以太坊数据存储
更多关于区块链技术和投资的文章,请关注微信公众“币梭”
https://mp.weixin.qq.com/s/KShhtyuIpejE0VkOtUFMWA
区块查询
区块数据结构
数据结构基础
以太坊的树
状态树
交易树
收据树
区块查询
1、通过浏览器查询
https://etherscan.io/block

2、通过命令查询
浏览器查询虽然很方便,但是一些区块的信息没有显示出来。我们可以通过命令来查询
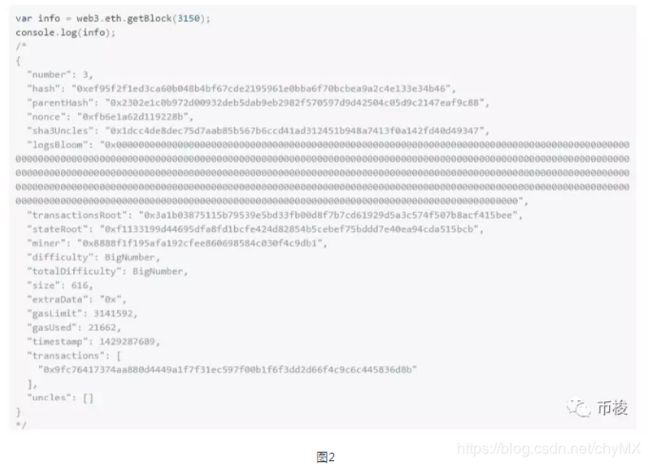
上面字段的含义:
number: Number - 块编号,当块处于pending状态时,值为null
hash: String, 32字节,块哈希,当块处于pending状态时,值为null
parentHash: String, 32字节,父块的哈希
nonce: String, 8字节,生成的POW哈希,块处于pending状态时,值为null
sha3Uncles: String, 32字节, 块中叔伯数据的SHA3值
logsBloom: String, 256字节,块中日志的bloom filter,当块处于pending状态时,值为null
transactionsRoot: String, 32字节,块交易树的根节点
stateRoot: String, 32字节,块最终状态树的根节点
miner: String, 20字节,接收挖矿奖励的矿工地址
difficulty: BigNumber , 块难度
totalDifficulty: BigNumber , 截止到本块的全链总难度
extraData: String ,块中的额外数据
size: Number,按字节计算的块大小
gasLimit: Number,本块允许的最大gas消耗量
gasUsed: Number ,块中所有交易使用的gas总量
timestamp: Number,块校验unix时间戳
transactions: Array,交易对象数组,或者是32字节的交易哈希值,取决于参数returnTransactionObjects的值
uncles: Array,叔伯块的哈希数组
区块数据结构
