自制Java虚拟机(三)运行第一个main函数
自制Java虚拟机(三)运行第一个main函数
一、执行指令的一般模型
Java虚拟机有200多条指令,用switch-case来一一匹配并执行每个指令,显得过于臃肿又不灵活。我们可以把每个指令用一个函数实现,遇到指令就调用相应的函数处理之。这个函数应该知道它所处理指令的上下文,包括当前指令位置、当前类、当前帧等,这些我们都封装在一个结构体内,通过指针传给函数。函数太多,我们把它们组织到一个数组里,以opcode的数值作为索引,因为除最后2条指令外,前203条指令都是连续的。目前为了方便调试,把处理指令的函数又放到了结构体内。如下:
typedef void Opreturn;
typedef Opreturn (*InstructionFun)(OPENV *env); // 处理指令的函数原型(这里定义一个函数指针)
typedef struct _Instruction {
const char *code_name; // 该条指令opcode的助记符
InstructionFun pre_action; // 预处理代码(主要是大端转小端)
InstructionFun action; // 实际的指令实现
} Instruction;OPENV是指令上下文,定义为:
typedef uchar* PC;
typedef struct _OPENV {
PC pc; // 传说中的程序计数器,这里实际上是指向代码的当前执行位置
PC pc_end;
PC pc_start;
StackFrame *current_stack;
Class *current_class;
Object *current_obj;
method_info* method;
} OPENV;至少需要pc(保存当前代码指针位置)、current_stack(当前帧/栈帧)和current_class(当前类)等字段,其它字段方便调试用。
把指令处理相关的函数放在数组里:
Instruction jvm_instructions[202] = { // 暂不考虑保留指令
{"nop", pre_nop, do_nop},
{"aconst_nul", pre_aconst_nul, do_aconst_nul},
{"iconst_m1", pre_iconst_m1, do_iconst_m1},
{"iconst_0", pre_iconst_0, do_iconst_0},
...
{"jsr_w", pre_jsr_w, do_jsr_w}
}; 这些都很有规律,可以写个脚本来生成。
然后就是执行一个方法里面的代码了,大致如下:
void runMethod(OPENV *env)
{
uchar op;
Instruction instruction;
do {
op = *(env->pc); // 取指令的opcode
instruction = jvm_instructions[op]; // 取对应的实现函数
printf("#%d: %s ", env->pc-env->pc_start, instruction.code_name);
env->pc=env->pc+1; // 移到下个位置(可能是该条指令的操作码,也可能是下一条指令)
instruction.action(env); // 执行指令
printf("\n");
} while(1);
}跟现实世界CPU的执行指令的流程有点像。这是个死循环,不过不用担心,在return系列指令的实现里自有办法处理。
二、执行main方法
一个Java程序的入口是main方法。我们先从执行简单的main方法开始,找找成就感。在这个main方法里我们不创建对象,也不涉及到方法调用,类变量、实例变量等,因而只需要实现简单的指令即可。
1. 寻找main方法
首先我们要找到main方法,可以从我们解析出来的Class结果的methods数组中查找。
Class的结构(有省略):
typedef struct _ClassFile{
uint magic;
...
ushort constant_pool_count;
cp_info constant_pool;
...
ushort methods_count;
method_info **methods;
...
} ClassFile;
typedef ClassFile Class;查找main方法:
method_info* findMainMethod(Class *pclass)
{
ushort index=0;
while(index < pclass->methods_count) {
if(IS_MAIN_METHOD(pclass, pclass->methods[index])){
break;
}
index++;
}
if (index == pclass->methods_count) {
return NULL;
}
return pclass->methods[index];
}相关的宏定义如下:
#define get_utf8(pool) ((CONSTANT_Utf8_info*)(pool))->bytes
#define IS_MAIN_METHOD(pclass, method) (strcmp(get_utf8(pclass->constant_pool[method->name_index]), "main") == 0)2. 执行main方法
void runMainMethod(Class *pclass)
{
StackFrame* mainStack;
OPENV mainEnv;
method_info *mainMethod;
Code_attribute* mainCode_attr;
// 1. find main method
mainMethod = findMainMethod(pclass);
if (NULL == mainMethod) {
printf("Error: cannot find main method!\n");
exit(1);
}
// 2. find the code and create a frame
mainCode_attr = (Code_attribute*)(mainMethod->code_attribute_addr);
mainStack = newStackFrame(NULL, mainCode_attr);
// 3. set the opcode executation environment
mainEnv.current_class = pclass;
mainEnv.current_stack = mainStack;
mainEnv.pc = mainCode_attr->code;
mainEnv.pc_end = mainCode_attr->code + mainCode_attr->code_length;
