【论文解读】yolo-v2
介绍
作者在yolo的基础上进行改进,提出了yolov2。此外,作者还提出了一种目标检测与分类的联合训练方法,允许在检测和分类数据集中训练目标检测系统。

图:yolo网络架构
Batch Normalization
在YOLO所有的卷积层后面添加了NB,在不需要其它形式的正则化的情况下NB极大地加速了收敛,并且不用dropout也不会出现过拟合,mAP获得了%2的提升。
High Resolution Classifier
所有牛逼的检测方法都使用了在ImageNet预训练好的分类器,从AlexNet开始绝大多数的分类器的输入图片的尺寸小于256 x 256。yolo训练分类网络的输入图片为224 x 224,检测部分分辨变为448 x 448。这也就是意味着网络需要调整以适应新的分辨率。
在YOLOv2中作者首先fine tune分类网络,分辨率为448 x 448,在ImageNet上训练10个epochs。然后再对检测部分的网络也进行fine tune。通过提升输入分辨率,mAP获得了约4%的提升。
Convolutional With Anchor Boxes
yolo在卷积网络之后使用全连接网络直接预测出边框的坐标,这种方法丢失了很多的空间信息。Faster-RCNN中使用RPN网络对每个anchor boxs预测出偏置以及目标置信度,这种思路让问题变得更简单且易于学习。yolov2正是借鉴了这种思路,它移出了yolo中的全连接网络层,使用anchor boxes来预测bounding boxes。
Dimension Cluster
在yolo中使用anchor box遇到了两个问题。第一个是anchor box的维度(宽高)是手工精选的,虽然网络也会学习去调整,但是如果能在一开始就挑出更合适的anchor box维度,将更方便网络去学习调整。作者抛弃手工精选的方式,而是在训练集bouding boxes上采用k均值聚类(k-means clustering)的办法来自动找到更好的boxs。传统的K-means聚类方法使用的是欧氏距离函数,也就意味着较大的boxes会比较小的boxes产生更多的error,聚类结果可能会偏离。为此,作者采用的评判标准是IOU得分(也就是boxes之间的交集除以并集),这样的话,error就和box的尺度无关了,最终的距离函数为:
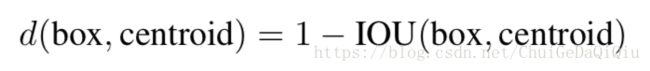
faster-rcnn中k设置为9,宽度比例设置为1:1,1:2,2:1。为什么k要设置为9,为什么宽高比例为如此设置,这个是人工经验选择的结果。而在这篇论文中,作者对VOC和COCO中训练集的ground truth进行了聚类统计(使用k-means clustering)。k由1依次递增,IOU上升较快,权衡召回率和复杂度最终k选择5。下图右边部分就是5种不同宽高比的anchor box。

补充:bounding boxs的k均值聚类具体怎么算?将每个bbox的宽和高相对整张图片的比例(wr,hr)进行聚类,这不就相当于针对n个向量进行一个聚类嘛,得到k个anchor box。
Direct location prediction
在yolo上使用anchor boxs的第二个问题就是模型不稳定,尤其在早期迭代的时代。这个不稳定性主要来自于对box位置(x,y)的预测。在RPN中,网络预测出tx和ty,然后(x,y)坐标可以通过计算得到:
![]()
例如,当tx=1时,预测box将向右移动Wa这么长的距离(也就是一个box的宽度),同样当tx=-1时将向左移动一个box的宽度。但是,这里并没有对tx,ty进行限制,也就是是这个box实际上可以移动到任意位置,也就意味着预测box可以出现在任意位置。作者认为导致模型变得不稳定,尤其在早期迭代阶段。anchor box应该只需要检测它周围正负一个单位的目标就可以了。因此,作者就没有采用预测offset的方法,而使用了预测相对于grid cell的坐标位置的办法,作者又把ground truth限制在了0到1之间,利用logistic回归函数来进行这一限制。现在,神经网络在特征图(13 *13 )的每个cell上预测5个bounding boxes(聚类得出的值),同时每一个bounding box预测5个坐值,分别为 tx,ty,tw,th,to。其中前四个是坐标,to是置信度。(cx,cy)为cell相对于图像左上角的坐标,总结来看可以按如下公式计算出预测box实际位置和大小。
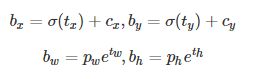
以下图补充说明,(cx,cy)为cell的左上角坐标(1,1)。由于sigmoid函数的处理,预测box的中心位置会约束在当前cell内部,防止偏移过多。而Pw和Ph是先验(也就是Anchor box)的宽度与长度,他们的值也是相对于特征图大小的,在特征图中每个cell的长和宽都为1。这里记特征图的大小为(W,H)(论文中给出的是13 x 13),这样我们可以将预测box相对于整张图片的位置和大小计算出来。

将上面的4个值分别乘以图片的宽度和长度(这次是像素点)就可以得到预测box在图像中的最终位置和大小了。约束了边界框的位置预测使得模型训练更容易也更稳定,结合聚类分析得到的先验Anchor box,Yolov2的mAP值提升了约5%。
Fine-Grained Features
yolov1在13x13大小(输入为416x416,经过5次max pooling后降为1/32)的特征图上进行目标检测,13x13大小的特征图对于大物体来说足够了,但是对于小物体而言还需要更精细的特征图。yolov2提出了passthrough层来利用更精细的特征图。yolov2将26x26大小的特征图连接到13x13的特征图上。passthrough层抽取前面层的每2x2的局部区域,然后将其转化为channel维度,对于26x26x512的特征图,经过passthrough层处理后变成了13x13x2048的新特征图,这样再和后面的13x13x1024特征图进行拼接形成13x13x3072大小的特征图,再在此特征图上进行卷积操作。以下为passthrough抽取示例:
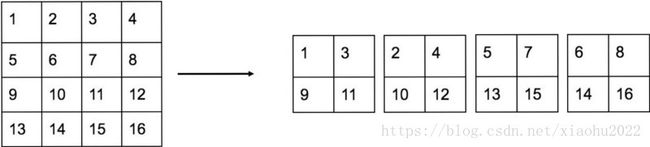
补充:关于passthrough layer,具体来说就是特征重排(不涉及到参数学习),对前面26x26x512的特征图使用按行和按列间隔采样的方法就可以得到4个新的特征图,维度都是13x13x512,然后再做channel维度的concat操作,得到13x13x2048的特征图,并将其拼接到后面的层,相当于做了一次特征融合,有利于检测小目标。
Training for detection
移除了最后一层卷积层,增加3个3x3x1024的卷积层,最后再跟一个1x1的卷积层。把最后一个3x3x512的卷积层旁路到倒数第二个卷积层以便模型可以精调细粒度特征。