通过查询区块,对区块的信息略知一二。以太坊的区块是由去块头、交易列表和叔区块三部分组成。其中区块头包含块区号、块哈希、父块哈希等信息,其中State Root、Transaction Root、Receipt Root分别代表了状态树、交易树和交易树的哈希。除了创世块外,每个块都有父块,用Parent Hash连成一条区块链。如下图。
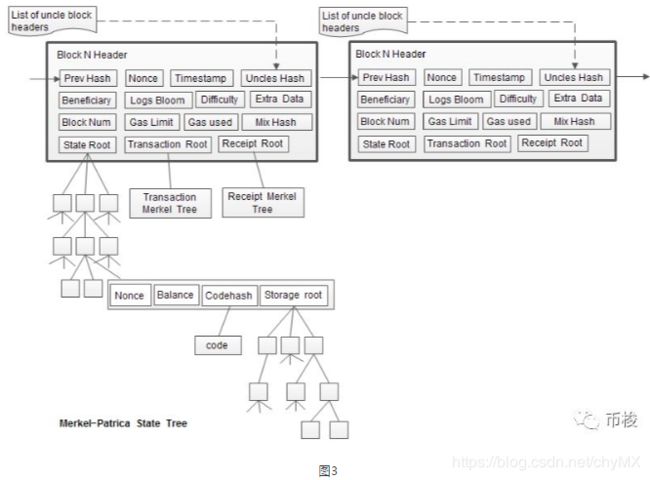
数据结构基础
1、Merkle 树
Merkle Tree,也叫做哈希树,顾名思义,就是存储hash值的一棵树。Merkle树的叶子是数据块的hash值。非叶节点是其对应子节点串联字符串的hash。是一个把任意长度的数据通过哈希函数映射成固定长度数据,这个数据就叫hash值,将这些hash值放到一个List里面,就叫做Hash List。Merkle Tree可以看做Hash List的泛化
1)Merkle Tree的原理
把数据分成小的数据块,每个数据块有相应地哈希,把相邻的两个哈希合并成一个字符串,然后运算这个字符串的哈希,得到了一个”子哈希“。如果哈希总数是单数,那么直接取最后一个哈希作为下个子哈希。这样就可以得到数目更少的新一级哈希。然后按照这种方式逐渐计算上去,最终必然形成一棵倒挂的树,到了树根的这个位置,就剩下一个根哈希了,我们把它叫做 Merkle Root。过程如图4
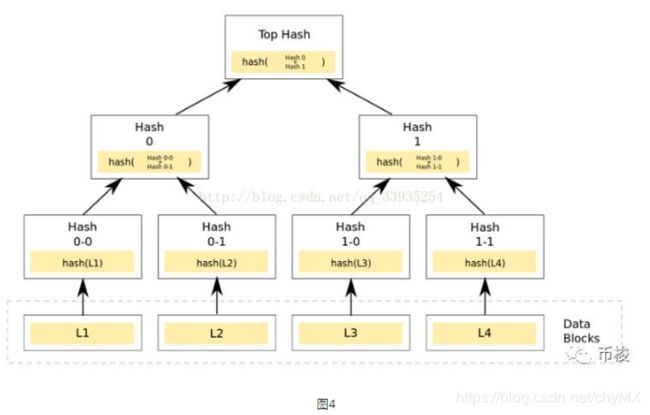
2)Merkel树的意义
在p2p网络,下载之前,先从可信的源获得文件的Merkle Tree树根。一旦获得了树根,就可以从其他从不可信的源获取Merkle tree。通过可信的树根来检查接受到的Merkle Tree。如果Merkle Tree是损坏的或者虚假的,就从其他源获得另一个Merkle Tree,直到获得一个与可信树根匹配的Merkle Tree。
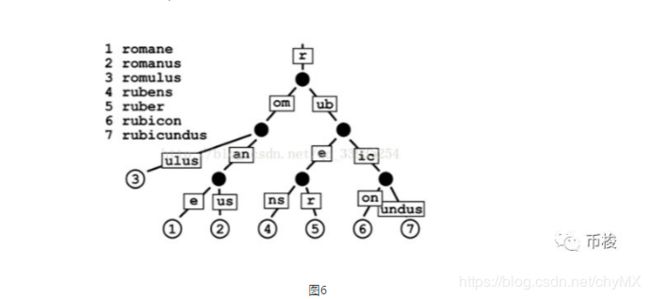
2、Trie 树
Trie树,又称前缀树或字典树。利用字符串的公共前缀来减少查询时间,最大限度的减少无谓的字符串比较,查询效率比哈希树高。典型应用是用于统计,排序和保存大量的字符串(不仅限于字符串),经常被搜索引擎系统用于文本词频统计。如图5
基本性质