mainEnv.pc_start = mainCode_attr->code;
mainEnv.method = mainMethod;
// 4. run main method
runMethod(&mainEnv);
}主要做了以下几步:
- 找到main方法,如果没有则退出
- 初始化一个帧/栈帧
- 设置opcode的执行环境
- 执行main方法
三、小试牛刀,实现指令
执行指令、main方法的流程是定下来了,可是指令的实际操作并没有实现。这个艰巨的任务就在本节来完成。java虚拟机定义的指令那么多,逐个实现显得过于刻板,耗时费力又让人看不到希望。我们先写个小程序:求1~100的整数的平均值,实现这个程序里面的指令即可。
Average.java:
package test;
public class Average{
public static void main(String[] args) {
double avg;
int n = 100;
int sum = 0;
for (int i=1; i<=n; i++) {
sum += i;
}
avg = (double)(sum)/n;
}
}编译成class文件,用javap反编译,同时对比我们自己程序的结果,看解析的class文件对不对,还好是对的。
Average.class的常量池长这样:
Constant pool:
#1 = Methodref #3.#14 // java/lang/Object."":()V
#2 = Class #15 // test/Average
#3 = Class #16 // java/lang/Object
#4 = Utf8
#5 = Utf8 ()V
#6 = Utf8 Code
#7 = Utf8 LineNumberTable
#8 = Utf8 main
#9 = Utf8 ([Ljava/lang/String;)V
#10 = Utf8 StackMapTable
#11 = Class #17 // "[Ljava/lang/String;"
#12 = Utf8 SourceFile
#13 = Utf8 Average.java
#14 = NameAndType #4:#5 // "":()V
#15 = Utf8 test/Average
#16 = Utf8 java/lang/Object
#17 = Utf8 [Ljava/lang/String; 生成的main方法的指令如下(除去前两行,/ / 后面是注释):
Code:
stack=4, locals=6, args_size=1
0: bipush 100 // 把一个字节的数push到操作数栈,这个100是直接跟着bipush这个opcode的
2: istore_3 // 把当前操作数栈顶的整数保存到索引为3的int型局部变量中,对应 int n=100
3: iconst_0 // 把整数常量0 push到操作数栈
4: istore 4 // 把当前操作数栈顶的整数保存到索引为4的int型局部变量中,对应 int sum=0
6: iconst_1 // 把整数常量1 push到操作数栈
7: istore 5 // 把当前操作数栈顶的整数保存到索引为5的int型局部变量中,对应 int i=1
9: iload 5 // 把索引为5的int类型局部变量push到操作数栈,即刚才的 i
11: iload_3 // 把索引为3的int类型局部变量push到操作数栈,即 n
12: if_icmpgt 28 // 对两个int类型执行比较,如果 i>n 则跳转到偏移为28的指令处执行
15: iload 4 // 把索引为4的int型局部变量push到操作数栈,即 sum
17: iload 5 // 把索引为5的int型局部变量push到操作数栈,即 i
19: iadd // 两个int类型的数相加, sum + i,两个操作数出栈,结果入栈
20: istore 4 // 把当前操作数栈顶的整数保存到 sum 中
22: iinc 5, 1 // 把索引为5的局部变量加1并保存
25: goto 9 // 跳转到偏移为9的指令
28: iload 4 // 把索引为4的int型变量push到操作数栈,即 sum
30: i2d // int -> double,对应 (double)(sum)
31: iload_3 // 把索引为3的int型变量push到操作数栈,即 n
32: i2d // int -> double,这是编译器自动添加的类型转换
33: ddiv // 两个double类型的数相除, sum/n,两个操作数出栈,结果入栈
34: dstore_1 // 把栈顶的double型的数保存到索引为1的局部变量,即 赋值给 avg
35: return // 指令执行完毕,返回(没有返回值)每一行的指令采用如下格式表示:
index: opcode [operand1[,operand2]]
其中,index表示该行指令的opcode在当前method代码中的偏移量(单位是字节),opcode是操作码的助记符,operand1, operand2表示该opcode的操作数。如 2: istore 3,表示该行指令的opcode偏移量为2各字节,opcode为istore,这条指令的功能是把当前操作数栈顶的一个整数弹出,并保存到索引为3的局部变量中)。
掐指一算,去除重复的指令,还是有十几条。这是个艰难的过程,一步一步往前走。
bipush指令:
Opreturn do_bipush(OPENV *env)
{
PUSH_STACK(env->current_stack,TO_BYTE(env->pc), int);
INC_PC(env->pc);
}取值,转换,入栈,pc加1。由于这个字节是有符号的,所以安全起见,转换一下。
iconst_0和iconst_1指令:
Opreturn do_iconst_0(OPENV *env)
{
PUSH_STACK(env->current_stack, 0, int);
}
Opreturn do_iconst_1(OPENV *env)
{
PUSH_STACK(env->current_stack, 1, int);
RETURNV;
}除nop指令外最简单的指令。
istore系列指令和dstore指令:
Opreturn do_istore(OPENV *env)
{
int i = (int)(TO_CHAR(env->pc));
ISTORE(env, i);
INC_PC(env->pc);
}
Opreturn do_istore_3(OPENV *env)
{
ISTORE(env, 3);
}
Opreturn do_dstore(OPENV *env)
{
int i = (int)(TO_CHAR(env->pc));
DSTORE(env, i);
