规则引擎学习分享
对于企业级应用来说,在IT技术领域,很多地方也应用了规则,比如路由表,防火墙策略,乃至角色权限控制(RBAC),或者Web框架中的URL匹配。不管是那种规则,都规定了一组确定的条件和此条件所产生的结果。每条规则都是一组条件决定的一系列结果,一条规则可能与其他规则共同决定最终结果,可能存在条件互相交叉的规则,此时有必要规定规则的优先级。规则的运用过程叫做推理,如果由程序来处理推理过程,那么这个程序叫做推理引擎。
基于规则的推理机易于理解,易于获取,易于管理,成为规则引擎。
1.1 应用场景理解
应用题
可乐瓶兑换规则,小明手上有50块钱,1元钱可以买一瓶冰红茶,2个空瓶可以兑换一瓶饮料,问题是小明可以喝多少瓶饮料?
规则rule:

1.2 规则引擎相关介绍
1.2.1 规则引擎介绍
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
1.2.2 规则引擎应用背景
企业级管理者对企业IT系统的开发有着如下的要求:
1.为提高效率,管理流程必须自动化,即使现代商业规则异常复杂。
2.市场要求业务规则经常变化,IT系统必须依据业务规则的变化快速、低成本的更新。
3.为了快速、低成本的更新,业务人员应能直接管理IT系统中的规则,不需要程序开发人员参与。
1.2.3 规则引擎优点
使用规则引擎可以通过降低实现复杂业务逻辑的组件的复杂性,降低应用程序的维护和可扩展性成本,其优点如下:
· 分离商业决策者的商业决策逻辑和应用开发者的技术决策;
· 能有效的提高实现复杂逻辑的代码的可维护性;
· 在开发期间或部署后修复代码缺陷;
· 应付特殊状况,即客户一开始没有提到要将业务逻辑考虑在内;
· 符合组织对敏捷或迭代开发过程的使用;
1.3 规则引擎的常见的技术
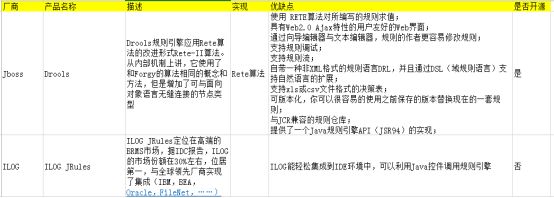
1.4 规则引擎的原理实现
1.4.1 规则引擎的原理实现
规则引擎起源于规则的专家系统,基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴。
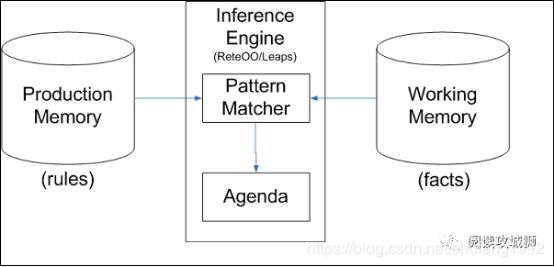
推理引擎(Inference Engine)包括三部分:模式匹配器(Pattern Matcher)、议程(Agenda)和执行引擎(Execution Engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。
在规则引擎中,将知识表达为规则(rules),要分析的情况定义为事实(facts)。二者在内存中的存储分别称为Production Memory和Working Memory。
rules和facts是规则引擎接受的输入参数,而规则引擎本身包括两个组成部分:Pattern Matcher和Agenda。Pattern Matcher根据facts找到匹配的rules,Agenda管理PatternMatcher挑选出来的规则的执行次序。在外围,还会有一个执行引擎(Execution Engine)负责根据Agenda输出的rules执行具体的操作。
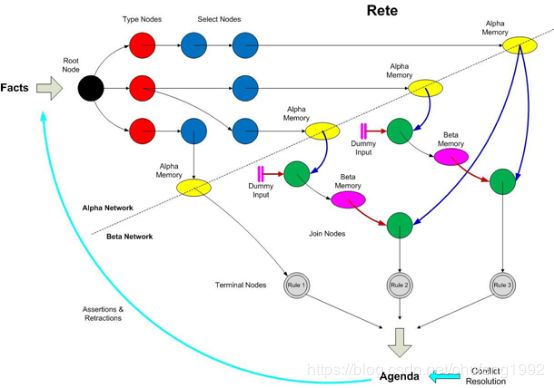
1.4.2 Rete算法
规则引擎的核心是Pattern Matcher(模式匹配器),任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题,规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。常见的模式匹配算法包括Rete、Treat、Leaps等,其中Rete算法使用正向推理,在目前商用/开源规则引擎产品中广泛使用。Rete算法是目前效率最高的一个前向链形推理算法, 其核心思想是将分离的匹配项根据内容动态构造匹配树, 以达到显著降低计算量的效果。Rete算法的基本思想是:在模式匹配中利用推理机的时间冗余性和规则结构的相似性, 通过保存中间去处来提高推理效率的一种模式匹配算法,保存过去匹配过程中留下的全部信息,以空间代价来换取产生式系统的执行效率。