1)根节点不包含字符,除根节点外的每一个子节点都包含一个字符
2)从根节点到某一节点。路径上经过的字符连接起来,就是该节点对应的字符串
3)每个节点的所有子节点包含的字符都不相同
注:键不需要被显式地保存在节点中。图示中标注出完整的单词,只是为了演示trie的原理

3、Patricia树
Patricia树,或称Patricia trie,压缩前缀树,是一种更节省空间的Trie。对于基数树的每个节点,如果该节点是唯一的儿子的话,就和父节点合并。
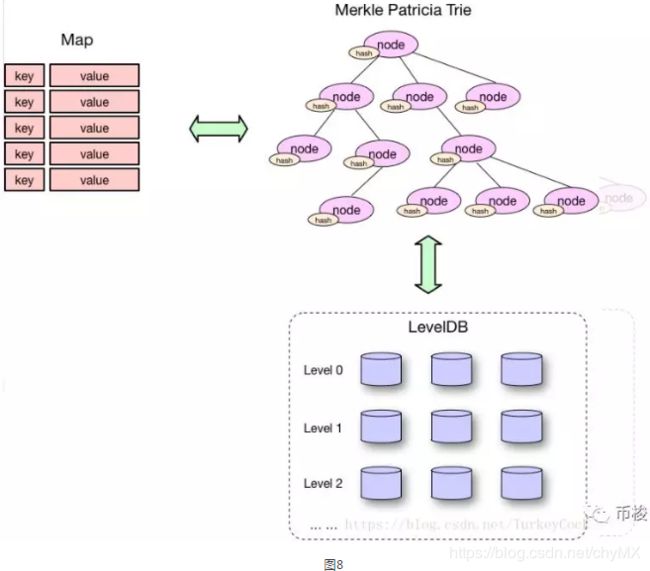
4、LevelDB数据库
以太坊的数据最终都是存储在LevelDB数据库中。LevelDB是Google实现一个非常高效的键值对数据库,其中键值都是二进制的,目前能够支持十亿级别的数据量,在这个数据量下还有着非常高的性能。以太坊中共有三个LevelDB数据库,分别是BlockDB、StateDB和ExtrasDB。BlockDB保存了块的主体内容,包括块头和交易;StateDB保存了账户的状态数据;ExtrasDB保存了收据信息和其他辅助信息。
以太坊的树
以太坊保存着三种树,分别为状态树,交易树和收据树。整个以太坊系统中只有一棵状态树,记录整个以太坊系统的所有账户状态。每个区块保存着一棵交易树,记录该区块的交易情况,一棵收据树用来记录该区块的交易收据。
状态树采用Merkel-Patrica(MPT)树,而交易树和状态树采用Merkel树。
对于交易树和收据树来说,一旦树已经建立,花多少时间来编辑这棵树并不重要,因为树一旦建立了,它就会永远存在并且不会改变。所以交易树和收据树采用Merkel树。
对于状态树,每个节点基本上包含了一个键值映射,其中的键是地址,而值包括账户的声明、余额、随机数nounce、代码以及每一个账户的存储。不同于交易历史记录,状态树需要经常地进行更新:账户余额和账户的随机数nonce经常会更变,更重要的是,新的账户会频繁地插入,存储的键也会经常被插入以及删除。我们需要这样的数据结构,它能在一次插入、更新、删除操作后快速计算到树根,而不需要重新计算整个树的Hash。Patricia树具有Trie树快速查找特点,并且比Trie树更加节省空间,所以以太坊中,对Merkel树改造成Merkel-Patrica(MPT)树。
