过滤 dfa算法实现
文章标题:DFA算法实现敏感词过滤的demo
假如在我们的敏感词库中存在如下几个敏感词:日本人、日本鬼子、毛.泽.东。那么我需要构建成一个什么样的结构呢?
首先:query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}。形如下结构:

下面我们在对这图进行扩展:

这样我们就将我们的敏感词库构建成了一个类似与一颗一颗的树,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如我们要判断日本人,根据第一个字我们就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
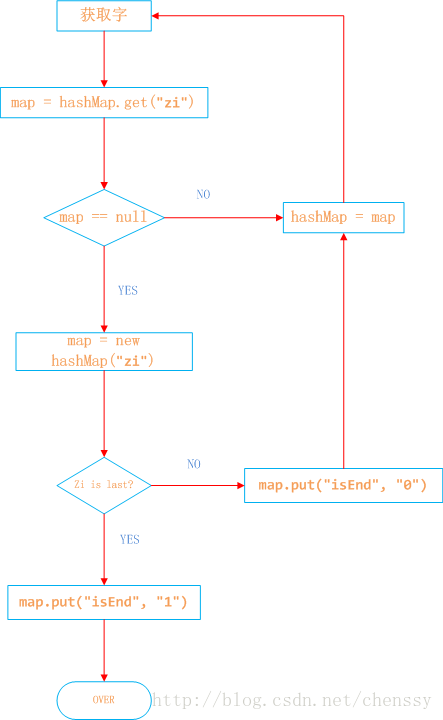
但是如何来判断一个敏感词已经结束了呢?利用标识位来判断。
所以对于这个关键是如何来构建一棵棵这样的敏感词树。下面我已Java中的HashMap为例来实现DFA算法。具体过程如下:
日本人,日本鬼子为例
1、在hashMap中查询“日”看其是否在hashMap中存在,如果不存在,则证明已“日”开头的敏感词还不存在,则我们直接构建这样的一棵树。跳至3。
2、如果在hashMap中查找到了,表明存在以“日”开头的敏感词,设置hashMap = hashMap.get("日"),跳至1,依次匹配“本”、“人”。
3、判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位isEnd = 1,否则设置标志位isEnd = 0;
2.给censorword.txt 添加内容
censorword.txt中的词就是你要过滤的敏感词
例如:
(注意首尾要添加空行)
3.各个实现类
<1.>SensitiveWordInit.java
【注意!!!!,在这个类 readSensitiveWordFile()
方法中一定要把敏感词库的路径配置正确】
package com.sunchuang.sensitiveword;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
//屏蔽敏感词初始化
@SuppressWarnings({ "rawtypes", "unchecked" })
public class SensitiveWordInit {
// 字符编码
private String ENCODING = "UTF-8";
// 初始化敏感字库
public Map initKeyWord() {
// 读取敏感词库 ,存入Set中
Set
// 将敏感词库加入到HashMap中//确定有穷自动机DFA
return addSensitiveWordToHashMap(wordSet);
}
/**
* 读取敏感词库,将敏感词放入HashSet中,构建一个DFA算法模型:
* 中 = {
* isEnd = 0
* 国 = {
* isEnd = 1
* 人 = {isEnd = 0
* 民 = {isEnd = 1}
* }
* 男 = {
* isEnd = 0
* 人 = {
* isEnd = 1
* }
* }
* }
* }
* 五 = {
* isEnd = 0
* 星 = {
* isEnd = 0
* 红 = {
* isEnd = 0
* 旗 = {
* isEnd = 1
* }
* }
* }
* }
* @author 孙创
* @date 2017年2月15日 下午3:20:20
* @param keyWordSet 敏感词库
*/
// 读取敏感词库 ,存入HashMap中
private Set
Set
// app为项目地址
/*
* String app = System.getProperty("user.dir"); System.out.println(app);
* URL resource = Thread.currentThread().getContextClassLoader()
* .getResource("/"); String path = resource.getPath().substring(1);
* System.out.println(path); File file = new File(path +
* "censorwords.txt");
*/
//敏感词库
File file = new File(
"D:/workspace/SensitiveWordDeal/resources/censorwords.txt");
try {
// 读取文件输入流
InputStreamReader read = new InputStreamReader(new FileInputStream(
file), ENCODING);
// 文件是否是文件 和 是否存在
if (file.isFile() && file.exists()) {
wordSet = new HashSet
// StringBuffer sb = new StringBuffer();
// BufferedReader是包装类,先把字符读到缓存里,到缓存满了,再读入内存,提高了读的效率。
BufferedReader br = new BufferedReader(read);
String txt = null;
// 读取文件,将文件内容放入到set中
while ((txt = br.readLine()) != null) {
wordSet.add(txt);
}
br.close();
/*
* String str = sb.toString(); String[] ss = str.split(","); for
* (String s : ss) { wordSet.add(s); }
*/
}
// 关闭文件流
read.close();
} catch (Exception e) {
e.printStackTrace();
}
return wordSet;
}
// 将HashSet中的敏感词,存入HashMap中
private Map addSensitiveWordToHashMap(Set
// 初始化敏感词容器,减少扩容操作
Map wordMap = new HashMap(wordSet.size());
for (String word : wordSet) {
Map nowMap = wordMap;
for (int i = 0; i < word.length(); i++) {
// 转换成char型
char keyChar = word.charAt(i);
// 获取
Object tempMap = nowMap.get(keyChar);
// 如果存在该key,直接赋值
if (tempMap != null) {
nowMap = (Map) tempMap;
}
