【论文解读】SSD vs YOLOv2
引言
对于一阶段的网络模型来说SSD和YOLOv2无疑占据着极为重要的位置,在实际工作上常常会拿这两种模型进行对比,在这里干脆梳理一下其差异,以加深对两者的认识。
多尺度
SSD采用多尺度特征图用于目标检测,具体说来就是选用了6个特征图,分别是:conv4_3,conv7,conv8_2,conv9_2,conv10_2和conv11_2的输出来进行检测。通过结合不同分辨率的特征图进行预测,以适应不同大小的目标。

YOLOv2提出了一种passthrough层来利用更精细的特征图,passthrough层与ResNet网络的shortcut类似,添加了一个转移层(类似resnet),passthrough层要把浅层特征图(26 x 26 x 512)连接到深层特征图(13 x 13 x 1024)上,连接的方式是在通道这个维度上的进行拼接,而不是空间位置上的累加。关于passthrough layer,具体来说就是特征重排(不涉及到参数学习),前面26 x 26 x 512的特征图使用按行和按列隔行采样的方法,就可以得到4个新的特征图,维度都是13 x 13 x 512,然后进行concat操作,得到13 x 13 x 2048的特征图,将其拼接到后面的层,最终得到一个13 x 13 x 3072大小的特征图,相当于做了一次特征融合,然后在此基础上进行卷积预测。
有利于检测小目标。
Anchor的设计
SSD和YOLOv2都采用了Anchor策略,SSD中先验框的宽高比例(aspect ratio)是手动设定的,带有一定的主观性。而YOLOv2是采用k-means聚类方法,对训练集中所有的边界框做了聚类分析。按作者的话来说,虽然你不这么做先验框本身也能够自适应,但是如果在一开始就为网络设定更合理的先验框,将使学习变得更加容易。具体如何进行聚类分析,考虑到设置先验框的目的是为了使得预测框与gt的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:d(box,centroid) = 1 - IOU(box, centroid)。YOLOv2中最终选取了5个聚类中心作为先验框。至于SSD,因为它会在6个特征图上进行预测,而每个特征上都要应用Anchor策略,并且不同特征图上Anchor的数目非固定。论文中给出的情况是conv4_3、conv10_2和conv11_2有4种,conv7、conv8_2和conv9_2有6种。
预测值
SSD和YOLOv2对于每个cell的各个anchor都输出一套独立的检测值。对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度,第二部分是边界框的location。第一部分的分类置信度,SSD和YOLOv2的区别在于SSD将背景也当做一个特殊的类别,所以如果检测目标共有c个类别,SSD其实需要预测c+1个置信度,其中第一个置信度就是指的背景或者说是不包含目标的评分。第二部分关于边框的location,通常都是4个坐标,但是就是这4个坐标常常是让人摸不清头脑。先来说说SSD。它预测的4个值![]() ,分别表示边框的中心坐标以及宽高。要特别注意的是模型出来的预测值只是边框相对于先验框的转换值。先验框位置用
,分别表示边框的中心坐标以及宽高。要特别注意的是模型出来的预测值只是边框相对于先验框的转换值。先验框位置用![]() 表示,其对应边框用
表示,其对应边框用![]() 表示,那么边框的预测值
表示,那么边框的预测值![]() 其实是
其实是![]() 相对于
相对于![]() 的转换值:
的转换值:

上面这个过程可以理解为边框位置的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测值![]() 中得到边框的真实位置
中得到边框的真实位置![]() :
:
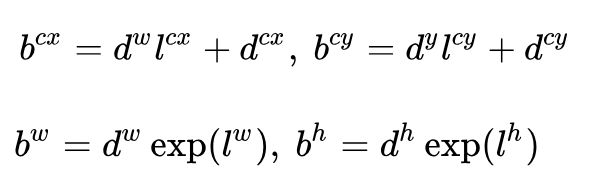
YOLOv2的作者对上面这种方式做了分析,指出这种编码的方式实际上是无约束的,例如当![]() =1时,边框相当于是向右偏移先验框一个宽度的大小,而
=1时,边框相当于是向右偏移先验框一个宽度的大小,而![]() =-1时,边框将向左偏移先验框一个宽度的大小,可想而知每个位置预测的边框其实可以落在图片的任何位置,这容易导致模型的不稳定性,YOLOv2于是改用预测边框中心点相对于对应单元格(cell)左上角位置的相对偏移值的方式,目的是为了将边框中心点约束在当前cell。使用sigmoid函数来处理偏移值,这样预测的偏移值就锁定在(0,1)范围内(每个cell的尺度看做1)。根据边框预测的4个值
=-1时,边框将向左偏移先验框一个宽度的大小,可想而知每个位置预测的边框其实可以落在图片的任何位置,这容易导致模型的不稳定性,YOLOv2于是改用预测边框中心点相对于对应单元格(cell)左上角位置的相对偏移值的方式,目的是为了将边框中心点约束在当前cell。使用sigmoid函数来处理偏移值,这样预测的偏移值就锁定在(0,1)范围内(每个cell的尺度看做1)。根据边框预测的4个值![]() ,可以按如下公式计算出边框实际位置和大小:
,可以按如下公式计算出边框实际位置和大小:
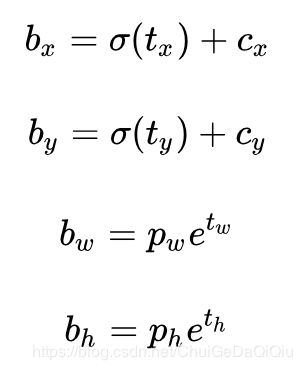
其中![]() 为cell左上角坐标(注意是相对坐标)。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。而 和 是先验框的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为(w,h),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
为cell左上角坐标(注意是相对坐标)。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。而 和 是先验框的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为(w,h),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):