状态树
状态树中有四种节点,分别是空节点、叶子节点、扩展节点和分支节点。
空节点,简单的表示空,在代码中是一个空串。
叶子节点(leaf),表示为[key,value]的一个键值对,其中key是key的一种特殊十六进制编码,value是value的RLP编码。
扩展节点(extension),也是[key,value]的一个键值对,但是这里的value是其他节点的hash值,这个hash可以被用来查询数据库中的节点。也就是说通过hash链接到其他节点。
分支节点(branch),因为MPT树中的key被编码成一种特殊的16进制的表示,再加上最后的value,所以分支节点是一个长度为17的list,前16个元素对应着key中的16个可能的十六进制字符,如果有一个[key,value]对在这个分支节点终止,最后一个元素代表一个值,即分支节点既可以搜索路径的终止也可以是路径的中间节点。
假如有四个账户,账户1地址0x811344,余额1ETH;账户2地址0x879337,余额2ETH;账户3地址0x8fd365,余额3ETH;账户4地址0x879397,余额4ETH,存储如下。

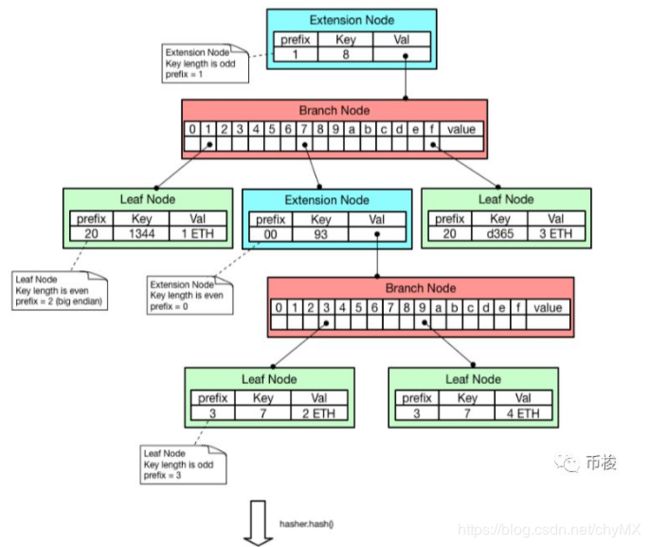

从图中可以看出,状态树的存储涉及3种编码方式:
-
KeyBytes编码
-
Hex编码
-
Compact编码
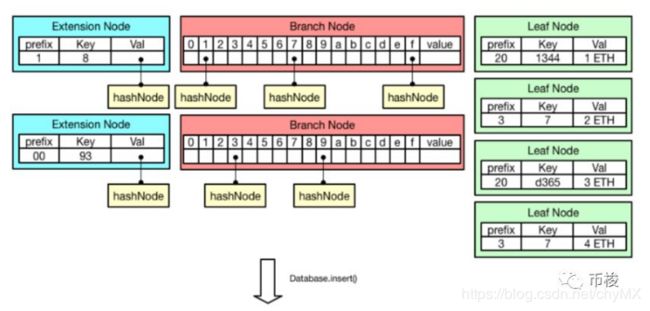
在完成Compact编码后,会通过折叠操作把子结点替换成子结点的hash值,然后以键值对的形式将所有结点存储到LevelDBA数据库中。下面详细介绍上面3中编码方式。
KeyBytes编码
即原始关键字,比如图中的0x811344、0x879337等。每个字节中包含2个nibble(半字节,4 bits),每个nibble的数值范围时0x0~0xF。
Hex编码
由于我们需要以nibble为单位进行编码并插入MPT,因此需要把一个字节拆分成两个,转换为Hex编码。
Compact编码
当我们需要把内存中MPT存储到数据库中时,还需要再把两个字节合并为一个字节进行存储,这时候会碰到2个问题:
-
关键字长度为奇数,有一个字节无法合并
-
需要区分结点是扩展结点还是叶子结点