// 不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
else {
// 设置标志位
Map
newMap.put("isEnd", "0");
// 添加到集合
nowMap.put(keyChar, newMap);
nowMap = newMap;
}
// 最后一个
if (i == word.length() - 1) {
nowMap.put("isEnd", "1");
}
}
}
return wordMap;
}
}
<2.>SensitiveFileterService.java
package com.sunchuang.sensitiveword;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
//敏感词过滤器:利用DFA算法 进行敏感词过滤
@SuppressWarnings("rawtypes")
public class SensitiveFilterService {
private Map sensitiveWordMap = null;
// 最小匹配规则
public static int minMatchTYpe = 1;
// 最大匹配规则
public static int maxMatchType = 2;
// 单例
private static SensitiveFilterService instance = null;
// 构造函数,初始化敏感词库
private SensitiveFilterService() {
sensitiveWordMap = new SensitiveWordInit().initKeyWord();
}
// 获取单例
public static SensitiveFilterService getInstance() {
if (null == instance) {
instance = new SensitiveFilterService();
}
return instance;
}
// 获取文字中的敏感词
public Set
Set
for (int i = 0; i < txt.length(); i++) {
// 判断是否包含敏感字符
int length = CheckSensitiveWord(txt, i, matchType);
// 存在,加入list中
if (length > 0) {
sensitiveWordList.add(txt.substring(i, i + length));
// 减1的原因,是因为for会自增
i = i + length - 1;
}
}
return sensitiveWordList;
}
// 替换敏感字字符
public String replaceSensitiveWord(String txt, int matchType,
String replaceChar) {
String resultTxt = txt;
// 获取所有的敏感词
Set
Iterator
String word = null;
String replaceString = null;
while (iterator.hasNext()) {
word = iterator.next();
replaceString = getReplaceChars(replaceChar, word.length());
resultTxt = resultTxt.replaceAll(word, replaceString);
}
return resultTxt;
}
/**
* 获取替换字符串
*
* @param replaceChar
* @param length
* @return
*/
private String getReplaceChars(String replaceChar, int length) {
String resultReplace = replaceChar;
for (int i = 1; i < length; i++) {
resultReplace += replaceChar;
}
return resultReplace;
}
/**
* 检查文字中是否包含敏感字符,检查规则如下:
* 如果存在,则返回敏感词字符的长度,不存在返回0
*
* @param txt
* @param beginIndex
* @param matchType
* @return
*/
public int CheckSensitiveWord(String txt, int beginIndex, int matchType) {
// 敏感词结束标识位:用于敏感词只有1位的情况
boolean flag = false;
// 匹配标识数默认为0
int matchFlag = 0;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++) {
char word = txt.charAt(i);
// 获取指定key
nowMap = (Map) nowMap.get(word);
// 存在,则判断是否为最后一个
if (nowMap != null) {
// 找到相应key,匹配标识+1
matchFlag++;
// 如果为最后一个匹配规则,结束循环,返回匹配标识数
if ("1".equals(nowMap.get("isEnd"))) {
// 结束标志位为true
flag = true;
// 最小规则,直接返回,最大规则还需继续查找
if (SensitiveFilterService.minMatchTYpe == matchType) {
break;
}
}
}
// 不存在,直接返回
else {
break;
}
}
if (matchFlag < 2 && !flag) { // 长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
}
<3.>Main.java
package com.sunchuang.sensitiveword;
public class Main {
public static void main(String[] args) {
SensitiveFilterService filter = SensitiveFilterService.getInstance();
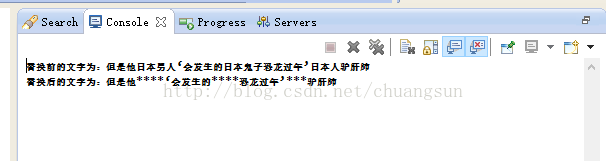
String txt = "但是他日本男人‘会发生的日本鬼子恐龙过年’日本人驴肝肺";
String hou = filter.replaceSensitiveWord(txt, 1, "");
System.out.println("替换前的文字为:" + txt);
System.out.println("替换后的文字为:" + hou);
}
}
4.运行结果
这样就大功告成了