INC_PC(env->pc);
}其中ISTORE是一个宏,定义如下:
#define XSTORE(env, index, xtype) PUT_LOCAL(env->current_stack, index, PICK_STACK(env->current_stack, xtype), xtype);\
POP_STACK(env->current_stack)
#define ISTORE(env, index) XSTORE(env, index, int)DSTORE宏的定义:
#define XSTOREL(env, index, xtype) PUT_LOCAL(env->current_stack, index, PICK_STACKL(env->current_stack, xtype), xtype);\
POP_STACKL(env->current_stack)
#define DSTORE(env, index) XSTOREL(env, index, double)都是先根据需要操作的字节数定义一般的宏,然后定义具体的宏。
iload系列指令:
Opreturn do_iload(OPENV *env)
{
ushort index = (ushort)(TO_CHAR(env->pc));
ILOAD(env, index);
INC_PC(env->pc);
}
Opreturn do_iload_3(OPENV *env)
{
ILOAD(env, 3);
}ILOAD也被定义成一个宏:
#define XLOAD(env, index, xtype) PUSH_STACK(env->current_stack, GET_LOCAL(env->current_stack, index, xtype), xtype)
#define ILOAD(env, index) XLOAD(env, index, int)与STORE系列的类似
icmpgt指令:
Opreturn do_if_icmpgt(OPENV *env)
{
ICMPGT(env);
}ICMPGT是个宏,定义如下:
#define ICMPXEQ(env, OP) short offset;\
int v1,v2;\
GET_STACK(env->current_stack, v2, int);\
GET_STACK(env->current_stack, v1, int);\
DEBUG_SP_DOWNL(env->dbg);\
if (v1 OP v2) {\
offset = TO_SHORT(env->pc);\
env->pc+=(offset-1);\
} else {\
INC2_PC(env->pc);\
}
#define ICMPGT(env) ICMPXEQ(env, >)因为jvm里面还有一系列类似的指令,只是算符不同而已,所以定义了个一般的宏。另一个相似的指令icmpeq,可定义如下:#define ICMPEQ(env) ICMPXEQ(env, ==)。
iadd和ddiv指令:
Opreturn do_iadd(OPENV *env)
{
IADD(env);
}
Opreturn do_ddiv(OPENV *env)
{
DDIV(env);
}它们都有几个相关的宏:
#define XOP(env, xtype, OP) SP_DOWNL(env->current_stack);\
PUSH_STACK(env->current_stack,(PICK_STACKC(env->current_stack, xtype) OP PICK_STACKU(env->current_stack, xtype)), xtype)
#define XOPL(env, xtype, OP) SP_DOWNDL(env->current_stack);\
PUSH_STACKL(env->current_stack,(PICK_STACKC(env->current_stack, xtype) OP PICK_STACKUL(env->current_stack, xtype)), xtype)
#define IADD(env) XOP(env, int, +)
#define DDIV(env) XOPL(env, double, /)先是定义了一般的宏,XOP表示针对4字节的算术操作,如int、float类型,XOPL是针对8字节数的算术操作,如double、long类型。然后根据操作数类型(int、double)和算符(+、-)定义了具体的宏。这样其它指令也可以很方便实现,如:两个float类型数相加的fadd指令可这样定义:#define FADD(env) XOP(env,float, +)
iinc指令:
Opreturn do_iinc(OPENV *env)
{
IINC(env);
}也是一个宏:
#define IINC(env) GET_LOCAL(env->current_stack, TO_CHAR(env->pc), int)+=(TO_CHAR(env->pc+1));\
env->pc+=2取值,相加,pc往后移2个字节。
goto:
Opreturn do_goto(OPENV *env)
{
short offset = TO_SHORT(env->pc);
env->pc+=(offset-1);
}就是更改pc的值,跟汇编类似。
i2d:
Opreturn do_i2d(OPENV *env)
{
I2D(env);
}类型转换而已。
return
Opreturn do_return(OPENV *env)
{
exit(0);
}简单起见,这个指令啥也不干,退出。
其它没有实现的指令,留个空函数占位,反正执行不到。
四、测试
测试代码:
int main()
{
Class *pclass = loadClass("Average.class");
runMainMethod(pclass);
return 0;
}由于我们的虚拟机没有实现native方法调用(需要加载动态链接库,然后调用里面的函数。jre8/bin目录下有很多动态链接库),我们不能用System.out.print之类的方法来打印程序执行的结果(System.out.print最终会执行一个native方法,这是由C实现的方法,由虚拟机调用)。为方便调试,只得自己在相关代码后面插入一些调试代码,打印相关内容。
执行结果如下(100个循环,输出的调试内容太多了,只截取最后几条指令的):
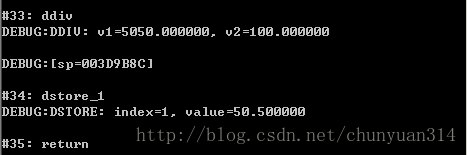
OK。
五、总结
本节中,探索了虚拟机执行指令执行的一般模型,以及执行main方法的流程,还实现了十几条指令(iload、iconst_0、istore、iadd、icmpgt、goto等),执行了一个求平均值的方法,里面有个for循环,还好,结果是对的。