如果将上面的4个值分别乘以图片的宽度和长度(像素值),就可以得到边框的最终位置和大小了。
损失函数
SSD的损失是位置损失(如:Smooth L1)和分类置信度损失(如: Softmax)的加权和。
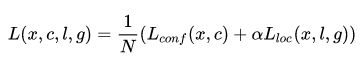
其中N是正样本的数量。这里顺带引出一个问题,SSD是如何划分正负样本的?我们知道SSD是一种Anchor(先验框)-based检测方法,在训练过程中gt框由与之匹配的先验框负责预测它,这些先验框也就是正样本。具体说来,SSD的先验框与gt的匹配原则主要有两步:(1).遍历图片中的每个gt(i),找到与其IOU最大的先验框(j),訪先验框(j)即与其(i)匹配。就这一步就可以保证每个gt一定会有一个与之匹配的先验框,这些先验框(确切地说是这些先验框对应的预测框)当然也就是正样本。反之,如果一个先验框没有与任何gt匹配,那它就是负样本。但是这样得到的正样本也太少了,因为一个图片中的gt就那么点,所以才有了第2步。(2).对于第1步剩余的未匹配上任何gt的先验框,若和某个gt的IOU大于一个给定的阈值(通常是0.5),那么訪先验框也认为是与訪gt匹配的,它也算作是正样本。显然,这样一来一个gt框就可能有与之匹配的多个先验框,意思就是可能有多个先验框是用来预测同一个目标。即使经历了这两步,但是gt相对先验框的数量而言还是太少了,因此负样本会明显多于正样本,为了保证正负样本尽量平衡,SSD采用了hard negative mining(难样本挖掘),就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。好了,继续回到损失函数上面来。![]() 为一个批示参数,为1时表示第i个先验框与第j个gt匹配,并且gt的类别为p。c为类别置信度预测值。
为一个批示参数,为1时表示第i个先验框与第j个gt匹配,并且gt的类别为p。c为类别置信度预测值。![]() 为先验框所对应边界框的位置预测值,而g是gt的位置参数,对于位置损失,采用Smooth L1 Loss,定义如下:
为先验框所对应边界框的位置预测值,而g是gt的位置参数,对于位置损失,采用Smooth L1 Loss,定义如下:
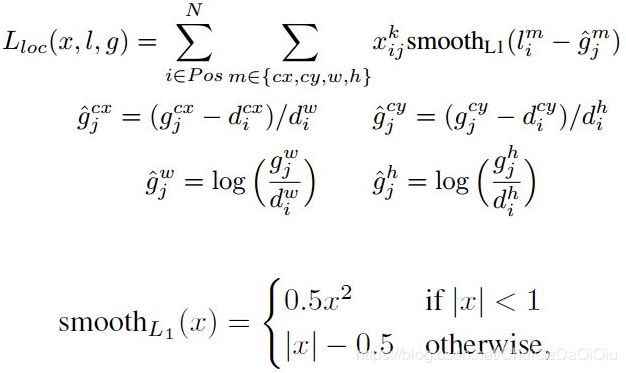
由于![]() 的存在,所以位置损失实际上是只针对正样本进行计算。对于置信度误差,采用的是softmax loss,这个就比较简单了。
的存在,所以位置损失实际上是只针对正样本进行计算。对于置信度误差,采用的是softmax loss,这个就比较简单了。

计算置信度损失时,引入了负样本。
训练方式
原始YOLO网络使用固定的448 * 448的图片作为输入,加入anchor boxes后输入变成416 * 416,由于网络只用到了卷积层和池化层,就可以进行动态调整(检测任意大小图片)。为了让YOLOv2对不同尺寸图片的具有鲁棒性,在训练的时候也考虑了这一点。不同于固定网络输入图片尺寸的方法,每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小的尺寸为320 * 320,最大的尺寸为608 * 608。 调整网络到相应维度然后继续进行训练。这种机制使得网络可以更好地预测不同尺寸的图片,同一个网络可以进行不同分辨率的检测任务。
数据增广
SSD采用数据扩增(Data Augmentation)来提升性能,主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本)。

【参考文献】
https://zhuanlan.zhihu.com/p/33544892
https://zhuanlan.zhihu.com/p/35325884
https://zhuanlan.zhihu.com/p/25052190
https://blog.csdn.net/xiaohu2022/article/details/80666655