以下面的规则为例解释Rete算法:
RULE1:if (A>B) and D or C then E=100
RULE2:if (A>B) and (B
RULE3:if (! (A>B) or (B
若要匹配这3条规则时,,对于表达式A>B要进行三次计算,,对B
RULE1:if (M1) and D or C then E=100
RULE2:if (M1) and (M2) then E=200
RULE3:if (! (M1) or (M2) ) then E=300
这样只有当A或B发生变化时,才重新计算M1;同样当B或C发生变化时,重新计算M2。这样的推理避免了在每次进行模式匹配都重复计算相同的表达式,而只要检测相关参数是否变化来决定是否更新表达式,这样在推理过程中节省了大量时间和开销,从而提高了推理效率。
RETE推理网络的生成过程:从规则集{规则1,规则2……..}中拿出一条来,根据一定算法,变成RETE推理网络的节点。不断循环将所有规则都处理完,RETE推理网络就生成了。
参考文档:http://www.cnblogs.com/shangxiaofei/p/6262107.html
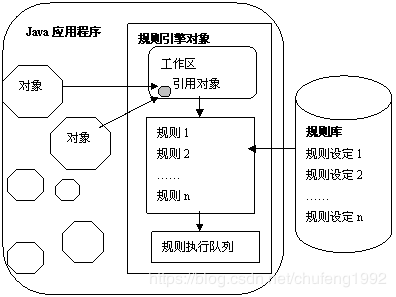
1.4.3 规则引擎的执行过程
Java规则引擎对提交给引擎的Java数据对象进行检索,根据这些对象的当前属性值和它们之间的关系,从加载到引擎的规则集中发现符合条件的规则,创建这些规则的执行实例。这些实例将在引擎接到执行指令时、依照某种优先序依次执行。一般来讲,Java规则引擎内部由下面几个部分构成:工作内存(Working Memory)即工作区,用于存放被引擎引用的数据对象集合;规则执行队列,用于存放被激活的规则执行实例;静态规则区,用于存放所有被加载的业务规则,这些规则将按照某种数据结构组织,当工作区中的数据发生改变后,引擎需要迅速根据工作区中的对象现状,调整规则执行队列中的规则执行实例。Java规则引擎的结构示意图如下图所示。
1.5 Drools介绍
1.5.1 Drools的安装 略
1.5.2 Drools的介绍
理解Drools工作过程,通常一个接口来做事,首先传进去参数,其次要获取接口实现执行完毕的结果。Drools也是一样,我们需要传递进去数据,用于规则的检查,调用外部接口,同时还可能需要获取到规则执行完毕后的结果。在Drools中,传递进去的对象,叫做Fact对象,是一个普通的java bean, 规则中科院对当前对象进行任何的读写操作,调用该对象提供的方法,当一个java bean插入到workingMemory中,规则使用的是原有对象的引用,规则通过对fact对象的读写,实现对应用数据的读写,对于其中的属性,需要提供getter setter访问器,规则中,可以动态的往当前的workingMemory中插入删除新的fact对象。
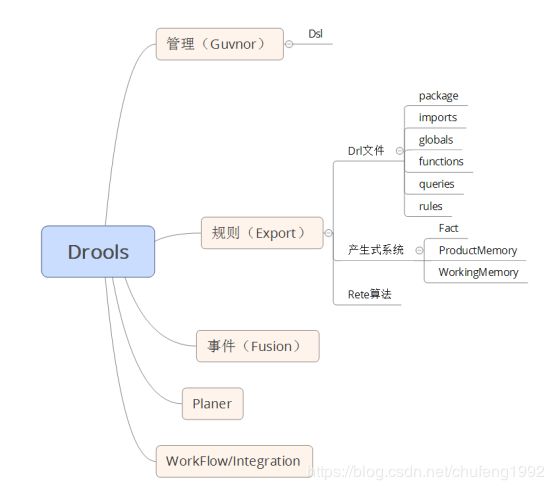
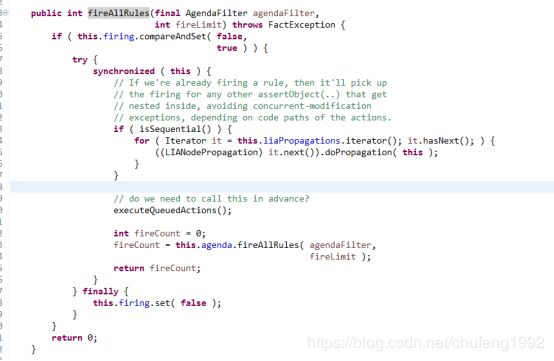
1.5.3 Drools源码分享
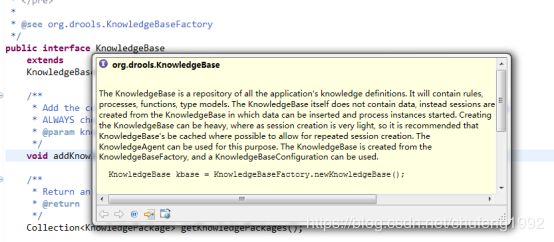
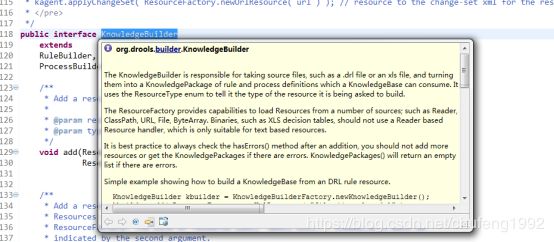
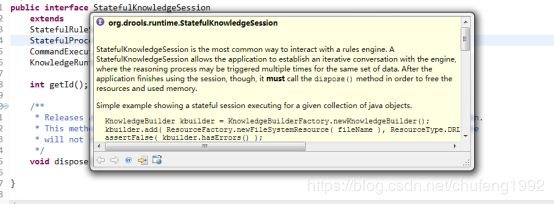
1.6 规则引擎使用场景
积分规则
计费
信用风险评估
监控告警系统
工作流系统
文章仅作为学习参考,如有侵权请联系作者删除。