Rook 笔记
1.rook基本概念
基本概念解析:云原生存储编排管理器。
基本概念详解:rook通过一个操作器(operator)完成后续操作,只需要定义需要状态就行了。Rook通过监视器监控状态变化,并将配置文件分配到集群上生效。传统意义上的集群管理员必须掌握和监控系统,而Rook存储运行则完全自动化。rook存储是通过第三方资源以kubernetes扩展形式运行。
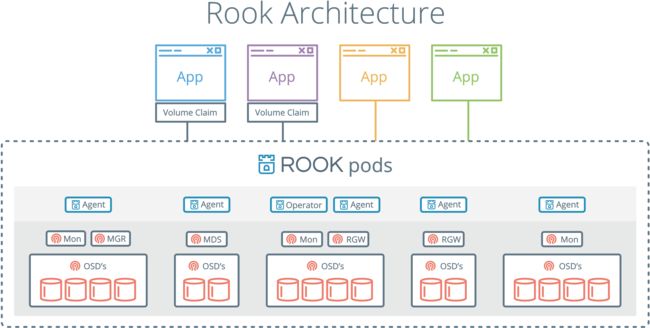
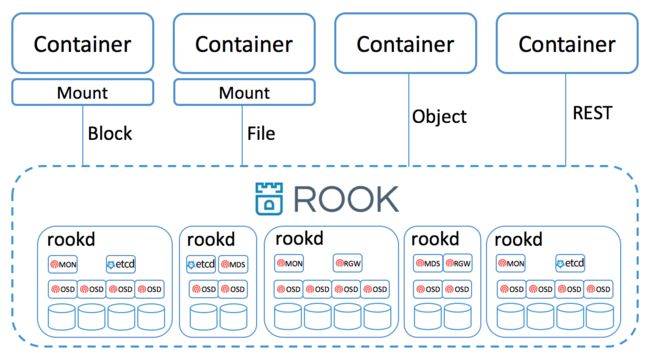
2.rook基本组件:
rook operator: 是一个简单的容器,具有引导和监视存储集群的功能,供提供最基本的RADOS存储。管理CRD,对象存储,文件系统。
Rook agent: 这些代理是在每个Kubernetes节点上部署的pod。每个代理都配置一个Flexvolume插件,该插件与Kubernetes的卷控制器框架集成在一起。处理节点上所需的所有存储操作,例如附加网络存储设备,安装卷和格式化文件系统。
Discover: 定期节点发现新设备3.rook实现原理描述:
rook 是基于FelixVolume存储插件机制实现。
4.启动流程
5.rook 控制流
1.rook operator运行,并在每台机器上运行一个rook agent的pod
2.创建一个pvc,并指定storageclass使用rook.io/block provisionor
3.operator provisionr 的provision()函数被调用,用以在集群中创建block image。此时,Provision阶段已完成,pvc/pv被考虑绑定到一起;
4.当使用pvc的pod被创建时,kubelete将调用 rook Felexxvolume的mount函数,用于使用预定存储;
5. 随后,agent将会按照CRD的描述创建一个volume并attach到该物理机上;
6.agent将volume map到本地机器上,并更新CRD的状态以及设备的路径值(例如/dev/rbd0)
7.控制权接着转交给driver,如果mapping能够成功执行,则driver将把指定的设备mount到指定的路径上。若在配置文件中还指明了文件系统的类型,则driver还会对该卷进行文件系统格式化操作。