为了解决这个问题,以太坊设计了一种Compact编码方式,具体规则如下:
-
扩展结点,关键字长度为偶数,前面加00前缀
-
扩展结点,关键字长度为奇数,前面加1前缀(前缀和第1个字节合并为一个字节)
-
叶子结点,关键字长度为偶数,前面加20前缀(因为是Big Endian)
-
叶子结点,关键字长度为奇数,前面加3前缀(前缀和第1个字节合并为一个字节)
StateDB的存储
StateDB中存储了很多stateObject,而每一个stateObject则代表了一个以太坊账户,包含了账户的地址、余额、nonce、合约代码hash等状态信息。所有账户的当前状态在以太坊中被称为“世界状态”,在每次挖出或者接收到新区块时需要更新世界状态。
为了能够快速检索和更新账户状态,StateDB采用了两级缓存机制,参见下图:
-
第一级缓存以map的形式存储stateObject
-
第二级缓存以MPT的形式存储
-
第三级就是LevelDB上的持久化存储
当上一级缓存中没有所需的数据时,会从下一级缓存或者数据库中进行加载。
交易树
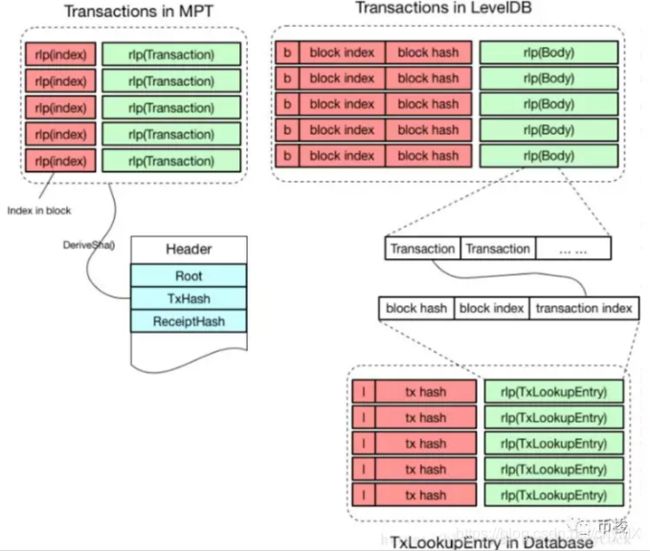
从图中可以看出,MPT是以交易在区块中的索引的RLP编码作为key,存储交易数据的RLP编码。事实上交易在LeveDB中并不是单独存储的,而是存储在区块的Body中。在往LeveDB中存储不同类型的键值对时,会在关键字中添加不同的前缀予以区分
因此,以b + block index + block hash作为关键字就可以唯一确定某个区块的Body所在的位置。另外,为了能够快速查询某笔交易的数据,在数据库中还存储了每笔交易的索引信息,称为TxLookupEntry。TxLookupEntry中包含了block index和block hash用于定位区块Body,同时还包含了该笔交易在区块Body中的索引位置。
收据树
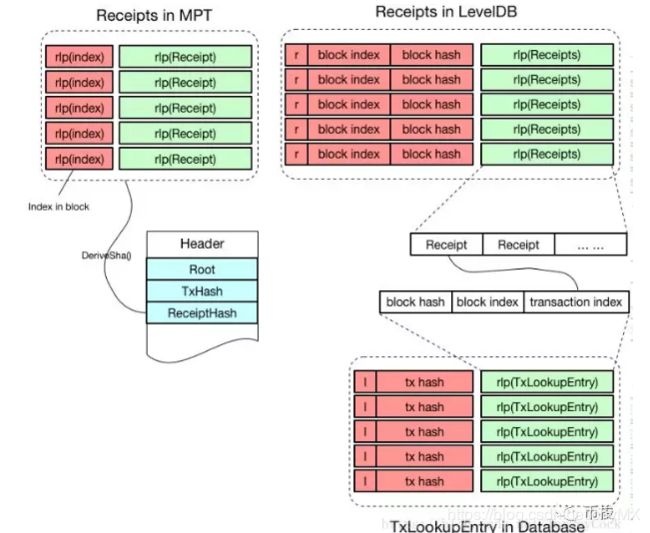
交易回执的存储和交易类似,区别是交易回执是单独存储到LevelDB中的,以r为前缀。另外,由于交易回执和交易是一一对应的,因此也可以通过TxLookupEntry快速定位交易回执所在的位置,加速交易回执的查找。
更多关于区块链技术和投资的文章,请关注微信公众“币梭”
