基于百度AI的云猫OCR开发实录之代码篇
一、概述
云猫OCR是基于百度AI,在Windows平台运行的一款软件。我是用C#语言在Visual Studio2017集成开发环境中进行开发的,开发方式是SDK包开发。在开发中,我们需要参考百度的技术文档。
百度云文字识别技术文档地址:https://cloud.baidu.com/doc/OCR/index.html

二、准备工作
首先,我们需要下载最新的百度文字识别的SDK包。
C# SDK包的下载地址如下:http://ai.baidu.com/sdk#ocr
下载完毕后解压缩,最新的包在文件夹net45里面。
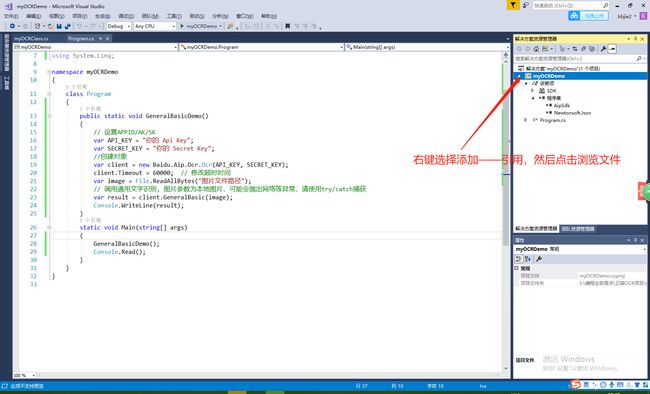
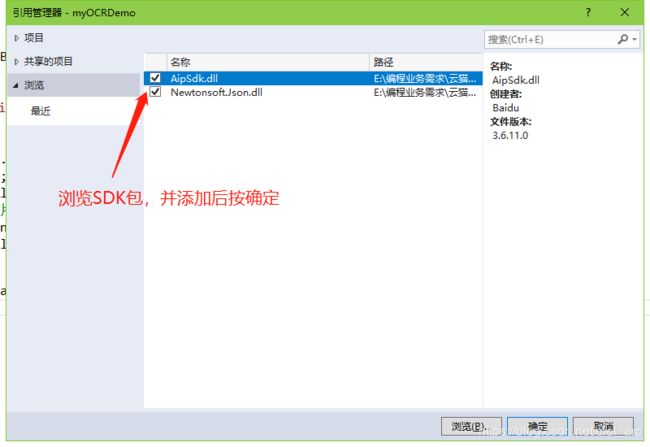
打开Visual Studio2017开发环境,选择新建项目,因为我打算用控制台项目讲解,因此要选择新建项目——C#控制台项目。建好项目之后,需要在项目中引用上面下载的SDK包。
三、核心代码讲解
(一)调用百度OCR函数识别图片文字,返回的格式为Json
代码如下:
using System;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using System.IO;
using System.Drawing;
using System.Collections.Generic;
using System.Linq;
namespace myOCRDemo
{
class Program
{
public static void GeneralBasicDemo()
{
// 设置APPID/AK/SK
var API_KEY = "你的 Api Key";
var SECRET_KEY = "你的 Secret Key";
//创建对象
var client = new Baidu.Aip.Ocr.Ocr(API_KEY, SECRET_KEY);
client.Timeout = 60000; // 修改超时时间
var image = File.ReadAllBytes("图片文件路径");
// 调用通用文字识别, 图片参数为本地图片,可能会抛出网络等异常,请使用try/catch捕获
var result = client.GeneralBasic(image);
Console.WriteLine(result);
}
static void Main(string[] args)
{
GeneralBasicDemo();
Console.Read();
}
}
}注意,具体开发的时候要把上面的API Key和Secret Key分别改为你自己的,至于怎么申请和查看这两个Key,可以参考我写的评测篇帖子。帖子链接如下:http://ai.baidu.com/forum/topic/show/955989
另外不要忘了把图片文件路径改为你自己的图片路径。下面是识别的结果示例:

原图如下:
(二)解析Json格式,把识别结果转变为更为直观的文本类型
代码如下:
using System;
using Newtonsoft.Json;
using Newtonsoft.Json.Linq;
using System.IO;
using System.Drawing;
using System.Collections.Generic;
using System.Linq;
namespace myOCRDemo
{
class Program
{
public static void GeneralBasicDemo()
{
// 设置APPID/AK/SK
var API_KEY = "你的Akey";
var SECRET_KEY = "你的SKey";
//创建对象
var client = new Baidu.Aip.Ocr.Ocr(API_KEY, SECRET_KEY);
client.Timeout = 60000; // 修改超时时间
var image = File.ReadAllBytes(@"你的图片路径");
// 调用通用文字识别, 图片参数为本地图片,可能会抛出网络等异常,请使用try/catch捕获
var result = client.GeneralBasic(image);
//解析Json的代码
JObject jo = (JObject)JsonConvert.DeserializeObject(result.ToString());
int num = (int)jo["words_result_num"];
string[] words = new string[num];
for (int i = 0; i < num; i++)
words[i] = jo["words_result"][i]["words"].ToString();
//返回值
string txtOCR = null;
for (int i = 0; i < num; i++)
txtOCR += words[i] + "\n";
//显示结果
Console.WriteLine(txtOCR);
}
static void Main(string[] args)
{
GeneralBasicDemo();
Console.Read();
}
}
}程序运行结果如下:

这样就比较符合人类的阅读习惯了,上面这段代码也是核心的基础代码,可以通过这些核心的代码去做一些优化,比如自动换行、自动缩进、根据语言习惯自动改变标点符号等等。
(三)表格识别
百度的表格文字识别的编程较为麻烦,主要分成两步:第一步是提交表格文字识别请求,获得requestId;第二步是根据requestId获取表格文字识别的结果,默认是Excel文件格式,Json结果会返回一段下载地址。
我的程序除了上面这两步以外,还添加了自动下载Excel文件到本地电脑的代码,供各位参考。另外要注意的是,提交识别请求和获得识别结果这两步之间,程序必须设置延时,否则不能获得下载的URL 。经过实际测试,延时为3秒较为合适,3秒以下可能会出错。
代码如下:
///
/// 表格文字识别
///
public static void myTableRecognitionRequestDemo()
{
// 设置APPID/AK/SK
var API_KEY = "你的API Key";
var SECRET_KEY = "你的Secret Key";
//创建对象
var client = new Baidu.Aip.Ocr.Ocr(API_KEY, SECRET_KEY);
client.Timeout = 60000; // 修改超时时间
var image = File.ReadAllBytes(@"F:\表格图片1.jpg");//这里要改成你的表格图片路径
// 调用表格文字识别,可能会抛出网络等异常,请使用try/catch捕获
var result = client.TableRecognitionRequest(image);
//解析Json
JObject jo = (JObject)JsonConvert.DeserializeObject(result.ToString());
string requestId = jo["result"][0]["request_id"].ToString();
Console.WriteLine("获得requestId:"+requestId);
//延时3秒,这句是必须的
System.Threading.Thread.Sleep(3000);
//获取表格识别结果
//有时会得不到链接,需要多尝试几次
var resultExcel = client.TableRecognitionGetResult(requestId);
Console.WriteLine("获得的表格识别结果如下:");
Console.WriteLine(resultExcel);
//解析Json,获得链接
JObject joResult = (JObject)JsonConvert.DeserializeObject(resultExcel.ToString());
string excelURL = joResult["result"]["result_data"].ToString();
Console.WriteLine("获得的Excel文件下载地址是:\n" + excelURL);
//自动下载Excel文件到电脑
WebClient df = new WebClient();
df.DownloadFile(excelURL, @"F:\识别结果.xls");//这里要改成你的下载文件路径
Console.WriteLine("下载完毕");
}作者使用的测试用图片:

表格文字识别结果截图:
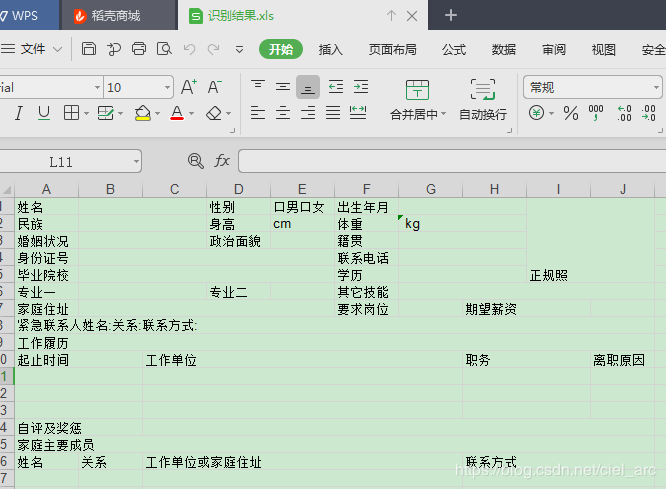
尾记:本文的示例代码都是最新的代码,跟百度SDK文档里面的代码是一致的,而云猫OCR是2017年末就已经写好的了,代码有些陈旧,所以没直接贴源代码了。希望各位看官踊跃讨论,本人水平也一般,大家多交流学习。
2019年9月11日