8.driver将反馈kubelet Mount()操作已成功 6.创建rook,实验环境可以使用:play-with-k8s
# 说在前面的重点,删除重建operator,cluster时,要删除/var/lib/rook.
cd cluster/examples/kubernetes/ceph
kubectl create -f operator.yaml
#主要是一些自定义资源对象的定义CRD有:Cluster、Filesystem、ObjectStore、Pool、Volume;还创建了rook的三种组件Operator、Agent、Discover。
kubectl create -f cluster.yaml
#cluster.yaml中主要创建了一个Cluster(ceph集群)自定义资源对象(CR)
#如果出现如下报错,请参考如下
解决方案参考1:
配置operator.yaml,需要和kubelet的--volume-plugin-dir参数中的保持一致
vim operator.yaml
- name: FLEXVOLUME_DIR_PATH
value: "/usr/libexec/kubernetes/kubelet-plugins/volume/exec"
解决方案参考2
exit status 2. rbd: error opening pool 'replicapool': (2) No such file or directory -- 这个报错,我有遇到类似的问题,解决方法:在 rook-operator.yml 里添加
env:
- name: FLEXVOLUME_DIR_PATH
value: "/var/lib/kubelet/volumeplugins"
确保与kubelet 的--volume-plugin-dir一样。重新apply.重启kubelet.把rook-agent 和 rook-operator的pod删除,自动重建后等10分钟我的报错就消失了。
--volume-plugin-dir=/var/lib/kubelet/volumeplugins7.清理rook
- 清理命名空间rook-system,其中包含rook Operator和rook agent
- 清理名称空间rook,其中包含rook存储集群(集群CRD)
- 各节点的/var/lib/rook目录,ceph mons和osds的配置都缓存于此
kubectl delete -n rook pool replicapool
kubectl delete storageclass rook-block
kubectl delete -n kube-system secret rook-admin
kubectl delete -f kube-registry.yaml
# 删除Cluster CRD
kubectl delete -n rook cluster rook
# 当Cluster CRD被删除后,删除Rook Operator和Agent
kubectl delete thirdpartyresources cluster.rook.io pool.rook.io objectstore.rook.io filesystem.rook.io volumeattachment.rook.io # ignore errors if on K8s 1.7+
kubectl delete crd clusters.rook.io pools.rook.io objectstores.rook.io filesystems.rook.io volumeattachments.rook.io # ignore errors if on K8s 1.5 and 1.6
kubectl delete -n rook-system daemonset rook-agent
kubectl delete -f rook-operator.yaml
kubectl delete clusterroles rook-agent
kubectl delete clusterrolebindings rook-agent
# 删除名字空间
kubectl delete namespace rook8.rook 常用命令解析:
cluster.yaml
apiVersion: rook.io/v1alpha1
kind: Cluster
metadata:
name: rook
namespace: rook
spec:
# 存储后端,支持Ceph,NFS等等
backend: ceph
# 配置文件在宿主机的存放目录
dataDirHostPath: /var/lib/rook
# 如果设置为true则使用宿主机的网络,而非容器的SDN(软件定义网络)
hostNetwork: false
# 启动mon的数量,必须奇数,1-9之间
monCount: 3
# 控制Rook的各种服务如何被K8S调度
placement:
# 总体规则,具体服务(api, mgr, mon, osd)的规则覆盖总体规则
all:
# Rook的Pod能够被调用到什么节点上(根据pod标签来说)
nodeAffinity:
# 硬限制 配置变更后已经运行的Pod不被影响
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
# 节点必须具有role=storage-node
- matchExpressions:
- key: role
operator: In
values:
- storage-node
# Rook能够调用到运行了怎样的其它Pod的拓扑域上(根据node容忍度来说)
podAffinity:
podAntiAffinity:
# 可以容忍具有哪些taint的节点
tolerations:
- key: storage-node
operator: Exists
api:
nodeAffinity:
podAffinity:
podAntiAffinity:
tolerations:
mgr:
nodeAffinity:
podAffinity:
podAntiAffinity:
tolerations:
mon:
nodeAffinity:
tolerations:
osd:
nodeAffinity:
podAffinity:
podAntiAffinity:
tolerations:
# 配置各种服务的资源需求
resources:
api:
limits:
cpu: "500m"
memory: "1024Mi"
requests:
cpu: "500m"
memory: "1024Mi"
mgr:
mon:
osd:
# 集群级别的存储配置,每个节点都可以覆盖
storage:
# 是否所有节点都用于存储。如果指定nodes配置,则必须设置为false
useAllNodes: true
# 是否在节点上发现的所有设备,都自动的被OSD消费
useAllDevices: false
# 正则式,指定哪些设备可以被OSD消费,示例:
# sdb 仅仅使用设备/dev/sdb
# ^sd. 使用所有/dev/sd*设备
# ^sd[a-d] 使用sda sdb sdc sdd
# 可以指定裸设备,Rook会自动分区但不挂载
deviceFilter: ^vd[b-c]
# 每个节点上用于存储OSD元数据的设备。使用低读取延迟的设备,例如SSD/NVMe存储元数据可以提升性能
metadataDevice:
# 集群的位置信息,例如Region或数据中心,被直接传递给Ceph CRUSH map
location:
# OSD的存储格式的配置信息
storeConfig:
# 可选filestore或bluestore,默认后者,它是Ceph的一个新的存储引擎
# bluestore直接管理裸设备,抛弃了ext4/xfs等本地文件系统。在用户态下使用Linux AIO直接对裸设备IO
storeType: bluestore
# bluestore数据库容量 正常尺寸的磁盘可以去掉此参数,例如100GB+
databaseSizeMB: 1024
# filestore日志容量 正常尺寸的磁盘可以去掉此参数,例如20GB+
journalSizeMB: 1024
# 用于存储的节点目录。在一个物理设备上使用两个目录,会对性能有负面影响
directories:
- path: /rook/storage-dir
# 可以针对每个节点进行配置
nodes:
# 节点A的配置
- name: "172.17.4.101"
directories:
- path: "/rook/storage-dir"
resources:
limits:
cpu: "500m"
memory: "1024Mi"
requests:
cpu: "500m"
memory: "1024Mi"
# 节点B的配置
- name: "172.17.4.201"
- name: "sdb"
- name: "sdc"
storeConfig:
storeType: bluestore
- name: "172.17.4.301"
deviceFilter: "^sd."pool.yaml
apiVersion: rook.io/v1alpha1
kind: Pool
metadata:
name: ecpool
namespace: rook
spec:
# 存储池中的每份数据是否是复制的
replicated:
# 副本的份数
size: 3
# Ceph的Erasure-coded存储池消耗更少的存储空间,必须禁用replicated
erasureCoded:
# 每个对象的数据块数量
dataChunks: 2
# 每个对象的代码块数量
codingChunks: 1
crushRoot: default
objectStore
apiVersion: rook.io/v1alpha1
kind: ObjectStore
metadata:
name: my-store
namespace: rook
spec:
# 元数据池,仅支持replication
metadataPool:
replicated:
size: 3
# 数据池,支持replication或erasure codin
dataPool:
erasureCoded:
dataChunks: 2
codingChunks: 1
# RGW守护程序设置
gateway:
# 支持S3
type: s3
# 指向K8S的secret,包含数字证书信息
sslCertificateRef:
# RGW Pod和服务监听的端口
port: 80
securePort:
# 为此对象存储提供负载均衡的RGW Pod数量
instances: 1
# 是否在所有节点上启动RGW。如果为false则必须设置instances
allNodes: false
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- rgw-node
tolerations:
- key: rgw-node
operator: Exists
podAffinity:
podAntiAffinity:
resources:
limits:
cpu: "500m"
memory: "1024Mi"
requests:
cpu: "500m"
memory: "1024Mi"filesystem
apiVersion: rook.io/v1alpha1
kind: Filesystem
metadata:
name: myfs
namespace: rook
spec:
# 元数据池
metadataPool:
replicated:
size: 3
# 数据池
dataPools:
- erasureCoded:
dataChunks: 2
codingChunks: 1
# MDS守护程序的设置
metadataServer:
# MDS活动实例数量
activeCount: 1
# 如果设置为true,则额外的MDS实例处于主动Standby状态,维持文件系统元数据的热缓存
# 如果设置为false,则额外MDS实例处于被动Standby状态
activeStandby: true
placement:
resources:9.PV和PVC知识点补充
-
PV访问方式:
ReadWriteOnce – 被单个节点mount为读写rw模式 RWO ReadOnlyMany – 被多个节点mount为只读ro模式 ROX ReadWriteMany – 被多个节点mount为读写rw模式 RWX -
pv回收机制:
Retain – 手动重新使用 Recycle – 基本的删除操作 (“rm -rf /thevolume/*”) Delete – 关联的后端存储卷一起删除,后端存储例如AWS EBS, GCE PD或OpenStack Cinder -
volume的状态:
Available –闲置状态,没有被绑定到PVC Bound – 绑定到PVC Released – PVC被删掉,资源没有被在利用 Failed – 自动回收失败 CLI会显示绑定到PV的PVC名。
10.rook中节点作用补充
rook启动后各pod作用
mon:监控组件,负责监控ceph集群的状况。
mgr:manager组件,主要监控一些非paxos相关组件(比如pg相关统计信息),无状态组件。
收集可供prometheus指标
启动ceph dashboard
osd:osd组件,集群核心组件
mds: 元数据服务器。一或多个mds 协作管理文件系统的命名空间、协调到共享osd集群的访问。当在集群中声明要一个共享文件系统时,rook会:为cephfs创建matadata和数据池;创建文件系统;指定数量active-standby的mds实例。创建的文件系统会被集群中pod使用
rgw:为应用提供RESTful类型对象存储接口
1.为对象创建metada和数据池
2.启动rgw daemon
3.创建service为rgw damon提供一个负载均衡地址。11.rook管理集群继续操作
-
通过图形界面管理,部署dashboard
cd /rook/cluster/examples/kubernetes/ceph kubectl apply -f dashboard-external-http.yaml kubectl get svc -n rook-ceph #查看端口号 #通过浏览器访问 -
创建块存储storageclass
1.查看ceph数据盘文件类型 df -Th 2.根据ceph数据盘的文件系统类型修改fstype参数 vims torageclass.yaml fstype: xfs 3.创建storageclass kubectl create -f storageclass.yaml -
创建块使用实例
cd /rook/cluster/examples/kubernetes kubectl apply -f mysql.yaml kubectl apply -f wordpress.yaml -
创建共享文件系统
cd /rook/cluster/examples/kubernetes/ceph kubectl create -f filesystem.yaml kubectl get Filesystem -n rook-ceph共同探讨,一起思考。希望可以辅助大家理解!
参考资源:
基于rook的kubernetes方案
rook控制流
rook详解
rook-github